《欢聚集团》专题
-
具有并行流的散点聚集(聚合器中的超时)
我一直在尝试在聚集中添加超时,以避免等待每个流都完成。但是当我添加超时时,它不起作用,因为聚合器等待每个流完成。 E、 在我的流中,其中一个有2秒的延迟,另一个有4秒的延迟 我使用遗嘱执行人。newCachedThreadPool()以并行运行。我想释放包含的每条消息,直到超时完成 我一直在测试的另一种方法是使用默认的gatherer,并在scatterGather中设置GathereTimeou
-
 欢聚忽略我两段实习直接上前端八股实习生
欢聚忽略我两段实习直接上前端八股实习生7.1 欢聚(1000-9999人) 110-120一天的前端日常实习无转正一面 base广州,react优先,基础和理解特别多,shopline部门,40mins,部门里没有大四的正式工,实习经历和个人项目一点不问,哈哈先上八股 一个星期已经停止招聘了,估计根本不缺人招,经验不限,可能大专也能投吧 1. useMemo和useCallback的区别,他们直接都会返回函数吗,有什么 不一样呢?还给
-
SQL-枢转多个列而没有聚集
问题内容: 我不确定如何将数据透视到特定视图。以下是测试数据。 SQL 从输出中可以看到,未分组。 我将如何实现这一目标?或者我会完全朝错误的方向前进? 问题答案: 问题的一部分是您已跨多个要透视的列对数据进行了非规范化。理想情况下,您应该考虑修复表结构,以便于维护和查询。如果无法修复表结构,则应先取消对列的透视图,然后应用PIVOT获得最终结果。 UNPIVOT流程将采用多列并将其转换为多行。根
-
使用WebSphere的Spring集成聚合示例
问题:流输入仅适用于向聚合器发送输出通道输出的1个输入。随后的消息只进入丢弃通道logLateArvers。什么条件被用来发送到丢弃通道? 描述:尝试使用使用WebSphere的聚合器为基本jms移植Spring集成示例。 更新:-打开调试显示轮询器正在工作。消息被拉入并放到MQ,响应被拾取。但是,对于第一组消息之后的MQ场景,不使用AggregatingMessageHandler。消息被发送到
-
有序集合操作 - 评分的聚合
ZUNIONSTORE destination numkeys key [key ...] [WEIGHTS weight] [AGGREGATE SUM|MIN|MAX] 例如: 127.0.0.1:6379> zrangebyscore votes -inf inf withscores 1) "sina" 2) "1" 3) "google" 4) "5" 5) "baidu" 6) "10
-
MySQL喜欢IN()?
问题内容: 我当前的查询如下所示: 我环顾四周,找不到类似于LIKE IN()的东西-我认为它的工作方式如下: 有任何想法吗?我只是以错误的方式思考问题-一些我从未见过的晦涩命令。 MySQL 5.0.77-社区日志 问题答案: 一个REGEXP 可能 会更有效,但你必须对它进行基准测试,以确保,如
-
帖子 喜欢
帖子喜欢列表 帖子喜欢 帖子取消喜欢 帖子喜欢列表 GET /group-posts/:post/likes 参数 名称 类型 说明 limit integer 默认 15 ,数据返回条数 默认为15 after integer 默认 0 ,翻页标识。 响应 status 200 [ { "id": 152, "user_id": 1,// 攒点用户 "targe
-
欢迎文件
Web 应用程序开发人员可以在 Web 应用程序部署描述文件中定义一个称为欢迎文件的局部 URI 有序列表。在 Web 应用程序部署描述文件模式中描述了部署描述文件中欢迎文件列表的语法。 这种机制的目的是,当一个对应到 WAR文件中一个目录条目的请求 URI没有映射到一个 Web 组件时,允许部署者为容器用于添加 URI 指定局部URI 有序列表。这种请求被认为是有效的局部请求。 通过下面常见的例
