《就业》专题
-
 前端 - 为什么vue3中img引入的相对路径图片,开发环境中正常显示,vite打包后路径就变成了object?
前端 - 为什么vue3中img引入的相对路径图片,开发环境中正常显示,vite打包后路径就变成了object? -
就文件夹结构而言,Google App Engine应用程序中的默认服务/模块是否可以是非默认服务/模块的兄弟?
问题内容: 更新:这些天modules被称为services。 我想将项目的模块组织到各个子文件夹中,其中每个子文件夹都包含与每个模块相关的代码。特别是,我希望包含默认模块的文件夹与其他模块处于同一级别(即,它们都是同级的)。我遵循模块文档中显示的图: 图 (来源:google.com) 但是,令我感到困惑的是“重要提示:app.yaml文件必须位于应用程序的根目录中”。这是否意味着默认模块(及其
-
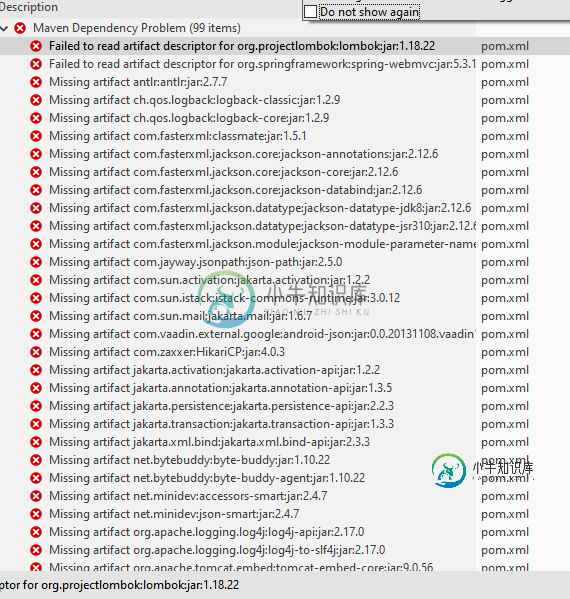 我从一开始就在一个新的项目中遇到了maven依赖性问题。Spring木卫一。我怎样才能解决这个问题?
我从一开始就在一个新的项目中遇到了maven依赖性问题。Spring木卫一。我怎样才能解决这个问题?我没有碰过pom文件中的任何东西。新项目显示了99个maven依赖问题。我通过添加各种依赖项,如Lombok、Spring data jpa、java mail、Spring web等,从start.spring.io生成了这个项目。为什么我会得到这个,我该如何解决这个问题?我在没有构建标签的情况下附加了pom,因为我在发布这个问题时出错了。
-
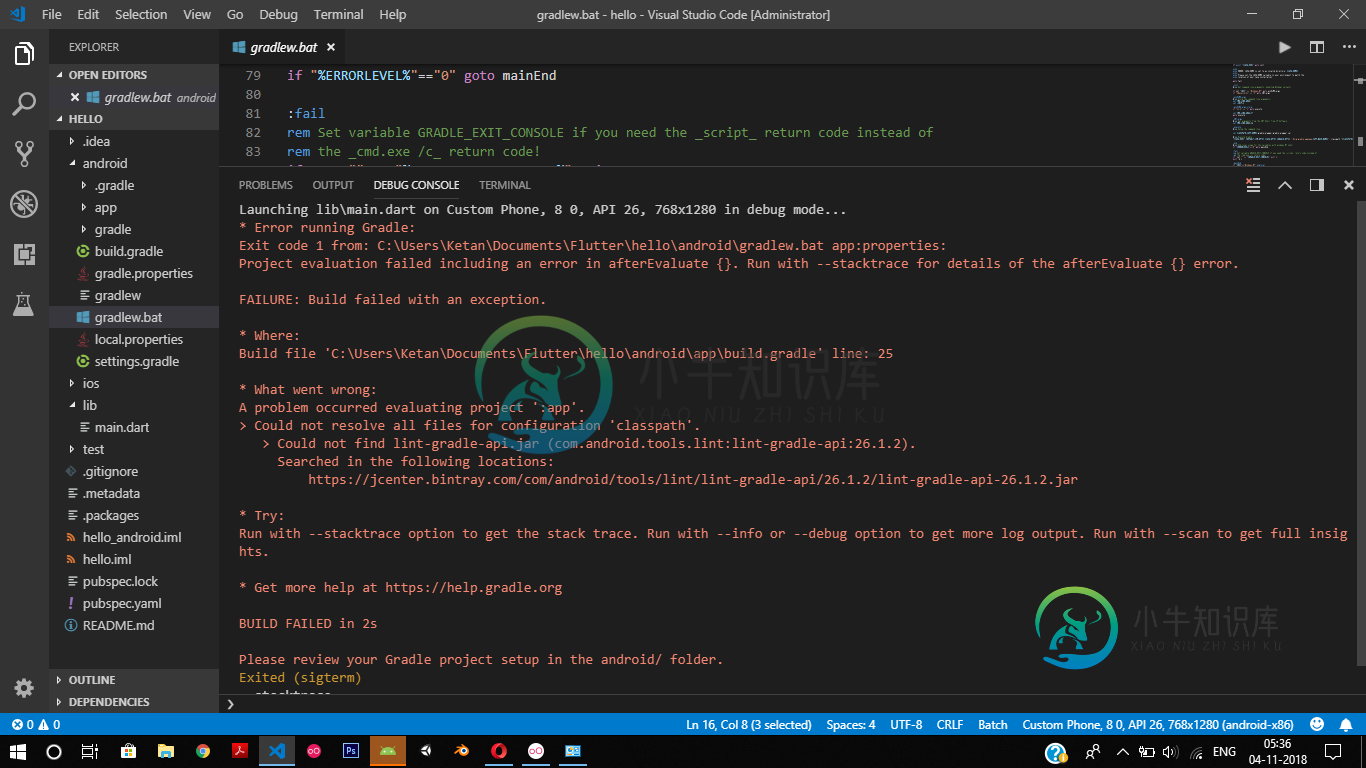 我无法在VS代码中运行和调试颤振应用程序,每当我尝试运行它时,就会出现以下错误[重复]
我无法在VS代码中运行和调试颤振应用程序,每当我尝试运行它时,就会出现以下错误[重复]我使用的是颤振0.9。4•频道测试版 每当我尝试调试并运行我的应用程序时,它都会显示以下错误消息:
-
