《同花顺面试》专题
-
MongoDB查询检索数据花费太多时间
我收集了300万份文件,索引如下: {ts:1},{u\u id:1} 请注意,这是两个单独的升序索引,而不是复合索引。 当我运行此查询时: db.collection.find({u_id:'user'})。排序({ts:-1})。跳过(0)。限制(1) 需要100毫秒。我有以下日志: 2017-04-15T06:42:01.147 0000 I命令[conn783]查询。集合查询:{order
-
错误火花流中重载的方法值createDirectStream
在调用参数化版本的CreateStream时,我也会遇到类似的错误。 你知道有什么问题吗?
-
Vertx客户端正在花时间检查故障
我有一个要求,我通过Vertx客户端将一个微服务连接到其他微服务。在代码中,我正在检查另一个微服务是否关闭,然后在失败时它应该创建一些JsonObject,其中solrError为键,失败消息为值。如果有solr错误,我的意思是如果其他微服务关闭,通过负载平衡调用solr,那么它应该会抛出一些错误响应。但是Vertx客户端需要一些时间来检查失败,当条件被检查时,jsonject中没有solrErr
-
在火花scalaGroupByKey($"coll")和GroupBy($"coll")之间的区别
当我使用DF的列名作为参数时,与使用和有什么根本区别? 哪一个是省时的,每一个的确切含义是什么?当我通过一些例子时,请有人详细解释一下,但这是令人困惑的。
-
火花2。x数据帧或数据集?[副本]
我的理解是Spark 1之间的一个重大变化。x和2。x是从数据帧迁移到采用更新/改进的数据集对象。 但是,在所有Spark 2. x文档中,我看到正在使用,而不是。 所以我问:在Spark 2. x中,我们是否仍在使用,或者Spark人员只是没有更新那里的2. x文档以使用较新的推荐的?
-
并行化步骤中的火花内存错误
我们正在使用最新的Spark构建。我们有一个非常大的元组列表(8亿)作为输入。我们使用具有主节点和多个工作节点的docker容器运行Pyspark程序。驱动程序用于运行程序并连接到主机。 运行程序时,在sc.parallelize(tuplelist)行,程序要么退出并显示java堆错误消息,要么完全退出而不出错。我们不使用任何Hadoop HDFS层,也不使用纱线。 到目前为止,我们已经考虑了这
-
火花-如何从时间戳中提取小时?
请帮助理解为什么不提取为8:15am? W3C日期和时间格式 示例1994-11-05T08:15:30-05:00对应于美国东部标准时间1994年11月5日上午8:15:30。 用于格式化和解析的日期时间模式
-
在火花scala中使用结构创建模式
我是scala新手,尝试从元素数组中创建自定义模式,以读取基于新自定义模式的文件。 我正在从json文件中读取数组,并使用爆炸方法为列数组中的每个元素创建了一个数据框。 获得的输出为: 现在,对于上面列出的所有值,我尝试使用下面的代码动态创建val模式 上面的问题是,我能够在struct中获取数据类型,但我也希望仅为数据类型decimal获取(scale和preicion),其限制条件为max a
-
从火花DataFrame在elasticsearch中索引嵌套字段
假设我有一张这样的桌子: 它以拼花地板的形式存储。我需要在spark中读取表,在“field1”上执行groupBy,然后我需要在ES中存储一个嵌套字段(例如,称为“agg\u字段”),其中包含一个字典列表,其中包含字段2和字段3的值,这样文档将如下所示: 我可以阅读表格并进行分组: 我可以做一些聚合并将结果发送给es: 但我不知道如何将聚合更改为嵌套的“agg\u fields”列,该列将被el
-
如何在Apache火花爆炸JSON数组[重复]
给定一个spark 2.3数据帧,其中一列包含JSON数组,如何将其转换为JSON字符串的spark数组?或者,等效地,我如何分解JSON,以便输入: 我得到: 非常感谢! p、 数组中条目的形状是可变的。 下面是一个示例输入,如果它是有用的: p. p. s.这不同于迄今为止所有建议的重复问题。例如,如何使用火花数据帧查询JSON数据列?的问题和解决方案适用于(1)数据是所有JSON数据,因此整
-
火花:阿夫罗与镶木地板的表现
现在Spark 2.4已经内置了对Avro格式的支持,我正在考虑将数据湖中某些数据集的格式从Parquet更改为Avro,这些数据集通常是针对整行而不是特定列聚合进行查询/联接的。 然而,数据之上的大部分工作都是通过Spark完成的,据我所知,Spark的内存缓存和计算是在列格式的数据上完成的。在这方面,Parquet是否提供了性能提升,而Avro是否会招致某种数据“转换”损失?在这方面,我还需要
-
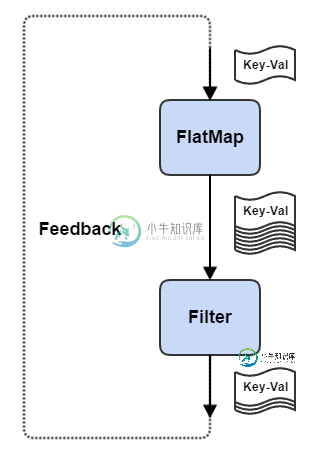 火花流:如何将输出反馈到输入
火花流:如何将输出反馈到输入更新:为了迭代支持,我不得不转向Flink流。不过还是会和Kafka试试看!
