《互联网大厂》专题
-
 Linux 下载百度网盘大文件的方法
Linux 下载百度网盘大文件的方法本文向大家介绍Linux 下载百度网盘大文件的方法,包括了Linux 下载百度网盘大文件的方法的使用技巧和注意事项,需要的朋友参考一下 Linux 下没有百度网盘客户端,用浏览器下载速度慢得急死人 鼠标移到链接处, 右键, 然后复制链接 接着在终端里输入 axel 是下载程序名, -n 后面数字是线程数,多少自己决定, -o 后面下载到本机上 保持的文件名, 最后面 英文引号里面放下载链接 使用这
-
 调用发生时,Spring云网关uri 413太大
调用发生时,Spring云网关uri 413太大我正在使用微服务,如前端、弹性4j api网关,其中一个是用户微服务,每个服务都在heroku中的单独应用程序中运行。 当从前端调用api网关服务应用程序的url时,我使用feign或rest模板登录时收到413个太大的请求异常 请告诉我根本原因。
-
使用最大内容自动拟合CSS网格
我有4个专栏。第1和第4列的实际含量为150px,第2列为250px,第3列为370px。我想在浏览器宽度改变时换行这些列。当我减小浏览器的宽度时,我希望每列在换行之前收缩到它们的最低宽度。所以我想象第4列在其宽度低于150px之后会以100%的宽度落到下一行。 以下是我认为应该做到的: 有没有一种方法可以做到这一点,而不需要在“max-content”所在的位置传递固定的宽度? 下面是我使用媒体
-
 无法创建“大黄蜂”的网络连接Q:
无法创建“大黄蜂”的网络连接Q:我几乎没有本地和远程HornetQ客户端需要连接到同一个HornetQ服务器。在系统启动的前2分钟,我总是看到HornetQ抛出“java.net.SocketTimeoutException:connect timed out”异常。2分钟后,连接就会连接起来。 我检查了获得异常的连接都来自当地的HornetQ客户端。它让我感到困惑,因为与远程连接相比,本地连接应该没有任何问题,除非我配置错误。
-
 网易大数据开发日常实习 已oc
网易大数据开发日常实习 已oc部门:网易云 8.23约面,8.25 一面 8.29 二面。8.30 hr面 一面: 45min左右 1.自我介绍 2.说说项目用到了哪些技术 3.你刚刚说到了即席查询,项目里是怎么做的。 4.四道sql,十分钟后对答案 5.笛卡尔积了解吗。 6.笛卡尔积会产生什么问题。 7.你刚刚说到了数据倾斜。介绍一下。 8.笛卡尔积就会产生数据倾斜吗 9.mr流程介绍一下 10.你多久能来实习 11.你刚刚
-
 网易大数据开发实习一面面试
网易大数据开发实习一面面试#校招##秋招#
-
 3.22 网易云大前端暑期实习二面
3.22 网易云大前端暑期实习二面忐忑心情接受二面。 二面面试官人很好,开摄像头了,问的问题很开放,应该是主要看思路的活跃度,很快,28分钟结束战斗,整个面试流程舒服的一笔。 记录一下,感觉从面试问题的思路来看能学习到很多东西。 1.介绍一下第一个项目的情况,用户量,主要是为了解决什么? 2.手持终端是什么?如果没有网络用什么通信?(项目特有) 3.短报文的设计和通信协议清楚吗 4.如果让你来设计一个通信协议你觉得要关注哪些点呢?
-
 畅唐网络笔试(大二C++日常实习)
畅唐网络笔试(大二C++日常实习)一个字,水,虽然自己也很菜,选择题错了好几个,该背八股了 一,选择题 1,int i = 1; const int j = 2; 以下错误的是 A,const int *p1 = &i; B, const int *p1 = &j; C, int *const p2 = &i; D, int *const p2 = &j; D错误,因为 j 是常量,不能通过指针修改它的值,所以使用 int *co
-
你有使用过互联网金融产品吗?请说明它的申请过程,使用方法,并分析它的优点和缺点。
本文向大家介绍你有使用过互联网金融产品吗?请说明它的申请过程,使用方法,并分析它的优点和缺点。相关面试题,主要包含被问及你有使用过互联网金融产品吗?请说明它的申请过程,使用方法,并分析它的优点和缺点。时的应答技巧和注意事项,需要的朋友参考一下 1、申请过程 登陆注册 实名认证四要素:银行卡号、身份证号、姓名、预留手机号 签约授信、获取相应额度 2、使用方法 信用卡代还、分期商城(分期购)、现金分期
-
在互联网平台,哪些内容不能发布?另外,如何看待网信办责令快手、抖音、火山小视频整改以及永久关停内涵段子?
