《欢聚集团》专题
-
八、无监督学习第二部分:聚类
聚类是根据一些预定义的相似性或距离(相异性)度量(例如欧氏距离),将样本收集到相似样本分组中的任务。 在本节中,我们将在一些人造和真实数据集上,探讨一些基本聚类任务。 以下是聚类算法的一些常见应用: 用于数据减少的压缩 将数据汇总为推荐系统的再处理步骤 相似性: 分组相关的网络新闻(例如 Google 新闻)和网络搜索结果 为投资组合管理分组相关股票报价 为市场分析建立客户档案 为无监督特征提取构
-
AngularJS:在一个输入中,当没有聚焦时如何显示“ $ 50,000.00”,而在聚焦时如何显示“ 50000”?
问题内容: 我有输入要显示格式化的数字。通常,当它没有焦点时,应该显示一个格式化的字符串,例如’$ 50,000.00’。但是当它具有焦点时,它应该显示原始值,例如用于编辑的50000。 有内置功能吗?谢谢! 问题答案: 这是一条指令(),它可以执行您想要的操作。 请注意,只有元素的显示值才被格式化(模型值将始终为未格式化)。 这个想法是您为和事件注册侦听器,并根据元素的焦点状态更新显示值。 另请
-
任何Java集合以比较数据集
问题内容: 我有2个月的2个数据集,包括学生的姓名和分数。 我需要提供每个学生的2月分数,以及他/她2月分数的变化百分比。 我可以使用Java集合吗? 样本数据集: 输出应该是这样的 (名称:约翰,2月分数:80,百分比变化:100) (名称:玛丽,2月的分数:81,百分比变化:32.76) (名称:吉姆,2月的分数:82,百分比变化:57.69) (名称:利兹,2月的分数:84 ,百分比变化:N
-
两个或更多排序集的交集
问题内容: 我有两个排序集,并且想要进行交集,即。 关于效率,是否有比以下更好的方法: 问题答案: 您应该先使用ZCARD检查哪些元素较少,然后克隆并修剪较短的元素。 其次,您将剩下2个剩菜。您可以重复使用同一辅助程序,以加快清除速度。 我还想建议克隆使用DUMP和RESTORE,但是对于排序集的情况,ZUNIONSTORE实际上要快得多。这是一个100万个元素集的时间安排:
-
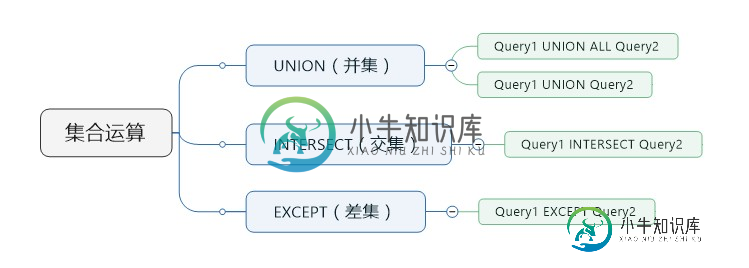 sql server 交集,差集的用法详解
sql server 交集,差集的用法详解本文向大家介绍sql server 交集,差集的用法详解,包括了sql server 交集,差集的用法详解的使用技巧和注意事项,需要的朋友参考一下 概述 为什么使用集合运算: 在集合运算中比联接查询和EXISTS/NOT EXISTS更方便。 并集运算(UNION) 并集:两个集合的并集是一个包含集合A和B中所有元素的集合。 在T-SQL中。UNION集合运算可以将两个输入查询的结果组合成一个
-
添加到集合时修改了集合
尝试添加到集合时出现“Collection was modified”异常 问题出在“添加”方法上。如果我注释掉该部分,则不会引发异常。重要的是要注意,我已经尝试将foreach重写为for循环并添加“ToList()”以形成。链接。在所有情况下都会引发相同的异常。我在站点的其他部分使用这种完全相同的模式没有问题,这就是为什么这如此令人沮丧。这也适用于“创建”。问题只影响“编辑”操作。 其他相关代
-
Redis集群等待集群加入Private VPC
我有3个使用Redis运行的EC2实例,如下所示: 服务器001:10.0.1.203,端口:6379 服务器002:10.0.1.202,端口:6380 服务器003:10.0.1.190,端口:6381 每个配置文件: 我可以通过redis连接到每台服务器上的每一台。 但是,当我运行集群创建时,脚本永远不会在服务器001上结束。 服务器002日志: 服务器003日志: 配置中缺少什么?
