《长沙》专题
-
用许多项目填充ScrollView需要太长时间
我目前正在android手机上开发一款简单的mp3播放器作为应用程序。我正在查看sd卡和内部存储器上的所有文件,找到所有扩展名为“.mp3”的文件。 简单又好用。 然后我填写一个列表,列出所有产生的歌曲名称,点击后,它们开始播放。工作也很好,但是 我现在在我的个人手机上尝试了这一点,上面有700首歌曲,列表在不到一秒钟的时间内完成,但现在列表将用结果填充foreach循环中的ScrollView。
-
在python中实现区域增长,不需要种子
我正在尝试在python中实现区域增长分割算法,但不允许使用种子点。到目前为止我的想法是这样的: 谁能给我指出正确的方向吗? 谢谢你!
-
基于agent到达调度的任意延迟长度
我正在模拟一个外科病房,其中有3种不同的病人类型(红色病人,蓝色病人和绿色病人)根据一个时间表进入。根据病人的类型(红色、蓝色或绿色),手术时间不同。红色:30分钟。蓝色:1小时,绿色:2小时。我正在使用延迟块来模拟手术时间。如何使延迟时间基于进入的患者类型? 例如:延迟时间为30分钟。当一个红色的病人进入延迟块,但如果一个蓝色的进入1小时? 谢谢!
-
Flink富集具有流转时长的传入数据
为了调试我们的应用程序,我们将所有传入数据(s3接收器)保存在图形的单独部分(甚至在时间戳/水印处理之前)。我们的数据已经包含了时间戳(event timestamp),在保存数据之前,我们想再添加一个字段,其中在消息实际进入flink时会有一个时间戳(处理时间)。 如何最好地做到这一点?也许flink为此提供了一个特殊的API,现在我们正在做非常简单的
-
Java Executor服务关闭现在需要很长时间
我有一个Java ExecutorService(固定线程池1),我将可运行的任务传递给它以供将来执行。每个任务通常在10秒内完成。Executor服务只是简单地完成任务。如果我关闭应用程序,我会运行以下程序:; 问题是它似乎需要一段时间才能关闭,有时可能需要几分钟,有时它似乎永远不会关闭,有时它会在几秒钟内关闭!在执行器队列中的任何时候都可能有大约2000个任务,但我只是希望它完成当前正在执行的
-
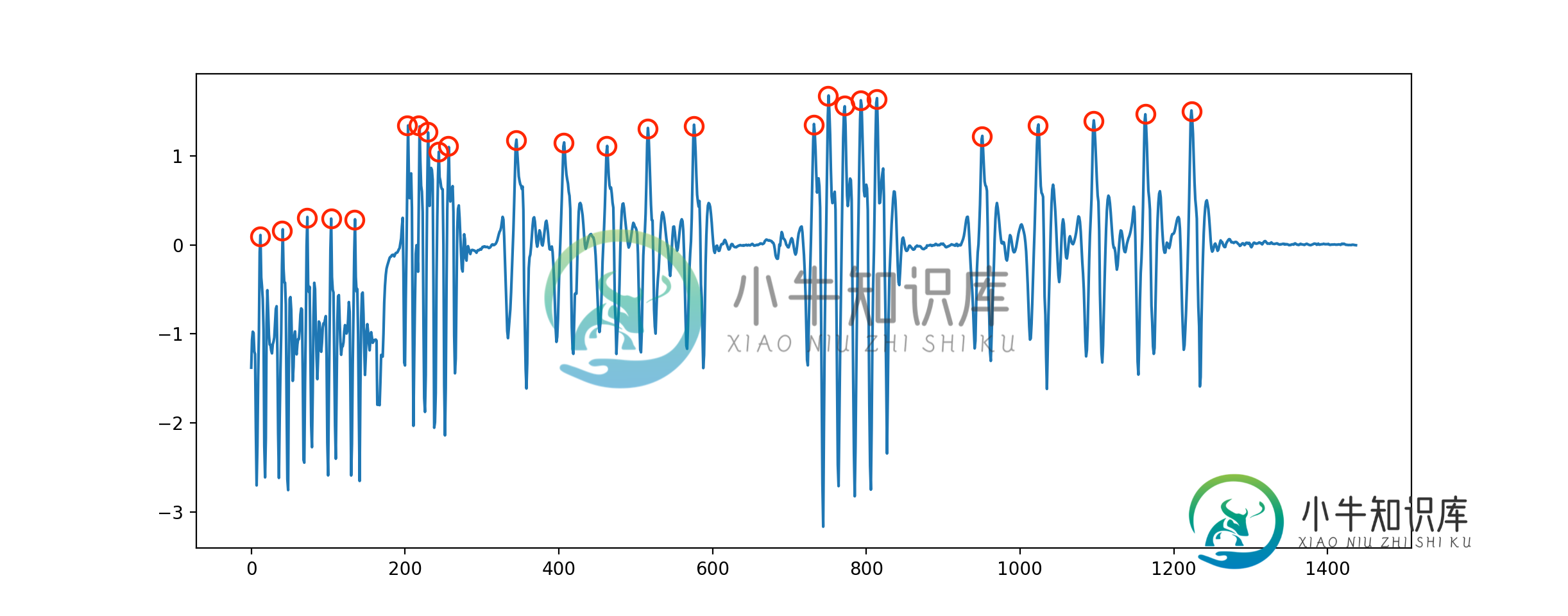 基于Swift的增长时间序列峰值检测
基于Swift的增长时间序列峰值检测谁会有一个好的算法来使用Swift(v3)测量不断增长的时间序列数据的峰值?因此,在数据流入时检测峰值。 例如,平滑z波算法的快速版本。那个算法似乎是合适的。 我需要检测如下所示的峰值。数据包含正数和负数。输出应该是峰值的计数器,和/或该特定样本的真/假。 示例数据集(上一系列的摘要): 最新消息:感谢Jean Paul首次提供Swift端口。但不确定z-wave算法是否适合此数据集
-
Epoch的步骤在GPU上花费了太长时间
我正在尝试训练一个模型,在我看来,与其他数据集相比,该模型花费的时间太长,因为完成一个历元需要大约1小时和20分钟。我认为问题是因为数据集没有存储在ram上,但我不确定这一点。 代码如下: 型号: 顺序模型 2个卷积层,32个神经元,激活=relu 1个卷积层,64个神经元,激活=relu 平整和致密层,激活=relu 退出0.5 具有sigmoid激活的输出层(致密) Adam optimize
-
