《分奖金》专题
-
Spring-分批流动/一步后分裂
那么,如何将作业配置为先运行单个步骤,然后并行运行多个步骤,然后运行最后一个步骤呢?
-
Elatticsearch部分,区分大小写匹配
我试图在Elasticseach 7中实现部分的、区分大小写的匹配。 我正在使用设置创建索引: 以及映射: 以下查询将正确返回文档: 但当我将搜索词小写时,它不会返回文档: 如何配置Elasticsearch,使其与使用小写搜索词的名称字段值匹配?
-
Spring data JpaRepository分页和分组依据
-
Jenkins多分支(管道)/分支跟踪
对于一个新项目,我想使用Jenkins CI的新管道功能。我们的Git存储库中有几个分支,应该以同样的方式进行测试。它还应该自动跟踪和处理新的分支。因此,我创建了一个多分支管道作业。但它的配置有两个问题: 1) 为了被Jenkins标记为有效,分行需要一个“Jenkinsfile”。如果这不存在,詹金斯将忽略该分支。有没有办法标记与模式匹配的所有分支,而不需要在其中包含此文件? 2) 每个分支都应
-
如何将框架分成两部分
这是为了俄罗斯方块。玻璃(蓝色)位于左侧,控制(红色面板)位于右侧。换句话说,现在我只想有一个框架分成两部分:左边(较宽)部分是蓝色,右边部分是红色。没别的了。但我似乎没能做到这一点。 所以,我的逻辑是:让框架有FlowLayout。然后,我添加了两个面板,这意味着它们将被放在一个行中。
-
kafka复制分区中的分区ID
我正在用单个主题和多个分区实现kafka producer。我通过消息中的一个特定值(消息json中的feedName属性值)选择消息到哪个分区。我正在为feedName-partitionId映射维护一个SQL表。我的问题是,leader和副本的分区Id是否相同?如果不同,如何在所有代理中唯一地标识分区?
-
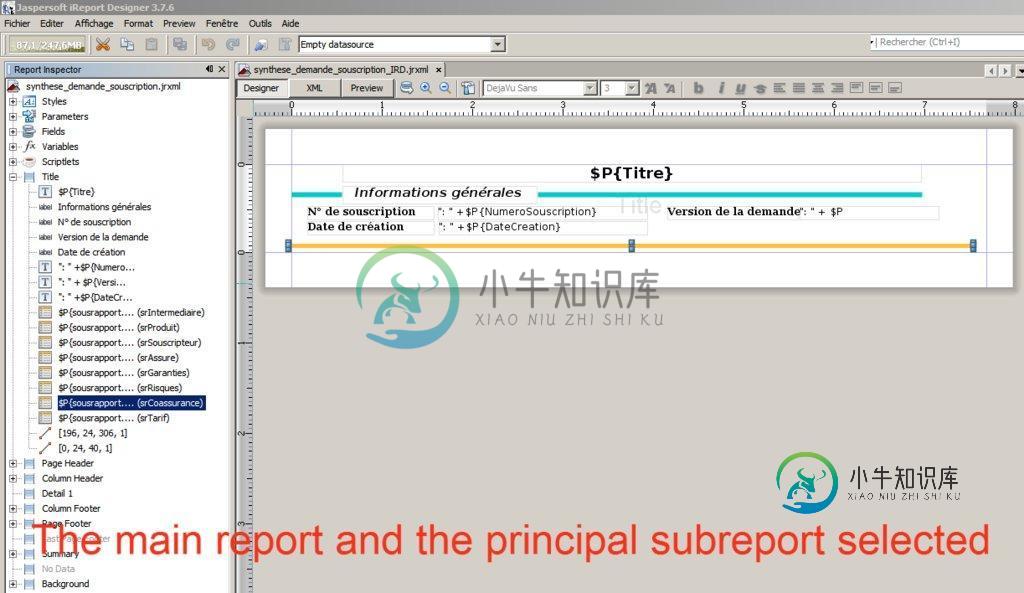 iReport子报表被分页符分隔
iReport子报表被分页符分隔子报告有两个细节带,第一个是“标题”,第二个是另一个子报告。这些乐队在两页纸上彼此分开。 我尝试了许多属性,但没有结果,如“忽略分页”和“允许拆分” 我的问题是:如何强制ireport不将子报表拆分到两页上?
-
在分裂重叠上分裂[拉库]
只是为了澄清事情,我知道正确的代码是: 但我的问题是关于“错误”代码的内部工作。拉库是怎么得出那个结果的?
-
Oracle拆分表列分隔值到行
需要帮助以下从测试中选择col1、col2、split(col3); 任何regex或PL/SQL函数的想法都可以帮助实现这一点。
-
内存分配/解除分配?[关闭]
-
在分解中分配选项 [重复]
我试图根据ES6重写以下代码。我不断收到ESLint警告,到目前为止,我已经花了大约20分钟在上面,我不太确定如何编写它。。。 上面的代码根本无法解析,但根据我的尝试,它说我不能在箭头函数中使用返回{}。 如果我尝试只修改参数,则会得到一个错误,即
-
Kafka流localstore分区分配不平衡
首先,很抱歉,如果我的术语不准确,我对Kafka很陌生,我已经尽可能多地读过了。我们有一个使用kafkastreams的服务,kafka版本:2.3.1。流应用程序具有一个流拓扑,该流拓扑从“topica”读取,执行转换并发布到另一个主题“topicb”,然后由拓扑的另一个流消费,并使用Ktable(localstore)聚合它。侦听器将ktable更改发布到另一个主题中。 主题有24个分区。我们
-
Fire议程在drools中分别分组
我们用的是Drools6。 有人能帮我吗? PS.:在“预取”组的规则中,我们有“插入”,这样它会导致规则再次被激发,我不希望这会导致“主规则”组的规则被激发。
-
处理:部分模糊部分背景
一些背景信息:这个项目是一个简单的图像,在项目结束时,它将成为我电脑屏幕的背景。 我想模糊背景的一部分,这样文本的一部分就更清晰了。我可以模糊图像中文本本身的部分,但这是我最后的选择。我不想这样做,因为在未来的项目中,我想随着一些东西的移动而主动模糊背景(我还没有开始这个未来的项目,所以我无法更好地描述这个项目)。 有人知道如何模糊背景的一部分吗?对于这个项目,它需要大约400x200像素,模糊1
-
分页查询场景分享列表
接口说明 分页查询场景分享列表 如需调用,请访问 开发者文档 来查看详细的接口使用说明 该接口仅开放给已获取SDK的开发者 API地址 GET /wish3dearth/api/scene/share/v1.0.0/pageList 是否需要登录 是 请求字段说明 参数 类型 请求类型 是否必须 说明 token string header 是 当前登录用户的TOKEN sceneId strin