《群核科技》专题
-
插入带核心的行
SQLAlchemy 1.4 / 2.0 Tutorial 此页是 SQLAlchemy 1.4/2.0教程 。 上一次: 使用数据 |下一步: |next| 插入带核心的行 使用Core时,SQL INSERT语句是使用 insert() 函数-此函数生成 Insert 表示SQL中的INSERT语句,将新数据添加到表中。 ORM阅读器 -从ORM的角度将行插入数据库的方式在 Session 对
-
绘图: matplotlib核心剖析
matplotlib是基于Python语言的开源项目,旨在为Python提供一个数据绘图包。我将在这篇文章中介绍matplotlib API的核心对象,并介绍如何使用这些对象来实现绘图。实际上,matplotlib的对象体系严谨而有趣,为使用者提供了巨大的发挥空间。用户在熟悉了核心对象之后,可以轻易的定制图像。matplotlib的对象体系也是计算机图形学的一个优秀范例。即使你不是Python程序
-
实现内核重映射
实现内核重映射 在上文中,我们虽然构造了一个简单映射使得内核能够运行在虚拟空间上,但是这个映射是比较粗糙的。 我们知道一个程序通常含有下面几段: .text 段:存放代码,需要可读、可执行的,但不可写; .rodata 段:存放只读数据,顾名思义,需要可读,但不可写亦不可执行; .data 段:存放经过初始化的数据,需要可读、可写; .bss 段:存放零初始化的数据,需要可读、可写。 我们看到各个
-
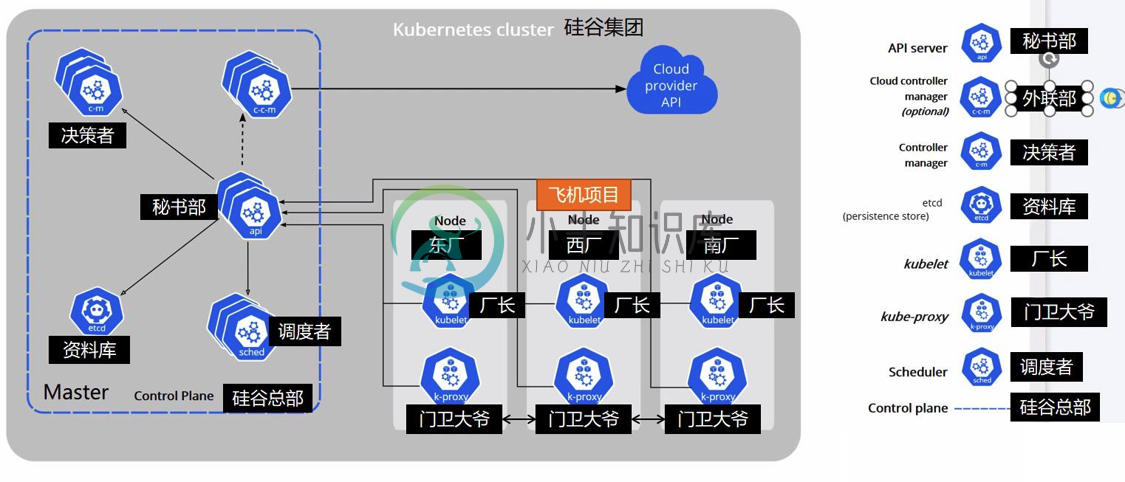 Kubernetes 核心资源原理
Kubernetes 核心资源原理主要内容:1.kubernetes 架构,2.从创建 deployment 开始,3.Pod,3.容器编排,4.水平扩缩容,5.更新/回滚,6.滚动更新,7.kubernetes 中的网络,8.微服务—service,9.kubernetes 中的服务发现与网络调用kubernetes 已经成为容器编排领域的王者,它是基于容器的集群编排引擎,具备扩展集群、滚动升级回滚、弹性伸缩、自动治愈、服务发现等多种特性能力。 1.kubernetes 架构 从宏观上来看 kubernetes 的整体架构,包
-
Linux 内核的通知链
Introduction The Linux kernel is huge piece of C) code which consists from many different subsystems. Each subsystem has its own purpose which is independent of other subsystems. But often one subsyst
-
魅族 MX 核心代码
虽然魅族自M9以来就一直在使用Android系统,却一直没有根据协议开源所使用的Linux核心。如今距离MX已经上市接近一年,魅族在近日终于将旗 下手机的核心源代码上传至Github,支持的机型包括M030、M031和M032。 由于Linux核心采用的是GPL协议,因此根据规定是必须要开源的,魅族此举算是完成了一件长久以来必须要完成的事情。虽然M9的核心暂时没有包含在 内,但是根据魅族员工的说法,M9的核心将于近期上传。
-
核电放置重制版
《核电放置重制版》和之前网站上发的那个《反应堆增量》类似。不过之前那个是Unity制作的,咱们汉化不了,现在这个是h5的,阔以汉化。 注意:游戏默认是暂停状态的,需要手动点一次:取消暂停才会开始游戏。
-
JBOSS独立HornetQ组播集群在集群中抛出循环
