《欢聚集团》专题
-
图集
可以通过此模块将图集读入BK.SpriteSetCache中,可以获取图集中的小图位置信息,或是小图的BK.Sprite。 BK.SpriteSetCache.loadSet(Object) 从指定的文件中加载图集 手Q版本:7.6.3 Object参数 属性名 类型 是否必填 说明 jsonPath string 是 图集json文件路径 texturePath string 是 图集图片路径
-
集合
基本数据结构 Scala提供了一些不错的集合。 参考 Effective Scala 对怎样使用集合的观点。 数组 Array 数组是有序的,可以包含重复项,并且可变。 scala> val numbers = Array(1, 2, 3, 4, 5, 1, 2, 3, 4, 5) numbers: Array[Int] = Array(1, 2, 3, 4, 5, 1, 2, 3, 4, 5)
-
采集
采集(Ingest)指的是将文件(flv,mp4,mkv,avi,rmvb等等),流(RTMP,RTMPT,RTMPS,RTSP,HTTP,HLS等等),设备等的数据,转封装为RTMP流(若编码不是h264/aac则需要转码),推送到SRS。 采集基本上就是使用FFMPEG作为编码器,或者转封装器,将外部流主动抓取到SRS。 采集的部署实例参考:Ingest 应用场景 采集的主要应用场景包括: 虚
-
集合
集合类(Collection classes)提供了一组工具来操作数组或 Traversable(横穿) 对象。如果你使用过underscore.js,你就能对 Traversable 对象所具有的功能有大致的 了解。 集合的实例是不可变的; 修改一个集合将会产生一个新的集合。这让使用 集合对象产生更少的副作用并且有更多的可预测性。 简单例子 集合可以使用数组或者 Traversable 对象创建
-
集合
集合类似关系数据库的表,用于存储文档。在主窗口中,点击 “集合”来打开集合的对象列表。 你可以创建一个集合快捷方式,右击对象选项卡的集合并在弹出式菜单中选择“创建打开集合快捷方式”。此选项让你快速直接地打开集合来输入数据,而无需打开 Navicat 主窗口。 若要清空一个集合,请右击已选择的集合并在弹出式菜单中选择“清空集合”。 集合设计器 “集合设计器”是一个用于设计表的 Navicat 基本工
-
集合
集合类似关系数据库的表,用于存储文档。在主窗口中,点击 “集合”来打开集合的对象列表。 你可以拖出集合以创建一个集合快捷方式。这个快捷方式让你快速直接地打开集合来输入数据,而无需打开 Navicat 主窗口。 若要清空一个集合,请按住 Control 键并点按已选择的集合,然后在弹出式菜单中选择“清空集合”。 集合设计器 “集合设计器”是一个用于设计表的 Navicat 基本工具,能让你設定集合的
-
集合
在第一章我们提到了 Meteor 的核心功能, 那就是服务器端和客户端的自动数据同步。 在这一章我们要仔细了解一下它是如何运作的,以及研究那个让它得以运行的关键技术: Meteor 集合(Collection)。 集合是一个特殊的数据结构,它将你的数据存储到持久的、服务器端的 MongoDB 数据库中,并且与每一个连接的用户浏览器进行实时地同步。 我们想让我们的 post 永久保存并且要在用户之间
-
集合
集合类似关系数据库的表,用于存储文档。在主窗口中,点击 “集合”来打开集合的对象列表。 若要清空一个集合,请右击已选择的集合并在弹出式菜单中选择“清空集合”。 集合设计器 “集合设计器”是一个用于设计表的 Navicat 基本工具,能让你設定集合的属性、索引、验证、存储引擎,以及更多。 【注意】设计器中的选项卡和选项会根据服务器版本而有所不同。 集合查看器 当你打开集合时,“集合查看器”以网格显示
