《米哈游校招》专题
-
数据操作 - 哈希操作
底层实现是hash table,一般操作复杂度是O(1),要同时操作多个field时就是O(N),N是field的数量。应用场景:土法建索引。比如User对象,除了id有时还要按name来查询。 可以有如下的数据记录: (String) user:101 -> {“id”:101,”name”:”calvin”…} (String) user:102 -> {“id”:102,”name”:”ke
-
12、哈希表(关联数组)
哈希表的生成: 一个关联数组不通过下标来访问,而是通过主键(key)访问.这样的数组有时被叫作哈希(hash).将一对对的元素用逗号分隔开,并用大括号({})括起来,这样就组成了一个哈希表.你用一个关键字在哈希表里进行搜索,就像你在数组里用索引来提取数据一样. 例如: a={" Allex"=>2000," 帆布背包 "=>2003} 在这个例子中," Allex" 和 " 帆布背包 " 是主键(
-
web3.utils.sha3 - 计算sha3哈希值
使用web3.utils.sha3()方法计算给定字符串的sha3哈希值。 注意,如果要模拟solidity中的sha3,请使用soliditySha3函数。 调用: web3.utils.sha3(string) web3.utils.keccak256(string) // ALIAS 参数: string - String: 要计算sha3哈希值的字符串 返回值: String: 计算结果
-
 哈啰算法面试(凉经)
哈啰算法面试(凉经)codding环节 利用数组的最后一个数,作为分类标杆,把小于该数的数字放前面,大于该数的放后面。要求不能新建数组。 简历细挖,不是往深度思考的方向挖,而是更针对细节。扣的十分细节,总之,学到了很多东西。 部分提问如下 对比学习的思想? bert所有构件参数分析? 自注意力机制和多头自注意力机制的时间复杂度是多少? 自注意力流程说一下,每个小块都问了why? encoder部分中mlp怎么设置的,
-
 哈啰运营实习面经
哈啰运营实习面经哈啰运营实习生(已offer) 👥 面试题目 投递渠道是BOSS直聘,岗位名称就是运营实习生。业务面试官面了一次: 1.开头面试官很详细的介绍了部门情况,以及这个岗位负责哪些任务 2.然后让我自我介绍了一下 3.挖了第二段实习,我第二段实习偏数据产品,我强调了自己起到的沟通角色,被问了如何沟通,和协调各部门之间的任务。 4.有没有遇到什么困难,如何克服的 5.考察了SQL,问了几个问题没考代码,
-
 哈啰 Java开发 一面 50min
哈啰 Java开发 一面 50min好好好,又新增一个kpi面业绩 1、自我介绍 2、扒项目细节并且想出对应的优化方案 3、针对实际的业务场景,对于一个亿级数量的表和几百条、几十万条数据的表,你如何选择用ES还是MySQL,说明原因 4、当数据表中数据量过大,应该如何优化查询速度(建立索引或者分库分表) 5、MySQL和Redis的数据强一致性如何实现?(我说的先更新数据库再删除缓存,面试官说这不能保证强一致,要先删缓存再更新数据库
-
 哈啰前端一面面经
哈啰前端一面面经1、发布订阅者模式设计思想 2、发布订阅者模式和观察者模式区别 3、React hooks的优点 4、React fiber可以做什么 5、typeof 和instanceof区别 6、0.1+0.2为什么不等于0.3,底层逻辑 7、Promise状态更新是什么过程 8、接口调用超时,抛出错误怎么实现,如何用Promise.race实现 9、反转一个单向链表 10、Http缓存机制 11、Etag
-
 哈啰数开实习面经
哈啰数开实习面经1.有了解过JUC吗,讲一下你知道的 2.Java和python的内存管理机制 2.Hadoop,Hive和Hbase之间的关系 3.Spark和Flink有什么区别 4.Flink有哪些组件以及架构是什么样的 5.Flink有哪几种窗口和哪几种时间语义 6.Flink程序的编写流程是什么样的 7.Flink优化了解过吗,讲一下有哪些优化 8.FlinkUI监控页面使用过吗,你主要用来看什么 9.