-
使用NiFi从s3桶中读取拼花数据
伙计们! 我才刚开始学NiFi。不要扔石头)只是帮助或引导。我需要从s3桶读取拼花地板数据,我不知道如何设置lists3和FetchS3对象处理器来读取数据。完整路径如下所示:s3://inbox/prod/export/date=2022-01-07/user=100/2022-01-09 06:51:23 23322557 cro。我将把数据写入sql数据库——我没有问题。 我试着自己配置li
-
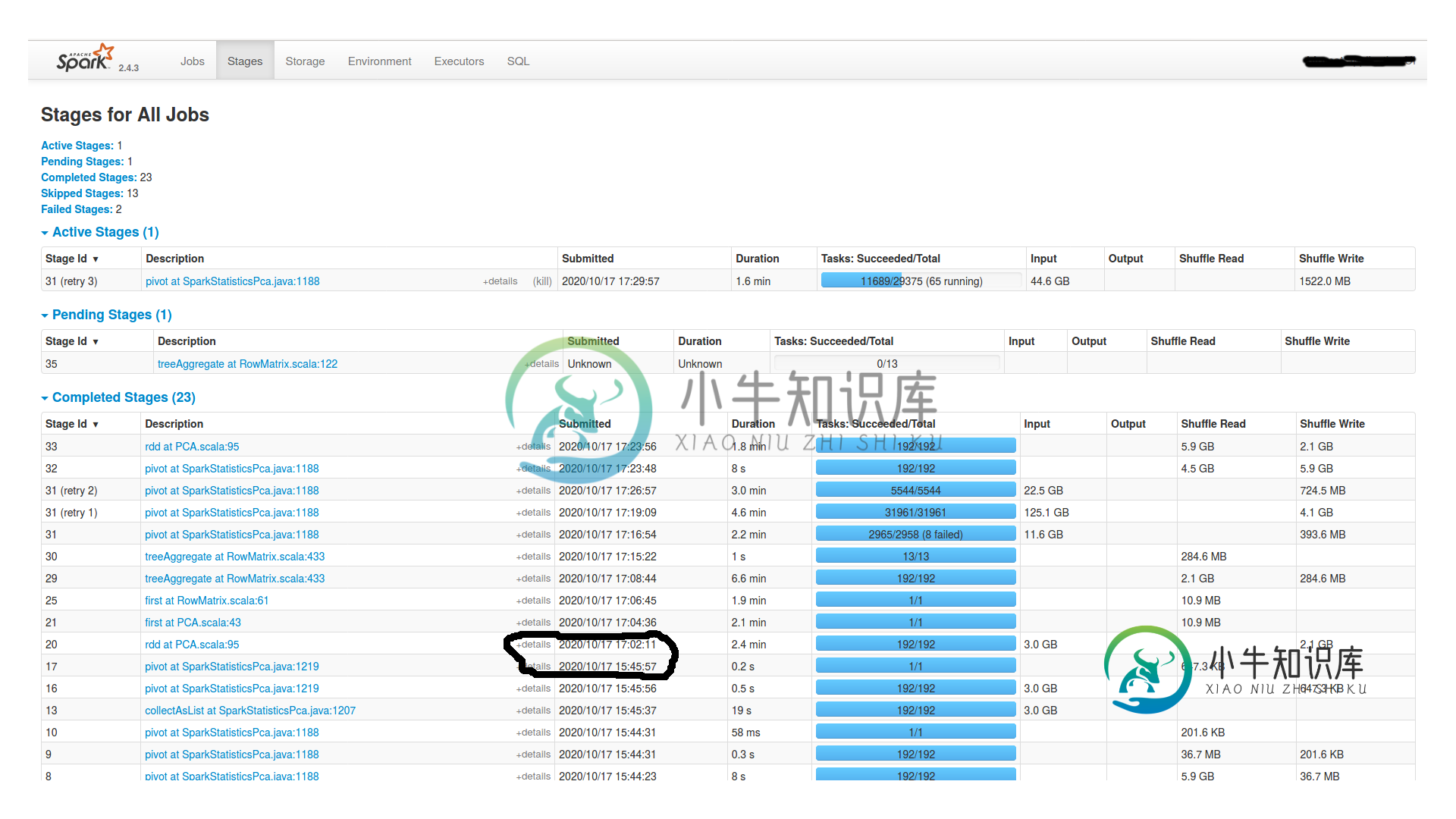 火花工作之间的巨大时间间隔
火花工作之间的巨大时间间隔我创建并持久化一个df1,然后在其上执行以下操作: 我有一个有16个节点的集群(每个节点有1个worker和1个executor,4个内核和24GB Ram)和一个master(有15GB Ram)。Spark.shuffle.Partitions也是192个。它挂了2个小时,什么也没发生。Spark UI中没有任何活动。为什么挂这么久?是dagscheduler吗?我怎么查?如果你需要更多的信息
-
无法注册kafka雪花连接器的架构
分布式服务已成功启动:[2021 10月17日18:04:29693]信息已启动o.e.j.s.ServletContextHandler@1422ac7f{/,null,AVAILABLE}(org.eclipse.jetty.server.handler.ContextHandler:916)[2021 10月17日18:04:29693]初始化信息REST资源;服务器已启动并准备好处理请求(