《网易杭州研究院》专题
-
Codeigniter交易
问题内容: 我正在使用Codeigniter交易 这很好用,我的问题是在和我正在调用其他函数,而这些函数处理数据库,因此它们包含插入和更新以及一些删除…例如: 现在,如果执行了这些功能并且发生了一些错误,CodeIgniter将不会回滚。 处理此类问题的最佳方法是什么? 我想到的唯一解决方案是从这些函数中返回错误,并在这些函数中添加(和),如果返回错误,则执行 例如: 有更好的方法吗? 更新1:
-
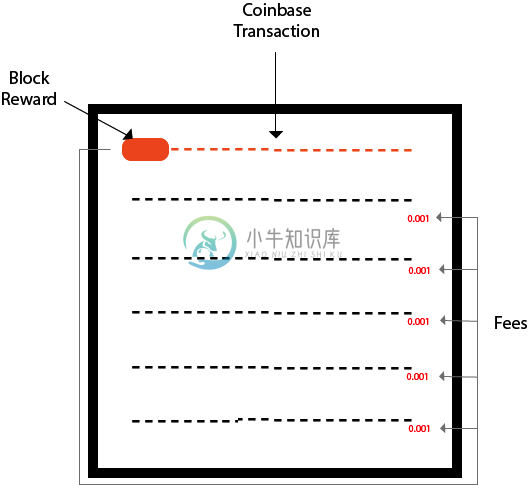 coinbase交易
coinbase交易coinbase交易是块中的第一个交易。它是一种可以由矿工创建的独特类型的比特币交易。矿工使用它来收取他们工作的区块奖励,矿工收取的任何其他交易费也在此交易中发送。 说明 在比特币网络上执行的每个交易组合在一起以形成块。当一个块立即形成时,它将包含在区块链中。这些块对于在比特币网络上进行的所有交易是不可变的和防篡改的。每个块必须包含一个或多个交易,块中的第一个交易称为交易。 矿工总是负责创建一个区
-
易用性
Bootstrap遵循常用的Web标准——用最少的额外付出——创建出能用AT访问的网站。 组件要求 一些常见的HTML元素总是需要基本的易用性辅助增强,通过role以及Aria属性可以实现易用性辅助增强。下面列出了一些频繁使用的。 注意,v4 alpha版本还在开发中,我们将把更多的易用性注解移到这里,带着指向本文档特定章节的链接。 按钮组 为了使辅助技术设备——比如说屏幕阅读器——传达一系列按钮
-
交易 Transactions
“交易”是用户使用比特币的过程。每个交易由几个部分构成,一个交易即可以是简单的直接支付,也可以是复杂的交易。本小节会描述交易的每一个部门,而且说明怎样把各个部分合起来构建成一个完整的交易。 为了简单起便,本小节假设 coinbase transactions 不存在。 coinbase transactions只能被矿机创建并且这些交易是下面很多规则的例外。与其一一指出 coinbase tran
-
交易(2)
在这个系列文章的一开始,我们就提到了,区块链是一个分布式数据库。不过在之前的文章中,我们选择性地跳过了“分布式”这个部分,而是将注意力都放到了“数据库”部分。到目前为止,我们几乎已经实现了一个区块链数据库的所有元素。今天,我们将会分析之前跳过的一些机制。而在下一篇文章中,我们将会开始讨论区块链的分布式特性。 之前的系列文章: 基本原型 工作量证明 持久化和命令行接口 交易(1) 地址 本文的代码实
-
交易(1)
引言 交易(transaction)是比特币的核心所在,而区块链唯一的目的,也正是为了能够安全可靠地存储交易。在区块链中,交易一旦被创建,就没有任何人能够再去修改或是删除它。今天,我们将会开始实现交易。不过,由于交易是很大的话题,我会把它分为两部分来讲:在今天这个部分,我们会实现交易的基本框架。在第二部分,我们会继续讨论它的一些细节。 由于比特币采用的是 UTXO 模型,并非账户模型,并不直接存在
-
5.7 交易
前言 我们在第一部分《了解加密货币》里说过,加密货币是“利益”转移的程序化,其核心目标是保证数字财富或价值安全、透明、快速的转移。因此,交易是加密货币系统中最重要的部分,是加密货币的核心功能,加密解密、P2P网络、区块链等一系列技术都是围绕交易展开的。 这一篇,我们就来研究亿书提供的交易类型及代码实现,集中总结交易的生命周期及实现过程,把我们在《地址》和《签名和多重签名》里故意漏掉的判断逻辑补充完
-
交易(Transaction)
