《2023届毕业生》专题
-
Google Cloud Dataflow Python,检索作业ID
问题内容: 我目前正在使用Python处理数据流 模板 ,我想访问作业ID并将其保存到特定的Firestore文档。 是否可以访问作业ID? 我在文档中找不到与此有关的任何内容。 问题答案: 您可以通过在管道中进行调用来实现(请参见下面的完整代码)。一种可能性是始终使用相同的作业名称来调用模板,这很有意义,否则可以将作业前缀作为运行时参数传递。使用正则表达式解析作业列表,以查看该作业是否包含名称前
-
营业时间数据库设计
问题内容: 我们目前正在开发一个应用程序,其中多个实体具有关联的营业时间。营业时间可能会持续数天,也可能会在一天内。 前任。星期一在6:00开放,星期五在18:00关闭。 或者 星期一在06:00开放,星期一在15:00关闭。 同样,一个实体每天可能有多组开放时间。到目前为止,我发现最好的设计是定义一个开放时间,其中包括以下内容: StartDay,StartTime,EndDay和EndTime
-
吴哥商业产品未展出
我将在woocommerce中插入新产品- 产品插入成功。 但不显示在商店或归档类别页面中。 只能显示单个产品页面。 我试着在谷歌上搜索。
-
按需触发Jira的Jenkins作业
Jenkins Jira插件,有没有办法配置插件以触发按需构建?。 我目前正在研究集成Jenkins和Jira,其中可以从Jira触发自动测试用例,Jenkins的结果将作为评论发布到Jira。(但上述触发应基于案例,不应在状态更改为Jira票证时触发) 我已经使用Zapier(试用版)评估了该场景,但无法根据需要获得它。欢迎提出任何建议
-
如何在hadoop中调度作业
我是hadoop新手,我写了一些作业并将它们导出为jar文件。我可以使用hadoop jar命令运行它们,我想每一小时运行一次这些作业。我该怎么做?提前谢谢。
-
向emr提交本地spark作业
im关注亚马逊文档,向emr集群提交spark作业https://aws.amazon.com/premiumsupport/knowledge-center/emr-submit-spark-job-remote-cluster/ 在按照说明进行操作后,使用frecuent进行故障排除,它由于未解析的地址与消息类似而失败。 错误火花。SparkContext:初始化SparkContext时出错
-
hadoop 2.2.0作业列表抛出NPE
我编译了hadoop 2.2.0 x64并在集群上运行它。当我执行或时,它会像这样抛出一个NPE: 在hadoop webapp上,比如job历史(我打开job历史服务器)。它显示没有作业正在运行,也没有作业完成,尽管我正在运行作业。 请帮我解决这个问题。
-
在docker中运行cron python作业
问题内容: 我想以分离模式在docker容器中运行python cron作业。我的设置如下: 我的python脚本是test.py 我的cron文件是my-crontab 而我的Dockerfile是 这种方法潜在的问题是什么?还有其他方法,它们的优缺点是什么? 问题答案: 我在尝试使cron作业在docker容器中运行时遇到的几个问题是: Docker容器中的时间不是UTC的本地时间; dock
-
Hikari连接和活动AS400作业
我使用Hikari连接池管理器来查询AS400机器中的一些表。 我设置了至少1个连接池连接,最多10个。我同时查询5个表。 问题是,尽管在查询之前使用HikariDataSource getConnection()方法,并且在每次查询之后使用Connection关闭()方法,但当我转到WRKACTJOB时,我看到10个活动作业,大概是每个连接一个,直到达到最大连接池连接。 如何清除未使用的连接\作
-
说一说你的职业规划?
本文向大家介绍说一说你的职业规划?相关面试题,主要包含被问及说一说你的职业规划?时的应答技巧和注意事项,需要的朋友参考一下 对于新人,清晰的职业规划是必备的,贴一个自己的回答。 在未来2-3年里争取做到一个全栈型新媒体人,并且有专精的1到2个领域,不管是内容、品牌、渠道还是用户,我会热衷于提升自己行业的软硬实力。 熟悉多个自媒体平台的运营法则,掌握核心的营销手段。 掌握各个方面的新媒体技能(平面设
-
Spring批量作业无限循环
在产品发布的最后一分钟,我发现Java Spring批处理有一个奇怪的问题。它进入无限循环。 这是我的配置: 记录总数为10条。因此,提交是在处理每一条记录之后进行的。我正在将结果写入Writer中的数据库。 我从阅读器中一个接一个地获取项目,处理并写入数据库。 它一直在运行,并将数据无限地插入表中。 观察结果是:提交间隔 如果有人提出一些解决方案/解决方法,在因为这个问题而举行生产发布时,这将对
-
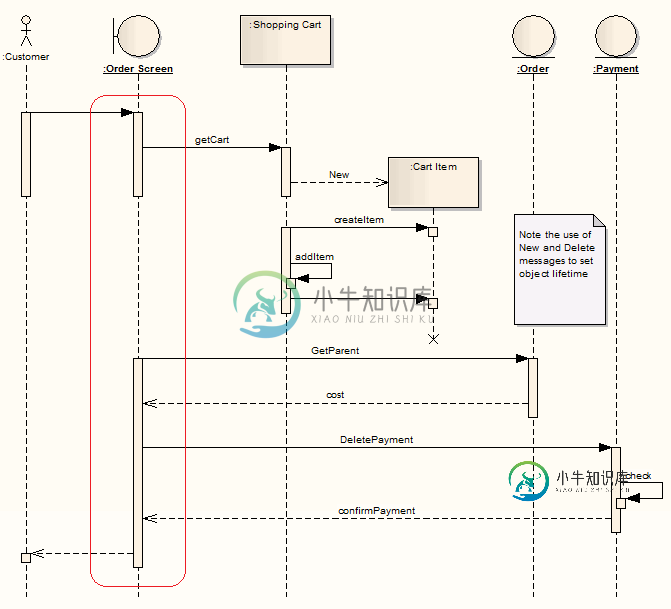 合并实体-企业架构师
合并实体-企业架构师我有一个问题,我如何“合并”实体的序列图在企业架构师(红圈),使他们成为一个长长的条从顶部到结束的生命线?
-
关闭Quartz作业日志记录
在我的应用程序中,石英作业是在应用程序部署后立即安排的。我有两个日志文件和,都用于特定的日志记录。搜索日志文件只是记录访问者的IP,其余所有日志记录(异常、调试信息)都记录在应用程序日志文件中。 我面临的问题是,默认的Quartz语句正在登录到文件中,这不是必需的。 如何禁用该日志记录?将级别设置为OFF不起作用。我也遵循了禁用石英日志记录,但这也没有帮助。 下面是我的log4j.properti
-
Spring批量-动态作业选择
我们当前的代码库具有以下重要特征: 一个代码库-但是很多批处理(我们在批处理之间重用代码) 目前,我们在代码库中有多个main()方法,并且只有不同的shell脚本来调用正确的main类。 我希望在Spring Batch中解决以下问题: null 提前谢了。
-
正在kubernetes上运行flink作业
我正在kubernetes上试用最新版本的Flink1.5的flink工作。 我的问题是如何在上面的flink集群上运行一个示例应用程序。flink示例项目提供了如何使用flink应用程序构建docker映像并将该应用程序提交给flink的信息。我遵循了这个例子,只是把flink的版本改成了最新版本。我发现应用程序(example-app)提交成功,并且在kubernetes的pod中显示,但是f