本文向大家介绍在互联网平台,哪些内容不能发布?另外,如何看待网信办责令快手、抖音、火山小视频整改以及永久关停内涵段子?相关面试题,主要包含被问及在互联网平台,哪些内容不能发布?另外,如何看待网信办责令快手、抖音、火山小视频整改以及永久关停内涵段子?时的应答技巧和注意事项,需要的朋友参考一下 不能发布的内容 攻击我国***制度、法律制度的内容 分裂国家的内容 损害国家形象的内容 损害***领袖、英雄
-
从3个表中提取MySQL数据-联接和最大值
问题内容: 我有三个mysql表,我想从中提取一些信息,这些表是: 视频-代表带有分数的视频。 标签-包含标签的全局列表。 VideoTags在视频和标签之间创建关联。 我想做的就是找到每个标签的得分最高的视频。有许多具有相同标签的视频,但是我的结果集将具有与标签相同的行数。最终目标是为每个唯一标签(标签是主题加上哈希值)提供最佳视频列表(按得分)。 我的SQL noob尝试实现此目标的方法如下:
-
MySQL联接两个表,另一个字段具有最大值
问题内容: 我有两个表帐户和余额 我想加入这两个表并获取特定cid的最大日期余额。 输出结果为- 问题答案: 您需要使用两个子查询,如下所示: 输出: 客户编号 姓名 移动的 日期 平衡 1个 美国广播公司 12345 2013年9月20日00:00:00 + 0000 300 2个 XYZ 98475 2013年9月21日00:00:00 + 0000 600 看到这个SQLFiddle
-
关联
与Spark类似,Spark Streaming也可以利用maven仓库。编写你自己的Spark Streaming程序,你需要引入下面的依赖到你的SBT或者Maven项目中 <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-streaming_2.10</artifactId> <vers
-
级联
映射器支持可配置的概念 cascade 行为对 relationship() 构造。这是指相对于特定对象在“父”对象上执行的操作 Session 应传播到该关系引用的项(例如“子”对象),并受 relationship.cascade 选择权。 层叠的默认行为仅限于所谓的层叠 保存更新 和 合并 设置。级联的典型“可选”设置是添加 删除 和 删除孤儿 选项;这些设置适用于相关对象,这些对象仅在附加
-
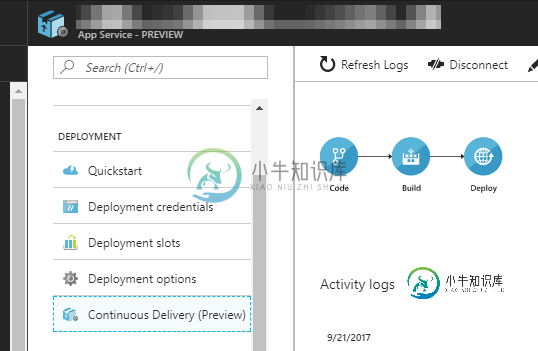 在Visual Studio Team Services (VSTS)中,生成和发布定义是如何相互联系的?
在Visual Studio Team Services (VSTS)中,生成和发布定义是如何相互联系的?在我的Azure网站上使用“持续交付”边栏选项卡: 我在VSTS建立了构建和发布定义。 源代码管理正确地触发了构建,然后发布在构建之后运行。一切都好。 我不明白的是构建和发布定义是如何联系起来的。我在两者的属性中看不到其他属性。它们是如何联系的? 第2部分让我困惑的是,当我查看构建定义中的任务时 没有部署任务——这对我来说很有意义,因为部署任务出现在发布定义中(似乎合乎逻辑): 但是,我看到在构建