《存储》专题
-
为什么选择语句存储过程中PostgreSQL抛出错误列不存在...?
我在PostgreSQL中有一个存储过程,我想在表中进行插入。我从这个过程中得到了一些参数,并使用它们尝试在其他表上选择其他属性。 这是我的存储过程: 当我试图执行时,它抛出一个错误,说:“错误:列“customer_code”不存在”,“提示:表“sales_invoice_header”中有一个名为“customer_code”的列,但不能从查询的这一部分引用它。” 表客户是存在的,有一个名为
-
无法使用Azure将文件上载到Azure Blob存储。存储Blobs NuGet套装
我正在尝试使用将示例文档文件上载到azure存储blob。NET核心(V3.1)控制台应用程序,使用C#。我正在Visual Studio 2019本地运行控制台应用程序。 我有过 第一步:创建一个。NET核心控制台应用程序 步骤2:创建一个名为"file"的Azure存储帐户和容器。 步骤3:在本地计算机中创建word/pdf文档。 步骤4:初始化存储连接字符串,容器名称,文件路径 步骤5:在控
-
操作系统中虚拟内存和缓存内存之间的区别
本文向大家介绍操作系统中虚拟内存和缓存内存之间的区别,包括了操作系统中虚拟内存和缓存内存之间的区别的使用技巧和注意事项,需要的朋友参考一下 在这篇文章中,我们将了解操作系统中虚拟内存和缓存内存之间的区别- 高速缓存存储器 它有助于提高CPU的访问速度。 它是提高访问速度的存储单元。 CPU和其他相关硬件有助于管理缓存。 尺寸很小。 它用于存储最近使用的数据。 虚拟内存 它增加了主存储器的容量。 这
-
内存上限?
问题内容: python的内存有限制吗?我一直在使用python脚本从最小150mb大的文件中计算平均值。 根据文件的大小,我有时会遇到一个。 可以为python分配更多的内存,这样我就不会遇到错误吗? 编辑:下面的代码 注意:文件大小可能相差很大(最大20GB),文件的最小大小为150mb 问题答案: (这是我的第三个答案,因为我误解了您的代码在原始代码中所做的事情,然后在第二个错误中犯了一个小
-
内存映射
系统调用在调用进程的虚拟地址空间中提供映射,将文件或设备映射到内存中。 下面是两种类型 - 文件映射或文件支持的映射 - 此映射将进程的虚拟内存区域映射到文件。 这意味着读取或写入这些内存区域会导致文件被读取或写入。这是默认的映射类型。 匿名映射 - 此映射映射进程的虚拟内存区域,不受任何文件的支持。 内容被初始化为零。 这种映射类似于动态内存分配(malloc()),在某些实现中用于某些分配。
-
 共享内存
共享内存共享内存是两个或多个进程共享的内存。 但是,为什么我们需要共享内存或其他通信方式呢? 重申一下,每个进程都有自己的地址空间,如果任何进程想要将自己的地址空间的某些信息与其他进程进行通信,那么只能通过IPC(进程间通信)技术进行。 我们已经知道,通信可以在相关或不相关的进程之间进行。 通常,使用管道或命名管道来执行相互关联的进程通信。 可以使用命名管道或通过共享内存和消息队列的常用IPC技术执行无关
-
Vim寄存器
Vim提供了许多寄存器。可以将这些寄存器用作多个剪贴板。使用多个文件时,此功能非常有用。在本章中,将讨论以下主题内容 - 复制寄存器中的文本 粘贴寄存器中的文本 列出可用的寄存器 寄存器类型 1. 复制寄存器中的文本 对于复制,可以使用普通的命令,即并将其存储在寄存器中,可以使用以下语法 - 例如,要复制寄存器中的文本,请使用以下命令 - 2. 粘贴寄存器中的文本 从寄存器粘贴文本 - 例如,下面