-
春季-mongodb-聚合-需要'cursor'选项
问题内容: 执行以下聚合管道: 引发以下异常: 我不明白这里的光标选项是什么意思。该选项应在哪里配置? 编辑 这是一个示例用户文档 问题答案: 从文档。 MongoDB 3.4不建议使用不带游标选项的聚合命令,除非管道包括解释选项。使用聚合命令以内联方式返回聚合结果时,请使用默认批处理大小游标:{}指定游标选项,或在游标选项游标:{batchSize:}中指定批处理大小。 你可以通过与在春季蒙戈2
-
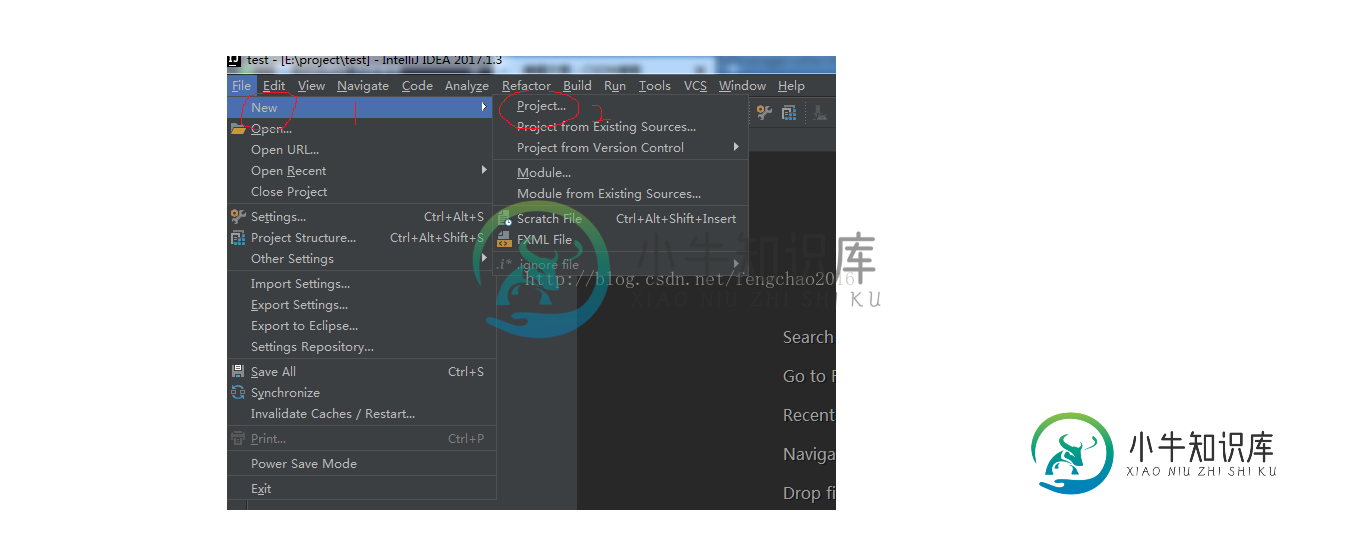 IDEA创建parent项目(聚合项目)
IDEA创建parent项目(聚合项目)本文向大家介绍IDEA创建parent项目(聚合项目),包括了IDEA创建parent项目(聚合项目)的使用技巧和注意事项,需要的朋友参考一下 关于聚合项目和父项目的概念有兴趣的可以去看《MAVEN实战这本书籍》,本篇描述使用IDEA工具创建继承和聚合项目的过程! 创建空白工程:作为存放项目的root目录 步骤一: 步骤2: 步骤3: maven继承:创建父-子项目 项目的结构示意图如下: 1.创
-
jq可以跨文件执行聚合
问题内容: 我正在尝试确定一个程序/软件,该程序/软件将使我能够有效地提取大量大型CSV文件(总计40+ GB),并输出具有导入到Elasticsearch(ES)所需的特定格式的JSON文件。 jq可以有效地获取如下数据: 按ID进行汇总(这样,多个文件中CSV行中的所有JSON文档都属于一个id条目),输出如下所示: 我用Matlab编写了一个脚本,但由于担心它的执行速度慢得多。我可能需要花费
-
深度嵌套类型的Elasticsearch聚合
问题内容: 示例文档中有一个简化的文档。这对我理解非嵌套类型与嵌套类型的聚合差异很有帮助。但是,这种简化掩盖了进一步的复杂性,因此我不得不在这里扩展这个问题。 所以我的实际文件更接近以下内容: 因此,我保留了,和的关键属性,但隐藏了许多其他使情况复杂化的内容。首先,请注意,与引用的问题相比,有很多额外的嵌套:在根和“项目”之间,以及在“项目”和“ item_property_1”之间。此外,还请注
-
Elasticsearch:可以处理聚合结果吗?
问题内容: 我使用SUM聚合计算服务过程的持续时间。执行过程的每一步都将保存在Elasticsearch中的调用ID下。 这是我监视的内容: 过滤: 这将返回该过程的完整持续时间,并且还告诉我该过程的哪一部分是最快的,而哪一部分是最慢的。 接下来,我要通过serviceId 计算 所有已完成过程 的平均 持续时间 。在这种情况下,我只关心每项服务的总时长,因此我可以提供帮助。 如何从total_d
-
ElasticSearch从数组字段过滤聚合
问题内容: 我正在尝试对数组中的值进行聚合,并且还过滤由前缀返回的存储桶。不知道这是否可行,或者我滥用过滤桶。 3份文件: 目的是获取带有字母B开头颜色的文档数量: 不幸的是,返回的结果包括Red。显然是因为带有红色的文档仍然按过滤器匹配,因为它们也具有蓝色和/或黑色。 有没有一种方法可以只过滤存储桶结果? 问题答案: 尝试此操作,它将过滤为存储桶本身创建的值:
-
ElasticSearch术语按整个字段聚合
问题内容: 如何编写一个将整个字段值而不是单个标记考虑在内的ElasticSearch术语聚合查询?比如,我想通过城市名聚集,但下面的回报,,并作为单独的水桶,不和的水桶预期。 问题答案: 您应该在映射中解决此问题。添加一个not_analyzed字段。如果您还需要分析的版本,则可以创建多字段。 现在在city.raw上创建聚合