-
KeyCloak与mysql-InnoDB集群的独立集成
正在尝试让Keyclope与mysql innodb群集配合使用。我已经单独配置了Keyclope。xml符合文档要求。 这是数据源 这是司机 我还添加了module.xml打包mysql jdbc驱动程序(我使用最新版本mysql-connector-java-8.0.21.jar) 运行keydrope时出现的错误是 这方面的任何帮助都会非常有用。
-
将对象集映射到字符串集
我是Mapstruct的新手。我有一个Word对象,它包含一个字符串值和一组它自己,我想把它映射到WordDTO,它包含一个值和一组字符串值。我不知道怎么做。正如我在注释中所说,mapstruct不能映射两个对象是有道理的,但如果它有帮助,我将错误放在下面: 我为映射实现了这个接口: 谢谢你的帮助。
-
不同类型集合的集合重载
我知道重载是在编译时决定的,但当我试图运行下面的示例时,它给出了我无法理解的结果 当我每次运行这个代码片段时,我都会得到“Collection”的输出,这意味着调用参数为Collection的classify方法。 请解释
-
测试和持续集成 - 持续集成
translated_page: https://github.com/PX4/Devguide/blob/master/en/test_and_ci/continous_integration.md translated_sha: 95b39d747851dd01c1fe5d36b24e59ec865e323e PX4 Continuous Integration PX4 builds and
-
集合操作 - 集合间移动元素
smove srckey dstkey member 从srckey对应set中移除member并添加到dstkey对应set中,整个操作是原子的。成功返回1,如果member在srckey中不存在返回0,如果key不是set类型返回错误
-
您会建议哪种压缩(GZIP是最受欢迎的)servlet过滤器?
问题内容: 我正在寻找要在大量Web应用程序中使用的GZIP Servlet过滤器。我不想使用特定于容器的选项。 需求 能够压缩响应有效载荷(XML) 快点 经验证可用于大批量生产 应正确设置适当的 内容编码 可跨容器携带 (可选)能够解压缩请求 谢谢。 问题答案: 从我所看到的,大多数人通常使用gzip压缩过滤器。通常来自ehcache。 GZIP筛选器实现是:net.sf.ehcache.co
-
Java有什么理由在生成.equals()时更喜欢getClass()而不是instanceof?
问题内容: 我正在使用Eclipse生成和,并且有一个标记为“使用比较类型”的选项。缺省是不选中此选项并用于比较类型。有什么我比我更喜欢的理由吗? 不使用: 使用: 我通常会选中该选项,然后去掉“ ”检查。(这是多余的,因为空对象将始终失败。)是否有任何不好的主意? 问题答案: 如果你使用,让你实现将保留方法的对称性合同:。如果看似有限制,请仔细检查你的对象等效性概念,以确保你的首要实现完全维护类
-
您最喜欢的调试MS SQL存储过程的方法是什么?
问题内容: 我的大多数SP都可以通过手动输入的数据简单地执行(和测试)。这很好用,使用简单的PRINT语句可以“调试”。 但是,在某些情况下,涉及多个存储过程,并且找到要输入的有效数据很繁琐。从我的Web应用程序中触发事件会更容易。 我对Profiler有一点经验,但是我还没有找到一种方法来探索存储过程中逐行进行的操作。 你的方法是什么? 一如既往的谢谢你。 注意:我假设使用SQL Server