-
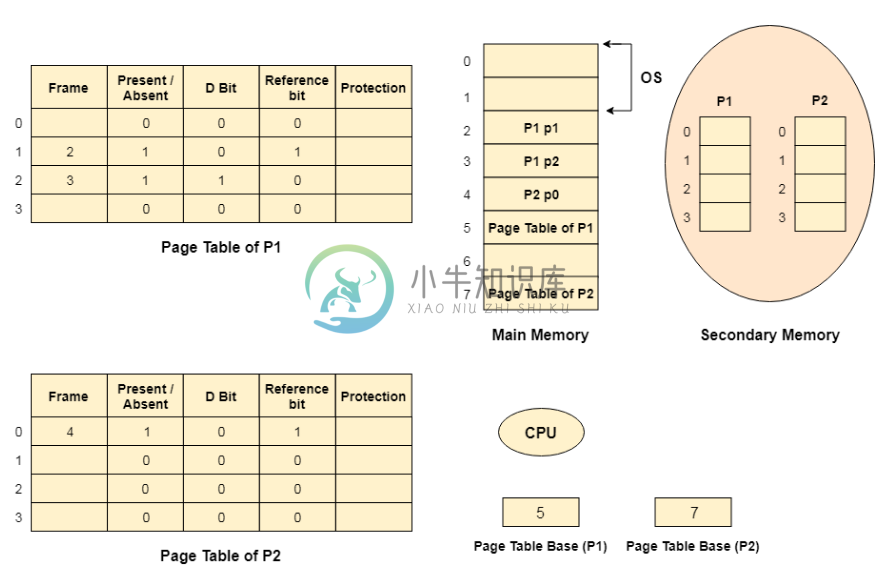 虚拟内存
虚拟内存主要内容:虚拟内存如何工作?,按需分页,虚拟内存管理系统的快照虚拟内存是一种存储方案,为用户提供了一个拥有非常大的主内存的幻觉。 这是通过将辅助存储器的一部分作为主存储器来完成的。 在这种方案中,用户可以加载比可用主存更大的进程,因为存在内存可用于加载进程的错觉。 操作系统不是在主内存中加载一个大进程,而是在主内存中加载多个进程的不同部分。 通过这样做,多程序的程度将会增加,因此CPU利用率也会增加。 虚拟内存如何工作? 在现代语言中,虚拟内存近来变得非常普
-
Figure的保存
要保存图形,从File菜单选择Save。要用图形格式如TIFF保存,以便在其他应用中使用,则从File菜单选择Export。还可以从命令行中保存-用saveas命令,包括任何以其他格式保存图象的选项。
-
11. Caching 缓存
Shiro 开发团队明白在许多应用程序中性能是至关重要的。Caching 是从第一天开始第一个建立在 Shiro 中的一流功能,以确保安全操作保持尽可能的快。 然而,Caching 作为一个概念是 Shiro 的基本组成部分,实现一个完整的缓存机制是安全框架核心能力之外的事情。为此,Shiro 的缓存支持基本上是一个抽象的(包装)API,它将“坐”在一个基本的缓存机制产品(例如,Ehcache,O
-
列不存在?
问题内容: 想知道是否有人可以通过此查询为我提供一些帮助: 我只想得到计数(已重命名)等于1的结果。此查询出现错误: 但是该列 应该 存在,对吗?有人可以协助吗?谢谢! 问题答案: 您不能在WHERE子句中引用列别名。 在传统SQL中,最早可以引用列别名的是子句。但是MySQL和SQL Server允许在and子句中进行访问。
-
C#内存流
我在使用SharpZipLib的GZipInputStream编写未压缩的GZIP流时遇到问题。我似乎只能获得256字节的数据,其余的数据没有写入并保留为零。已检查压缩流(compressedSection),所有数据都在那里(1500字节)。解压缩过程的片段如下: 因此,在这段代码中: 1) 压缩的部分被传入,准备解压缩。 2) 未压缩输出的预期大小(以2字节小endian值的形式存储在文件头中
-
@可缓存Spring3.1
我在Spring3.1中使用@Cacheable。我对Cacheable中的值和键映射参数有点混淆。以下是我正在做的: 这里发生的情况是,第二个方法依赖于第一个方法的选定值,但问题是假设当我传递zoneMastNo=1和areaMastNo=1时,第二个方法返回第一个方法结果。事实上,我有很多服务,因此,我希望使用公共值来缓存特定的用例。现在我的问题是: 我如何解决这个问题 对每个服务都使用cac
-
内存溢出?
JNIEXPORT jint JNICALL Java_nc_mes_pub_hardware_PCI1761_readChanel(JNIEnv*,jobject,jint channel){ }
-
内存不足
我正在努力解决古老的字谜问题。多亏了许多教程,我能够迭代一组字符串,递归地找到所有的排列,然后将它们与英语单词列表进行比较。我发现的问题是,在大约三个单词之后(通常是关于“变形”之类的东西),我会得到一个OutOfMemory错误。我试着把我的批分成小的集合,因为它似乎是消耗我所有内存的递归部分。但即使只是“变形”也把它锁起来了... 编辑:根据出色的反馈,我已经将生成器从排列更改为工作查找: 它