-
 哈啰Java实习一面40min
哈啰Java实习一面40minbg:双非本211硕,黑马点评项目。5月份开始投的到现在的第一个面试 口述算法 判断链表是否有环? 如何高效判断大文件和小文件相同的数据行? leetcode影响深刻的题和如何实现?接雨水 Java @responBody和@requestBody注解作用 该注解序列化和反序列化在哪实现的 Spring这边框架源码看过没 MySQL 事务隔离级别? InnoDB事务实现原理? MVVC? 是看了资
-
 哈喽普惠数分面经
哈喽普惠数分面经一面 4.27 1.实习经历中详细讲一个项目及产出 2.tableau了解吗(有dashboard项目就没细问? 3.窗口函数了解吗 rank dense_rank row_number 区别 4.abtest流程 5.想来上海长期发展吗,转正意愿? 团队主要负责看板搭建,报告产出 虽然隔了个五一,但好久没消息,估计凉凉,崩铁小保底也歪了,心更累了
-
Jenkis下游作业无法找到上游工件
问题内容: 该设置用于构建和部署到Adobe AEM。 主构建作业从git存储库中提取,构建和打包,运行测试,然后触发应使用上游作业中已构建软件包的下游作业。 问题是下游作业失败并显示以下消息: 在我看来,由下游作业触发的某种方式的CopyArtifacts插件正在寻找错误位置的工件。正确的位置是 但是然后,它抱怨 下游作业从另一个项目复制工件,然后该生成是“触发此作业的上游生成”或“从最新完成的
-
 上海游族网络游戏测试一面(凉)
上海游族网络游戏测试一面(凉)9.24笔试 9.28收到hr电话 但流程一直卡住。 客户端笔试过了,但排序比较后,然后就主动提出转到游戏测试这边了) 10.21技术面(20分钟) 1.自我介绍 2.为什么转志愿到游戏测试这边 3.测试用例的组成 4.一个杯子的测试点 5.怎么去定义一个bug 6.录用你的话,你觉得你会待多久 7.职业规划 8.你觉得一个测试用例你能执行多少遍 9.如何看待加班 反问 面试官回答
-
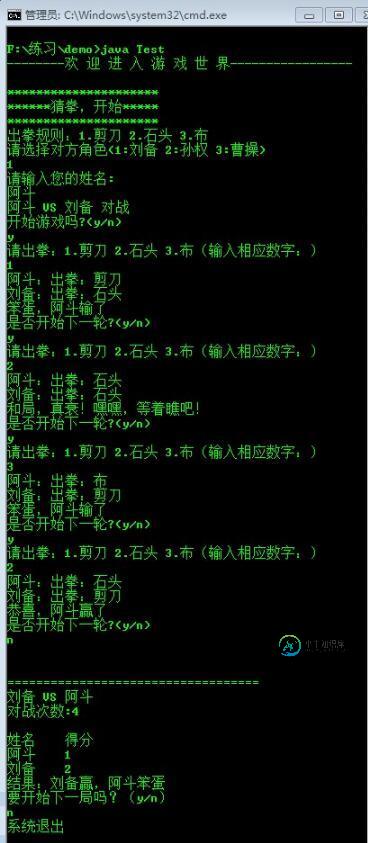 Java控制台实现猜拳游戏小游戏
Java控制台实现猜拳游戏小游戏本文向大家介绍Java控制台实现猜拳游戏小游戏,包括了Java控制台实现猜拳游戏小游戏的使用技巧和注意事项,需要的朋友参考一下 本文实例为大家分享了Java猜拳游戏的具体代码,供大家参考,具体内容如下 先来看一下效果图: 首先我们创建一个Person类,这个类有name和score两个属性,有play这个方法,源代码如下: 接下来是主程序入口: 源代码下载:Java猜拳游戏 以上就是本文的全部内
-
 pygame游戏之旅 如何制作游戏障碍
pygame游戏之旅 如何制作游戏障碍本文向大家介绍pygame游戏之旅 如何制作游戏障碍,包括了pygame游戏之旅 如何制作游戏障碍的使用技巧和注意事项,需要的朋友参考一下 本文为大家分享了pygame游戏之旅的第6篇,供大家参考,具体内容如下 定义一个障碍模型函数: 在游戏循环中调用: 障碍消失之后修改x值: 全部代码: 结果图: 以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持呐喊教程。
-
简单游戏机游戏中的点数跟踪
我很难把我的心思放在这件事上。每当玩家猜错时,它应该从最初的余额中减去他/她的赌注。由于它是在一个循环中,它总是从一开始就取初始平衡,每次都吐出相同的平衡。(很明显)我试过分配不同的变量,但似乎无法找到答案。 我已经省略了中等难度和难难度的方法,因为它们现在是没有用的,直到我弄清楚这个。