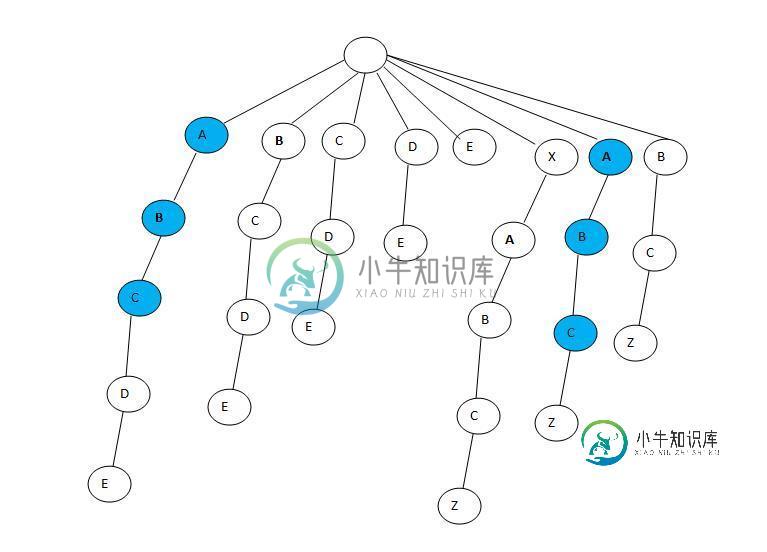 如何使用树查找最长的公共子串?
如何使用树查找最长的公共子串?一组字符串的最长公共子字符串可以通过为字符串构建一个通用后缀树来找到,然后从其下方子树中的所有字符串中找到具有叶节点的最深内部节点 最长的公共子字符串是,但它不是。我看不出wiki的描述在这里有什么帮助。 不是最深的内部节点和叶节点。 有什么帮助来理解它是如何工作的吗?
-
后缀树和最长重复子字符串问题
在字符串“”上运行算法以查找至少出现3次的最长子字符串时,后缀树中的所有节点最多有2个分支,这是怎么回事? 您可以在联机后缀树生成器中轻松查看树 我只是按照维基百科的描述: 查找出现次数至少为k次的最长子字符串的问题可以通过以下方法找到:首先对树进行预处理,以计算每个内部节点的叶后代数,然后查找出现次数至少为k次的最深节点 我错过了什么? 非常感谢。
-
如何找到字符串的最长重复序列
我在一个文本文件中有一个长字符串(DNA序列,超过20000个字符),我试图找到其中最长的序列,它至少重复了三次。实现这一目标的最佳方式是什么? 我能找到的唯一现有主题是在两个或多个单独的字符串中查找重复,但是如何使用一个长字符串?
-
递归:打印所有最长的公共子序列
Iam尝试使用以下代码打印所有可能的最长公共子序列 1-首先,我找到了LCS长度dp矩阵,并尝试使用递归生成所有可能的输出。 输入和输出 实际上,每次我将字符添加到输出列表时,我都需要弹出字符并将其插入为旧的附加新的。但是当我添加行时 然后它只显示了LCS的一种可能性,而不是全部。请帮助,我哪里出错了?
-
 Spring Webflux:调度程序。边界弹性向内生长
Spring Webflux:调度程序。边界弹性向内生长我正在用VisualVM监控我的Spring WebFlux应用程序,我注意到一件奇怪的事情。 边界弹性线程不断增加。 问题是我没有在我的应用程序中手动使用调度程序。 调试后我发现了这个 似乎InMemoryWebSessionStore请求调度程序。边界弹性。问题是,尽管依赖项中有Spring Security性,但该方法不需要任何授权。 如何禁用此行为?我不希望我的应用程序无限增加一些线程池大
-
为什么这个值对于我的H2表太长
我有一个spring data jpa应用程序,它使用H2进行存储。当我尝试将一些数据解析到表中时,我得到一个错误: 我有一个表定义为: 我的@Entity类为: 这是令人反感的记录,它显然小到足以容纳该列: 我所能想到的是分号或其他一些无效字符正在引发此异常。 有人能看到这里的问题,并提出处理它的替代方案吗?
-
带有空查询的MongoTemplate find()需要很长时间
我的Mongo Collection有大约2000个文档。当使用MongoTemplate find()方法和空查询(即我需要集合中的所有文档)和实体类、集合名称时,以列表的形式返回数据需要一分钟以上。有人能帮我让查询返回更快吗??下面是我正在使用的查询。
-
JDBC更新远程数据库需要很长时间
我正在通过JDBC准备语句更新远程数据库。当我执行相同的代码来更新本地数据库时,需要几毫秒的时间,但是对于远程数据库来说,大约900行的时间太长了。所有行的大小加起来是160 KB。远程主机是Hostgator,表的数据库引擎是InnoDB。 下面是我的代码: