
火花流:如何将输出反馈到输入

更新:为了迭代支持,我不得不转向Flink流。不过还是会和Kafka试试看!
共有1个答案

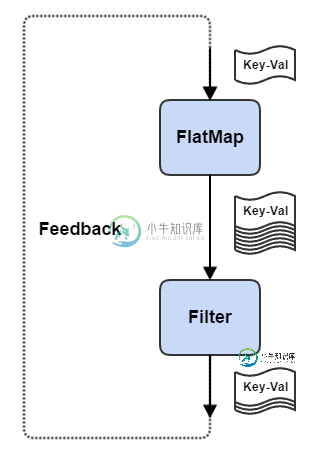
使用Apache Flink,可以通过iterateAPI调用定义反馈边。iterate方法需要一个步进函数,在给定输入流的情况下,该函数产生一个反馈流和一个输出流。前一个流反馈给步进函数,后一个流发送给下游操作员。
一个简单的示例如下:
scala prettyprint-override">val env = StreamExecutionEnvironment.getExecutionEnvironment
val input = env.fromElements(1).map(x => (x, math.random))
val output = input.iterate {
inputStream =>
val iterationBody = inputStream.flatMap {
randomWalk =>
val (step, position) = randomWalk
val direction = 2 * (math.random - 0.5)
val bifurcate = math.random >= 0.75
Seq(
Some((step + 1, position + direction)),
if (bifurcate) Some((step + 1, position - direction)) else None).flatten
}
val feedback = iterationBody.filter {
randomWalk => math.abs(randomWalk._2) < 1.0
}
val output = iterationBody.filter {
randomWalk => math.abs(randomWalk._2) >= 1.0
}
(feedback, output)
}
output.print()
// execute program
env.execute("Random Walk with Bifurcation")
在这里,我们计算一个随机游走,我们随机地分割我们的游走,以向相反的方向前进。如果随机游动的绝对位置值大于或等于1.0,则随机游动完成。
-
我正在从一个消息应用程序收集数据,我目前正在使用Flume,它每天发送大约5000万条记录 我希望使用Kafka,使用Spark Streaming从Kafka消费并将其持久化到hadoop并使用impala进行查询 我尝试的每种方法都有问题。。 方法1-将RDD另存为parquet,将外部配置单元parquet表指向parquet目录 问题是finalParquet.saveAsParquetF
-
null 触发器是否支持一次追加模式? 这里有一个最小的应用程序来再现这个问题。要旨
-
交互式应用程序通常要分别用类 istream 和 ostream 输入和输出数据。当提示信息出现在屏幕上时,用户输入一个数据来响应。显然,提示信息必须在执行输入操作前出现。在有输出缓冲区的情况下,只有在缓冲区已满时、在程序中明确地刷新输出缓冲区时或因程序结束而自动刷新输出缓冲区时,输出信息才会显示到屏幕上。为保证输出要在下一个输入前显示,C++ 提供了成员函数tie,该函数可以实现输入/输出操作的
-
本小节将会介绍基本输入输出的 Java 标准类,通过本小节的学习,你将了解到什么是输入和输入,什么是流;输入输出流的应用场景,File类的使用,什么是文件,Java 提供的输入输出流相关 API 等内容。 1. 什么是输入和输出(I / O) 1.1 基本概念 输入/输出这个概念,对于计算机相关专业的同学并不陌生,在计算中,输入/输出(Input / Output,缩写为 I / O)是信息处理系
-
Kafka流中是否内置了允许将单个输入流动态连接到多个输出流的功能?允许基于true/false谓词进行分支,但这不是我想要的。我希望每个传入日志都确定它将在运行时流到的主题,例如,日志将流到主题和日志将流到主题。 我可以在流中调用,然后写给Kafka制作人,但这似乎不是很好。在Streams框架中是否有更好的方法来实现这一点?
-
我想用java代码调用一个外部程序,然后Google告诉我Runtime或ProcessBuilder可以帮助我完成这项工作。我试过了,结果发现java程序无法退出,这意味着子进程和父进程都将永远等待。它们要么挂起,要么陷入僵局。 有人告诉我原因是子进程的缓存太小了。当它试图将数据返回给父进程时,但是父进程没有及时读取它,然后他们两个都挂起了。所以他们建议我叉一个线程来负责读取子进程的缓存数据。我