《欢聚集团》专题
-
喜欢
喜欢资讯 取消喜欢资讯 资讯喜欢列表 喜欢资讯 POST /news/{news}/likes Response Headers Status: 201 Created 取消喜欢资讯 DELETE /news/{news}/likes Response Headers Status: 204 No Content 资讯喜欢列表 GET /news/{news}/likes Respons
-
喜欢
点喜欢 取消喜欢 喜欢的人列表 点喜欢 POST /feeds/:feed/like Response Status: 201 Created { "message": [ "操作成功" ] } 通知类型 { "channel": "feed:digg", // 通知关键字 "target": 325, // 动态id "content": "@2222 点喜欢了
-
欢迎
欢迎来到 Libra 开发者站点! Libra 的使命是建立一套简单的全球货币和金融基础设施,为数十亿人服务。 The world truly needs a reliable digital currency and infrastructure that together can deliver on the promise of “the internet of money.” Securi
-
聚集SQL GROUP BY中集合中的不同值
问题内容: 我有一个带有收集类型的表。我要从表和某些列开始。我希望每个组的结果都包含一个集合,该集合包含该组中所有单个集合的独特联合。 例如, 我在寻找什么答案 我只在寻找可以插入上方“神奇的语法在这里”占位符的表达式。我知道我可以通过加入主表或以其他方式重组查询(或当然使用PL / SQL)来完成聚合。但是,我现在暂时避免这样的解决方案。 问题答案: 从我的回答改编成另一个问题。 Oracle安
-
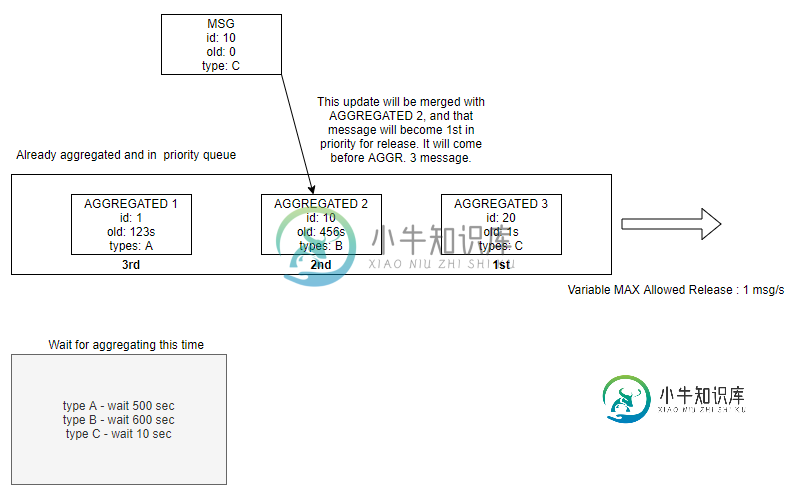 Spring集成-优先级聚合器
Spring集成-优先级聚合器我有以下应用程序要求: 从RabbitMq接收消息,然后根据一些更复杂的规则进行聚合,例如基于属性(具有预先给定的类型时间映射)和基于消息在队列中等待的现有时间(属性) 正如您在图中看到的一个用例:三条消息已经聚合并等待下一秒发布(因为当前速率为),但就在那时,以到达,并更新了,使其成为优先级最高的第一条消息。因此,在下一个选项中,我们不再发布聚合3,而是发布聚合2,因为它现在具有更高的优先级。
-
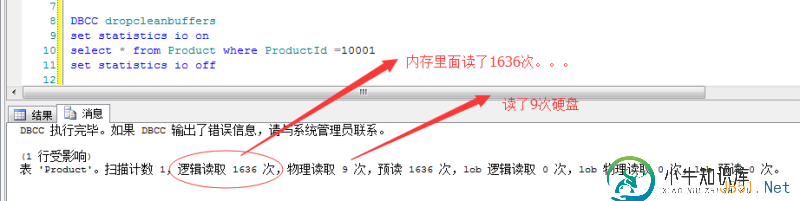
更好地使用包含索引的列的聚集索引还是非聚集索引?