 前端 - 使用vue-pdf本地浏览器使用chrome移动机型可以正常预览,但是到了线上就无法正常预览了?
前端 - 使用vue-pdf本地浏览器使用chrome移动机型可以正常预览,但是到了线上就无法正常预览了?线上打开pdf:pdf文件请求返回<html><body><!-- no enabled plugin supports this MIME type --></body></html>预览效果如下: 而本地效果如下: pdf文件返回正常: 使用的chrome的模拟机型均为iphoneX,请问有大佬遇到过这种问题吗
-
前端 - openlayers中设置的图片,为什么在地图层级小于9的时候,才能显示出图片,大于9 就不显示了??
openlayers 中设置的图片图层,为什么在地图层级小于9的时候,才能显示出图片,大于9 就不显示了?? 地图设置 希望不管zoom多少,都能显示图片 希望不管zoom为多少,都能显示图片
-
vue.js - vite怎么做到创建一个组件就能在网页中查看呢,不用在App.vue里引入使用才能显示到页面上?
写一个组件还得在App.vue里面使用才能显示到页面上太麻烦了,直接创建一个组件文件夹就能在页面上查看了最方便
-
java - springboot项目中,用atomikos做的多数据源配置,某一个数据库,白天的时候访问非常慢,深夜访问就正常?
项目连接了3个数据库,分别是 base1,base2,base3; base1,base2白天晚上访问都正常; base3,白天访问大部分都是超时,偶尔能通,还非常慢,到了晚上就可以正常访问了; 三个数据库数据结构,接口配置一模一样,只是用来区分不同的国家而已; 因为做了实时大屏看板,所以会频繁的请求该项目,并且会不停的切换数据源;会不会是数据源的通用配置有点小了? 数据源的通用配置如下: Ato
-
近期有一款社交APP横空而出,那就是来自罗永浩的子弹短信,短短几天,用户注册量就达到了近千万级别,且相关话题热度一直高居不下,从市场营销的角度,你认为这种爆发式的产品增长的原因是什么?
