
可以用感知器构建卷积神经网络吗?

我在读一篇关于卷积神经网络的有趣文章。它显示了这幅图像,解释了对于5x5像素/神经元的每个感受野,计算一个隐藏值的值。
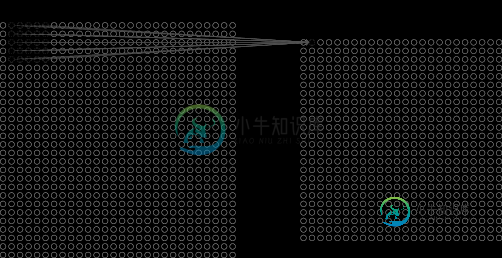
我们可以把max-pooling看作是网络询问给定特征是否在图像区域的任何地方找到的一种方式。然后它就会丢弃精确的位置信息。
因此应用了max-pooling。

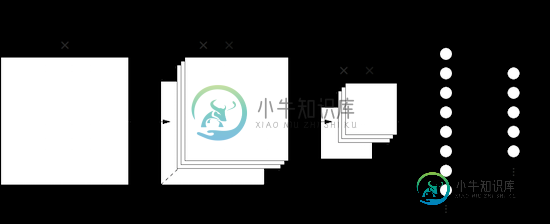
input_size = 5x5;
hidden_size = 10; e.g.
output_size = 1;

我们将对每一个24×24隐藏的神经元使用相同的权重和偏差。
这也适用于隐藏层到池层,input_size=2x2;output_size=1;。对于max-pool层,它只是数组上的max()函数。
然后最后:
-> 1 perceptron for every convolutional layer/feature map
-> run this perceptron for every receptive field to create feature map
-> 1 perceptron for every pooling layer
-> run this perceptron for every field in the feature map to create a pooling layer
-> finally input the values of the pooling layer in a regular ALL to ALL perceptron
共有1个答案

答案很大程度上取决于你所说的感知器。常见的选项有:
>
完整的体系结构。那就不是了,因为它的定义是不同的神经网络。
一个单个神经元的模型,特别是y=1,如果(w.x+b)>0,否则0,其中x是神经元的输入,w和b是神经元的可训练参数,w.b表示点积。然后是的,你可以强迫一堆这些感知器共享权重,并称之为一个CNN。你会发现这种思想的变体被用在二元神经网络中。
一种训练算法,通常与感知器体系结构相关联。这对问题没有意义,因为学习算法原则上与体系结构正交。虽然你不能真正使用感知器算法来处理任何有隐藏层的东西,但在这种情况下,答案是否定的。
与原始感知器关联的损失函数。这个Peceptron的概念正交于手边的问题,你的CNN的损失函数是由你对你的整个模型所做的任何事情给出的。您最终可以使用它,但它是不可微的,所以祝您好运:-)
旁白:你可以看到人们把前馈的、具有隐藏层的完全连接的神经网络称为“多层感知器”(MLPs)。这是一个错误的称呼,在MLP中没有感知器,参见维基百科上的讨论--除非你去探索一些非常奇怪的想法。将这些网络称为多层线性Logistic回归是有意义的,因为这就是它们过去的组成。直到六年前。
-
注意: 本教程适用于对Tensorflow有丰富经验的用户,并假定用户有机器学习相关领域的专业知识和经验。 概述 对CIFAR-10 数据集的分类是机器学习中一个公开的基准测试问题,其任务是对一组大小为32x32的RGB图像进行分类,这些图像涵盖了10个类别: 飞机, 汽车, 鸟, 猫, 鹿, 狗, 青蛙, 马, 船以及卡车。 想了解更多信息请参考CIFAR-10 page,以及Alex Kriz
-
卷积神经网络(Convolutional Neural Network, CNN)是一种前馈神经网络,它的人工神经元可以响应一部分覆盖范围内的周围单元,对于大型图像处理有出色表现。卷积神经网络由一个或多个卷积层和顶端的全连通层(对应经典的神经网络)组成,同时也包括关联权重和池化层(pooling layer)。这一结构使得卷积神经网络能够利用输入数据的二维结构。与其他深度学习结构相比,卷积神经网络
-
在了解了机器学习概念之后,现在可以将注意力转移到深度学习概念上。深度学习是机器学习的一个分支。深度学习实现的示例包括图像识别和语音识别等应用。 以下是两种重要的深度神经网络 - 卷积神经网络 递归神经网络 在本章中,我们将重点介绍CNN - 卷积神经网络。 卷积神经网络 卷积神经网络旨在通过多层阵列处理数据。这种类型的神经网络用于图像识别或面部识别等应用。CNN与其他普通神经网络之间的主要区别在于
-
主要内容:卷积神经网络深度学习是机器学习的一个分支,它是近几十年来研究人员突破的关键步骤。深度学习实现的示例包括图像识别和语音识别等应用。 下面给出了两种重要的深度神经网络 - 卷积神经网络 递归神经网络。 在本章中,我们将关注第一种类型,即卷积神经网络(CNN)。 卷积神经网络 卷积神经网络旨在通过多层阵列处理数据。这种类型的神经网络用于图像识别或面部识别等应用。 CNN与任何其他普通神经网络之间的主要区别在于CNN
-
注意: 本教程适用于对Tensorflow有丰富经验的用户,并假定用户有机器学习相关领域的专业知识和经验。 概述 对CIFAR-10 数据集的分类是机器学习中一个公开的基准测试问题,其任务是对一组32x32RGB的图像进行分类,这些图像涵盖了10个类别: 飞机, 汽车, 鸟, 猫, 鹿, 狗, 青蛙, 马, 船以及卡车。 想了解更多信息请参考CIFAR-10 page,以及Alex Krizhev
-
在“多层感知机的从零开始实现”一节里我们构造了一个含单隐藏层的多层感知机模型来对Fashion-MNIST数据集中的图像进行分类。每张图像高和宽均是28像素。我们将图像中的像素逐行展开,得到长度为784的向量,并输入进全连接层中。然而,这种分类方法有一定的局限性。 图像在同一列邻近的像素在这个向量中可能相距较远。它们构成的模式可能难以被模型识别。 对于大尺寸的输入图像,使用全连接层容易造成模型过大