18:38:14,391警告[org.hornetq.core.server.cluster.impl.clusterConnectionImpl](Thread-4(HornetQ-client-global-threads-20937207))MessageFlow RecordImpl[nodeid=3AFB4E60-Ed20-11E1-831C-109add44C09e,connector
-
Java微信公众平台之群发接口(高级群发)
本文向大家介绍Java微信公众平台之群发接口(高级群发),包括了Java微信公众平台之群发接口(高级群发)的使用技巧和注意事项,需要的朋友参考一下 再次吐槽下,微信素材管理和群发这块文档对Java很不友好,此文需要结合我前文和官方文档。 测试号调试群发只需看是否群发消息是否能组装成功,不需要看结果如何(反正不会发送成功的),因为微信还没开放这个功能(估计也不会开放的)。 一、群发说明 在公众平台网
-
 旷视科技AI产品经理offer|0实习文科人工智能offer
旷视科技AI产品经理offer|0实习文科人工智能offer具体面经 自我介绍 展开讲一下自己满意的一段工作经历? 三款机器人最熟悉的一款机器人? 这款机器人主要解决了什么问题? 送餐机器人是一定程度上替代服务员,目前机器人有什么难题? 你们这个机器人是怎样知道送到哪里的? 那识别地图不会有偏差?通过定位还是距离判断的? 上面的几个项目是怎么回事? 详细说明一下第二个Funny这个项目 场景化的讲一下你这个产品的用户使用过程 产品经理的核心能力 最喜欢的一
-
SVM中什么时候用线性核什么时候用高斯核?
本文向大家介绍SVM中什么时候用线性核什么时候用高斯核?相关面试题,主要包含被问及SVM中什么时候用线性核什么时候用高斯核?时的应答技巧和注意事项,需要的朋友参考一下 参考回答: 当数据的特征提取的较好,所包含的信息量足够大,很多问题是线性可分的那么可以采用线性核。若特征数较少,样本数适中,对于时间不敏感,遇到的问题是线性不可分的时候可以使用高斯核来达到更好的效果。
-
火花流-4核和16核的处理时间相同。为什么?
场景:我正在用spark streaming做一些测试。大约有100条记录的文件每25秒就出现一次。 问题:在程序中使用local[*]时,4核pc的处理时间平均为23秒。当我将相同的应用部署到16核服务器时,我期望处理时间有所改善。然而,我发现它在16个内核中也花费了同样的时间(我还检查了ubuntu中的cpu使用率,cpu得到了充分利用)。所有配置默认由spark提供。 问题:处理时间不应该随
-
何时在Linux内核中使用内核线程vs工作队列
问题内容: 在Linux内核中有许多安排工作的方法:计时器,tasklet,工作队列和内核线程。什么时候使用一个对另一个的准则是什么? 有明显的因素:计时器功能和小任务无法进入睡眠状态,因此它们无法等待互斥量,条件变量等。 在驱动程序中为我们选择哪种机制的其他因素是什么? 首选的机制是什么? 问题答案: 如您所说,这取决于手头的任务: 工作队列将工作推迟到内核线程中-您的工作将始终在流程上下文中运
-
预期2.6.16和2.6.26内核版本之间的“内核太旧”错误
问题内容: 我在运行带有内核2.6.26-2-amd64的Linux(Debian)的计算机上构建了一个应用程序,我想在运行运行内核2.6.16.60-0.21-smp的Linux(Suse)的另一台计算机上运行此应用程序,但是出现了错误“致命:内核太旧”。 我从互联网上的研究中得知,如果针对未编译为支持较早内核版本的glibc库进行构建,则可能会发生这种情况,但它通常涉及2.4版。是否有可能针对
-
核心3.0升级后,无法使用EF核心3.0添加迁移
升级核心3.0后,无法在包管理器中添加迁移。这是我的错误