本文向大家介绍近期有一款社交APP横空而出,那就是来自罗永浩的子弹短信,短短几天,用户注册量就达到了近千万级别,且相关话题热度一直高居不下,从市场营销的角度,你认为这种爆发式的产品增长的原因是什么?相关面试题,主要包含被问及近期有一款社交APP横空而出,那就是来自罗永浩的子弹短信,短短几天,用户注册量就达到了近千万级别,且相关话题热度一直高居不下,从市场营销的角度,你认为这种爆发式的产品增长的原因
-
无法使用std::function作为参数类型(需要函数指针版本)宁愿像STL一样模板,但这样它就无法推断参数
以下代码在Coliru上使用其默认编译参数进行了所有尝试 g-std=c 17-O2-Wall-docantic-pthread-main.cpp 假设我们想制作一个保存数据“容器”的包装器(例如,向量、列表、任何保存一个可以模板化的值的数据结构)。然后,稍后我们要使用助手函数将其转换为另一种类型。这个函数可以被多次调用,只需编写<代码>转换(…) ,而不是像转换 还假设我们有这个(请注意,类似于
-
在Java中,使用扫描器从.txt文件中读取数据,这样我就可以用该数据作为构造函数参数生成对象
我有一个.txt文件,其内容具有以下格式: 基本上,第一行是费用对象的名称,第二行是费用对象的成本,第三行是费用对象的频率。我的文本文件是按照这种格式重复的三行。我可以使用扫描器将所有这些行存储到一个列表中,但由于某种原因,我的代码没有正确生成费用对象。创建支出对象时,我的构造函数将字符串expenseName、int expenseCost和int expenseFreq作为参数。但是,在调试之
-
powershell——构建一个非空字符串的动态变量,然后检查这个动态变量,只要不是空的,就在前面加上字符
我试图动态构建一个包含字符串的变量。然后我要检查这个新变量,如果它不是空的,请在“;”前面加上“;”添加到每个添加的字符串。 基本上,我正在构建一个Set-ADUser-Replace@{DynamicVarialble}命令,并希望动态变量最多包含三个不同的值,但只包含那些不为空或null的值。如果它是字符串中的第一个值,请不要在“;”前面添加它。所以结果如下: < code > Set-ADU
-
一旦创建了三个单声道,就并行执行它们,等待所有单声道完成,并以特定的顺序/逻辑收集结果
我是SpringWebFlux的新手,所以请温柔一点。。。我很抱歉,如果我错过了一些明显的东西,但我试图寻找在线的例子,每次我结束与顺序调用。 我有这样的情况: 响应是我的项目中的一个类,但是对于这个例子,我们可以将它们视为单个列表的简单容器。 我想: 并行执行它们(一旦我将它们分配给单数1/单数2/单数3,通过调用。 当一切都完成后,保存响应,以呼吸1,呼吸2,呼吸3 如果res1有结果(列表不
-
使用 Keras 进行迁移学习,验证准确性从一开始就没有提高(超出幼稚的基线),而训练准确性提高了
我正在为Food-101数据集构建分类器(图像数据集w/101类,每个类1k图像)。我的方法是使用Keras和ResNet50(来自imagenet的权重)进行转移学习。 当训练模型时,训练精度在几个时期内得到适度提高(30%)-- 当我查看模型在验证集上所做的预测时,它始终是同一类。 我的感觉是,该模型并没有过度拟合到如此糟糕的程度,以致于无法解释验证精度中缺乏变化的原因。 如有任何建议,以提高
-
从整数数组中找到一个大小为K的连续子数组,这样从1到K的附加元素就永远不会低于零
给定大小为n的未排序整数数组。我们需要找出所有大小为k(n>k)的连续子数组,这样,在子数组中,如果我们一直将元素从1加到k,总和就永远不会低于零。例如,1,-3,4,-2,6,-5(n=6,k=3)这里的条件由一个子数组传递。(总和无关紧要)1,-3,4 -3,4,-2 4,-2,6传递-2,6,-5