问题内容: 当我查看特定查询的执行计划时,我发现我的成本的77%在聚簇索引查找中。 我使用聚集索引的事实是否意味着我不会因为输出的列而看到性能问题? 对我来说,创建一个非聚集版本并包含所有正在输出的列会更好吗? 更新:聚集索引使用组合键。不知道这是否有所作为。 问题答案: 使用非聚集索引上的包含列的原因是为了避免对聚集数据进行“书签查找”。问题是,如果SQL Server _理论上可以_使用特定的
-
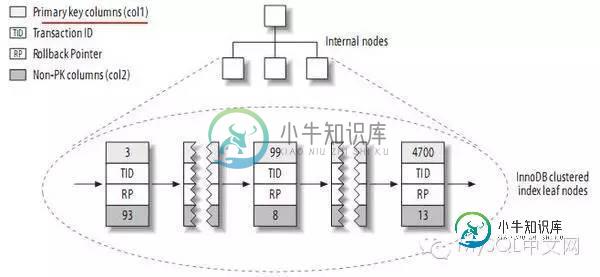 MySQL索引之聚集索引介绍
MySQL索引之聚集索引介绍本文向大家介绍MySQL索引之聚集索引介绍,包括了MySQL索引之聚集索引介绍的使用技巧和注意事项,需要的朋友参考一下 在MySQL里,聚集索引和非聚集索引分别是什么意思,有什么区别? 在MySQL中,InnoDB引擎表是(聚集)索引组织表(clustered index organize table),而MyISAM引擎表则是堆组织表(heap organize table)。 也有人把聚集索引
-
Microsoft Dynamics CRM唯一非聚集索引
我在工作中继承了一个Dynamics CRM系统,运行:Version1612(8.2.2.112)(DB 8.2.2.112)。 我们所处的情况是,重复似乎通过失败的表单提交断断续续地发生,随后又重新提交。我们已经在内部发布了一个文档,解释了这种行为,并表示首先检查部分或全部事务是否真正成功是多么重要。但人类终归是人类,常常忘记... 是否有更好的解决方案,我没有,提供数据库级的一致性,并不妨碍
-
 理解Sql Server中的聚集索引
理解Sql Server中的聚集索引本文向大家介绍理解Sql Server中的聚集索引,包括了理解Sql Server中的聚集索引的使用技巧和注意事项,需要的朋友参考一下 说到聚集索引,我想每个码农都明白,但是也有很多像我这样的猥程序员,只能用死记硬背来解决这个问题,什么表中只能建一个聚集索引,然后又扯到了目录查找来帮助读者记忆。。。。问题就在这里,我们不是学文科,,,不需要去死记硬背,,,我们需要的就是能看到在眼里面的真实东西
-
spring集成-拆分器和聚合器
目前,我正在与spring integration合作开发新的应用程序,并启动了poc,以了解如何处理故障案例。在我的应用程序中,spring integration将接收来自IBM mq的消息,并根据消息类型验证头信息和到不同队列的路由。传入的消息可能是批量消息,所以我使用了spring integration的拆分器和聚合器,并且对技术工作流程有很好的进展和控制。目前我面临的问题很少,我们有I
-
Mongodb聚合计数数组/集大小
{应用程序:“ABC”,日期:time.now,状态:“1”user_id:[id1,id2,id4]} {应用程序:“ABC”,日期:time.listerment,状态:“1”,user_id:[id1,id3,id5]} {应用程序:“ABC”,日期:time.ystayday-1,状态:“1”,user_id:[id1,id3,id5]} 我目前正在使用聚合框架并计算MongoDB之外的I
-
MySQL将列聚合为不同值集
我想将一列聚合为一组值。 让我们考虑以下模式 我需要这样的结果 我试着搜索一个集合聚合函数,但找不到任何有用的东西。
-
轴突再生聚集状态不清
null 我设置应用程序的方式是使用aggregateview将所需数据持久化到数据库中。因此,现在我感觉事件只是存储在事件存储区中,并且只在调用命令后用于重新创建聚合。对于正在存储的事件和集合的重新创建,我难道没有其他事情要做吗?例如,我是否应该重新创建整个聚合,而不是按ID从数据库中取出aggregateview来更新它。
-
MongoDB投影在@聚集Spring数据上
我已经为此挣扎了好几天了。我们刚刚开始与mongoDB合作,因此我对它的了解非常有限。 总之,我想做的是:我们有一个叫做Loan的课程,就像这样: 由于查询此集合时必须执行各种操作,因此我们在LoanRepository中创建了一个聚合(该聚合适用于我们在Mongo Compass中创建的,然后将其导出到我们的代码中): 这个想法是,在所有上述操作之后,我们只需要从整个Loans表中返回一些字段(
-
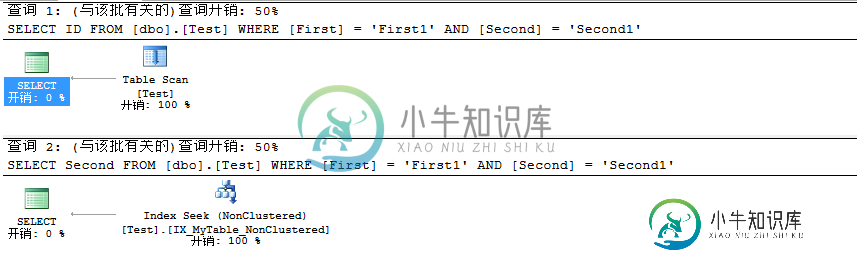 浅析SQL Server 聚焦索引对非聚集索引的影响
浅析SQL Server 聚焦索引对非聚集索引的影响本文向大家介绍浅析SQL Server 聚焦索引对非聚集索引的影响,包括了浅析SQL Server 聚焦索引对非聚集索引的影响的使用技巧和注意事项,需要的朋友参考一下 前言 在学习SQL 2012基础教程过程中会时不时穿插其他内容来进行讲解,相信看过SQL Server 2012 T-SQL基础教程的童鞋知道前面写的所有内容并非都是摘抄书上内容,如若是这样那将没有任何意义,学习的过程必须同时也是一