《神策数据》专题
-
神经网络训练中的Elman和Jordan上下文值
我正在使用Encog框架对Elman和/或Jordan ANN进行实验。我正在尝试编写自己的代码,但正在研究Encog是如何实现的。我看到了时间的反向传播是如何更新权重的,但是上下文神经元是如何更新的呢?当计算神经网络的输出时,这些值似乎会随机波动。这些值如何使简单的递归神经网络能够随着时间的推移识别输入数据中的模式?
-
监视所有JavaScript对象属性(神奇的getter和setter)
问题内容: 如何在JavaScript中模拟PHP风格的__get()和__set()魔术获取器/设置器?许多人说这目前是不可能的。我几乎可以肯定,这是有可能的,因为像nowjs(http://nowjs.com)这样的项目会做这样的事情。 我知道您可以利用get和set,但是当您不确定属性名称是什么时,这些将无法使用。例如, 如果您希望在创建新属性时执行事件处理程序,该 怎么办? 我想做的例子:
-
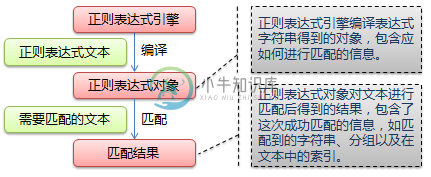 零基础写python爬虫之神器正则表达式
零基础写python爬虫之神器正则表达式本文向大家介绍零基础写python爬虫之神器正则表达式,包括了零基础写python爬虫之神器正则表达式的使用技巧和注意事项,需要的朋友参考一下 接下来准备用糗百做一个爬虫的小例子。 但是在这之前,先详细的整理一下Python中的正则表达式的相关内容。 正则表达式在Python爬虫中的作用就像是老师点名时用的花名册一样,是必不可少的神兵利器。 一、 正则表达式基础 1.1.概念介绍 正则表达式是用于
-
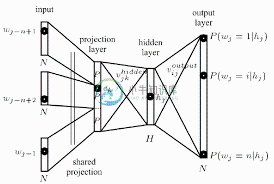 什么是神经网络上下文中的投影层?
什么是神经网络上下文中的投影层?我目前正在尝试理解word2vec神经网络学习算法背后的体系结构,该算法基于上下文将单词表示为向量。 读了托马斯·米科洛夫的论文后,我偶然发现了他定义的投影层。尽管这个术语在提到word2vec时被广泛使用,但我无法找到它在神经网络环境中的确切定义。 我的问题是,在神经网络环境中,什么是投影层?它是给一个隐藏层命名的,该层与以前节点的链接共享相同的权重吗?它的单位真的有某种激活功能吗? 另一个更
-
需要帮助定义一个简单的神经网络
我对这个很陌生,我有几个问题。我有用keras创建的python神经网络的代码片段。该模型用于情感分析。使用标记数据的训练数据集(情绪=1或0)。现在我有几个关于如何描述神经网络的问题。 我对以下许多条款都不是很清楚,所以不要对我太苛刻。 1:有什么能让这成为情绪分析的典型模型吗? 2:它是“单词袋”吗?(我的猜测是肯定的,因为数据是使用标记器预处理的) 3:是“卷积”吗? 4:深吗? 5:密度大
-
keras中卷积神经网络的输出形状误差
我一直在研究一个简单的卷积神经网络模型,但输出似乎与我想要的形状不匹配。 所以我的输入大小似乎不是问题。我的训练集输入形状是(13630, 200, 4, 1)其中13630是数据的数量,而我的training_label如下。(13630,2)我期望模型输出形状是(2,),但它似乎期望(1,)作为输出大小。 所以我的错误是这样的。 检查目标时出错:预期稠密_28具有形状(1),但获得具有形状(2
-
 池化步骤后卷积神经网络如何进行?
池化步骤后卷积神经网络如何进行?我试图学习卷积神经网络,但我很难理解在合并步骤后神经网络会发生什么。 所以从左边开始,我们有代表我们图片的28x28矩阵。我们对其应用三个5x5过滤器以获得三个24x24特征图。然后我们对每个2x2正方形特征图应用最大池化以获得三个12x12池化层。我了解到这一步的一切。 但现在发生了什么?我正在读的文件说: “网络中的最后一层连接是一个完全连接的层。也就是说,这一层将最大池化层的每个神经元连接到
-
 简单的前馈神经网络与TensorFlow不会学习
简单的前馈神经网络与TensorFlow不会学习我试图用TensorFlow建立一个简单的神经网络。目标是在32像素x 32像素的图像中找到矩形的中心。矩形由五个向量描述。第一个向量是位置向量,其他四个是方向向量,组成矩形边。一个向量有两个值(x和y)。 该图像的相应输入为(2,5)(0,4)(6,0)(0,-4)(-6,0)。中心(以及所需输出)位于(5,7)。 我想出的代码如下所示: 遗憾的是,网络无法正常学习。结果太离谱了。例如,[[3.