-
欢迎窗口
当你开始 Navicat Data Modeler,一个欢迎窗口会弹出,你可以选择创建一个新模型、打开一个现有的模型等。在登录 Navicat Cloud 后,欢迎窗口会分为两部份:“我的 Mac 上”和“Navicat Cloud”。你可以在本机电脑和 Navicat Cloud 访问或保存模型。 创建一个新模型 在欢迎窗口中点击“新建模型”。 选择模型类型和其他设置。 从数据库创建一个新模型
-
欢迎窗口
当你开始 Navicat Data Modeler,一个欢迎窗口会弹出,你可以选择创建一个新模型、打开一个现有的模型等。在登录 Navicat Cloud 后,欢迎窗口会分为两部份:“本机”和“Cloud”。你可以在本机电脑和 Navicat Cloud 访问或保存模型。 创建一个新模型 在欢迎窗口中点击“新建模型”。 选择模型类型和其他设置。 从数据库创建一个新模型 选择“工具”->“从数据库导
-
 2-3月份:蔚来/欢聚/美团/百度产品…等日常产品实习生面经
2-3月份:蔚来/欢聚/美团/百度产品…等日常产品实习生面经2-3月份面了n家大厂、中厂产品,分享下面经攒人品,实习有消息了第一时间更新在评论区 用英文来段自我介绍(做海外或者跨境业务的岗位需要如此); 是否做过用户调研,步骤是什么,大概花费时间; 如何判定有效问卷; 用户调研如何设计问题; 详细叙述某个需求落地的策划过程; 策划过程中有没有遇到困难; 如果重新给你机会,你觉得哪里可以做的更好; 你理解的运营和产品的关系(自己过去有一段产品运营经历); 运
-
Maven-用于聚集的“全部”或“父”项目?
问题内容: 出于教育目的,我设置了一个这样的项目布局(为了更好地配合日食,将其布置为扁平状): 父级包含一个包含核心,优化和全部的汇总项目。Core实现了应用程序的强制性部分。Opt是可选部分。所有人都应该将核心与opt相结合,并将这两个模块列为依赖项。 我现在正在尝试制作以下工件: product-core.jar product-core-src.jar 产品核心与dependencies.j
-
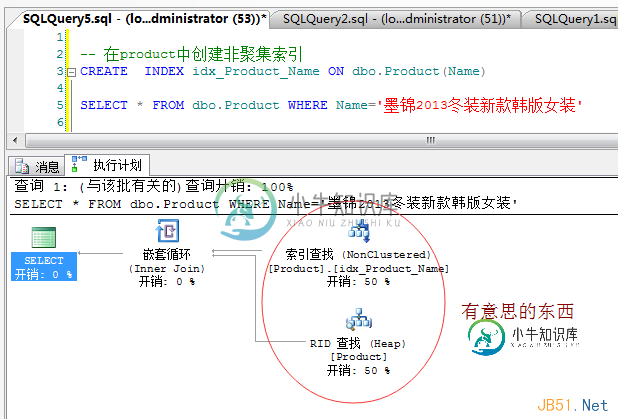 Sql Server中的非聚集索引详细介
Sql Server中的非聚集索引详细介本文向大家介绍Sql Server中的非聚集索引详细介,包括了Sql Server中的非聚集索引详细介的使用技巧和注意事项,需要的朋友参考一下 非聚集索引,这个是大家都非常熟悉的一个东西,有时候我们由于业务原因,sql写的非常复杂,需要join很多张表,然后就泪流满面了。。。这时候就有DBA或者资深的开发给你看这个猥琐的sql,通过执行计划一分析。。。或许就看出了不该有的表扫描。。。万恶之源。
-
SQL Azure无法识别我的聚集索引
问题内容: 当我尝试将行插入到SQL Azure表中时,出现以下错误。 此版本的SQL Server不支持没有聚集索引的表。请创建一个聚集索引,然后重试。 我的问题是我在该表上确实有一个聚集索引。我使用SQL Azure MW生成Azure SQL脚本。 这是我正在使用的: 为什么SQL Azure无法识别我的群集密钥?我的脚本错了吗? 问题答案: 您的脚本只会创建该表(如果该表尚不存在)。也许还
-
是Spring集成聚合器单线程执行
我在应用程序中使用拆分器聚合器模式。我有以下配置- 我的所有通道(CH1、CH2、CH3)都是。Splitter输入通道CH1的源代码是一个文件。 在我的测试中,我观察到即使在CH1通道中添加两个文件,在给定时间也只有一个文件被处理。所以我在我的CH1通道中添加了一个轮询器,现在正在同时处理CH1通道上的多个输入消息。 在聚合器方面,我也注意到执行总是单线程的,即直到第一个线程完成执行,第二个线程