交易相关的 API,接口的参数说明请参考Etherscan API 约定, 文档中不单独说明。 [BETA] 检查合约执行状态 (if there was an error during contract execution) Note: isError”:”0” = Pass , isError”:”1” = Error during Contract Execution https://api
-
易客CRM
一、易客CRM开源版本 易客CRM开源版本(http://www.c3crm.com),采用最流行的开发语言-PHP开发语言,基于新浪SAE云计算平台开发的新一代BS架构客户关系管理系统。此前只能在SAE和云商店平台上运行,现在已经可以在普通的PHP环境下运行。 二、易客CRM开源版本的设计理念 易客CRM的设计理念是软件一定要简单易用,一定要能解决企业的实际问题。 三、易客CRM开源版本适用的客
-
MyBatis拦截器原理探究
本文向大家介绍MyBatis拦截器原理探究,包括了MyBatis拦截器原理探究的使用技巧和注意事项,需要的朋友参考一下 MyBatis拦截器介绍 MyBatis提供了一种插件(plugin)的功能,虽然叫做插件,但其实这是拦截器功能。那么拦截器拦截MyBatis中的哪些内容呢? 我们进入官网看一看: MyBatis 允许你在已映射语句执行过程中的某一点进行拦截调用。默认情况下,MyBatis 允许
-
究竟谁违背了道德
实际上,恰恰是专有软件的理念--不允许共享或改动软件--是反社会的,也是不道德的,而且也是完全错误的。但是长期以来,软件出版商使人们相信:软件天生就该如此。这种片面的认识禁锢了人们的思维。当他们在谈论如何加强版权或打击盗版时,他们也认定这是天经地义,人们也会毫无异议地接受。 他们的第一个假设就是:软件公司对自己的软件拥有毫无疑问的天然权力,因而可以将权利施加到所有用户身上。(因为如果是天然权力,那
-
oracle究竟比mysql快在哪?
同样一个1000w的表,都有业务字段所索引 为什么oracle查起来很轻松,mysql就建议分库分表了。 是索引实现的区别导致的吗?还有底层IO读取的优化上的区别?还有哪些区别? 网上查的资料,讲的都太虚了,没讲到本质上
-
 联通软研院2025届校园招聘软件研发岗笔试
联通软研院2025届校园招聘软件研发岗笔试时间:2024-09-27 限时:1h30min 实际用时:1h 平台:国考云在线考试系统,支持本地IDE 0,题目目录: 行测题×10道; 专业知识题×25道; 编程题×3道; 1,题目类型: 行测题包括文本分析、病句判断、段意总结、选词填空等; 专业知识题包括HTML、软件设计模型、SQL、数据库、Java线程等; 编程题较简单。 2,编程题目: 编程题1:交换数组 时间限制:C/C++语言
-
Spring交易REQUIRED与REQUIRES_NEW:回滚交易
问题内容: 我有一个具有事务性属性的方法: 可以同时多次调用此方法,并且对于每个事务,如果发生错误而不是将其回滚(独立于其他事务),则将被多次调用。 问题在于,这可能迫使Spring创建多个事务,即使另一个事务可用,也可能会导致一些性能问题。 Java doc 说: 这似乎解决了性能问题,不是吗? 回滚问题呢?如果在使用现有事务时新方法调用回滚怎么办?那会不会回滚整个交易,即使以前的呼叫也是如此?
-
易失性读和非易失性场
在阅读了这个问题和这个(尤其是第二个答案)之后,我对volatile及其关于记忆障碍的语义感到非常困惑。 在上面的例子中,我们写入一个易失性变量,这会导致一个mitch,这反过来会将所有挂起的存储缓冲区/加载缓冲区刷新到主缓存,使其他缓存行无效。 然而,非易失性字段可以优化并存储在寄存器中,例如?那么,我们如何才能确保给定一个写入易失性变量之前的所有状态变化都是可见的呢?如果我们有1000件东西呢