-
用于训练深度神经网络的强化学习
我计划编写一个国际象棋引擎,它使用深度卷积神经网络来评估国际象棋的位置。我将使用位板来表示棋盘状态,这意味着输入层应该有12*64个神经元用于位置,1个用于玩家移动(0表示黑色,1表示白色)和4个神经元用于铸币权(wks、bks、wqs、bqs)。将有两个隐藏层,每个层有515个神经元,一个输出神经元的值介于-1表示黑色获胜,1表示白色获胜,0表示相等的位置。所有神经元都将使用tanh()激活函数
-
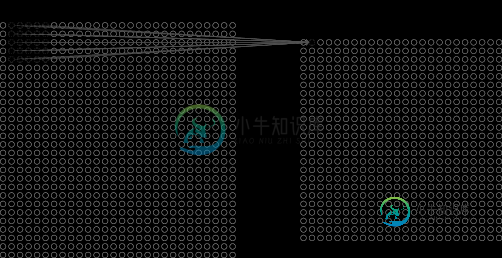 可以用感知器构建卷积神经网络吗?
可以用感知器构建卷积神经网络吗?我在读一篇关于卷积神经网络的有趣文章。它显示了这幅图像,解释了对于5x5像素/神经元的每个感受野,计算一个隐藏值的值。 我们可以把max-pooling看作是网络询问给定特征是否在图像区域的任何地方找到的一种方式。然后它就会丢弃精确的位置信息。 因此应用了max-pooling。 我们将对每一个24×24隐藏的神经元使用相同的权重和偏差。 这也适用于隐藏层到池层,。对于max-pool层,它只是数
-
在神经网络中实现反向传播有困难
我有一个简单的前馈神经网络,有2个输入神经元(和1个偏置神经元),4个隐藏神经元(和1个偏置神经元),和一个输出神经元。前馈机制似乎运行良好,但我很难完全理解如何实现反向传播算法。 有3个班: 神经::网络;构建网络,前馈输入值(暂时没有反向传播) 神经::神经元;具有神经元的特性(指数、输出、权重等) 神经::连接;一个类似结构的类,它随机化权重并保存输出、增量权重等。 为了让事情更清楚,我上了
-
第五章 深度神经网络为何很难训练
假设你是一名工程师,接到一项从头开始设计计算机的任务。某天,你在工作室工作,设计逻辑电路,构建 $$AND$$ 门,$$OR$$ 门等等时,老板带着坏消息进来:客户刚刚添加了一个奇特的设计需求:整个计算机的线路的深度必须只有两层: 你惊呆了,跟老板说道:“这货疯掉了吧!” 老板说:“他们确实疯了,但是客户的需求比天大,我们要满足它。” 实际上,在某种程度上看,他们的客户并没有太疯狂。假设你可以使用
-
第三章 改进神经网络的学习方法(下)
权重初始化 结果表明,我们可以比使用正规化的高斯分布效果更好。为什么?假设我们使用一个很多的输入神经元,比如说 $$1000$$。假设,我们已经使用正规化的高斯分布初始化了连接第一隐藏层的权重。现在我将注意力集中在这一层的连接权重上,忽略网络其他部分: 我们为了简化,假设,我们使用训练样本 x 其中一半的神经元值为 $$0$$,另一半为 $$1$$。下面的观点也是可以更加广泛地应用,但是你可以从特
-
第三章 改进神经网络的学习方法(上)
当一个高尔夫球员刚开始学习打高尔夫时,他们通常会在挥杆的练习上花费大多数时间。慢慢地他们才会在基本的挥杆上通过变化发展其他的击球方式,学习低飞球、左曲球和右曲球。类似的,我们现在仍然聚焦在反向传播算法的理解上。这就是我们的“基本挥杆”——神经网络中大部分工作学习和研究的基础。本章,我会解释若干技术能够用来提升我们关于反向传播的初级的实现,最终改进网络学习的方式。 本章涉及的技术包括:更好的代价函数
-
文本情感分类:使用卷积神经网络(textCNN)
在“卷积神经网络”一章中我们探究了如何使用二维卷积神经网络来处理二维图像数据。在之前的语言模型和文本分类任务中,我们将文本数据看作是只有一个维度的时间序列,并很自然地使用循环神经网络来表征这样的数据。其实,我们也可以将文本当作一维图像,从而可以用一维卷积神经网络来捕捉临近词之间的关联。本节将介绍将卷积神经网络应用到文本分析的开创性工作之一:textCNN [1]。 首先导入实验所需的包和模块。 i