《同花顺校招》专题
-
如果还在火花流中
谢谢。
-
火花工和执行器芯
我有一个Spark集群运行在hdfs之上的纱线模式。我启动了一个带有2个内核和2G内存的worker。然后我提交了一个具有3个核心的1个执行器动态配置的作业。不过,我的工作还能运转。有人能解释启动worker的内核数量和为执行者请求的内核数量之间的差异吗。我的理解是,由于执行者在工人内部运行,他们无法获得比工人可用的资源更多的资源。
-
火花流和高可用性
我正在构建作用于多个流的Apache Spark应用程序。 我确实阅读了文档中的性能调优部分:http://spark.apache.org/docs/latest/streaming-programming-guide.html#performan-tuning 我没有得到的是: 1)流媒体接收器是位于多个工作节点上,还是位于驱动程序机器上? 2)如果接收数据的节点之一失败(断电/重新启动)会发
-
用TTL节省Cassandra的火花
我正在使用Spark-Cassandra连接器1.1.0和Cassandra 2.0.12。 谢谢, 沙伊
-
 Java实现雪花算法(snowflake)
Java实现雪花算法(snowflake)本文向大家介绍Java实现雪花算法(snowflake),包括了Java实现雪花算法(snowflake)的使用技巧和注意事项,需要的朋友参考一下 本文主要介绍了Java实现雪花算法(snowflake),分享给大家,具体如下: 简单描述 最高位是符号位,始终为0,不可用。 41位的时间序列,精确到毫秒级,41位的长度可以使用69年。时间位还有一个很重要的作用是可以根据时间进行排序。注意,41位时
-
扩展Node.js类时花括号
问题内容: 为什么在扩展Node.js类时将变量包装在大括号内,例如? 例如,Trevor Burnham在他的事件驱动CoffeeScript 教程中,通过以下方式扩展了Node的EventEmitter: 问题答案: 这个: 等效于以下JavaScript: 当您使用模块的导出返回一个对象时,这些导出之一就是“类”。使用只是退出返回对象的惯用快捷方式。您也可以这样说: 若你宁可。当您要提取对象
-
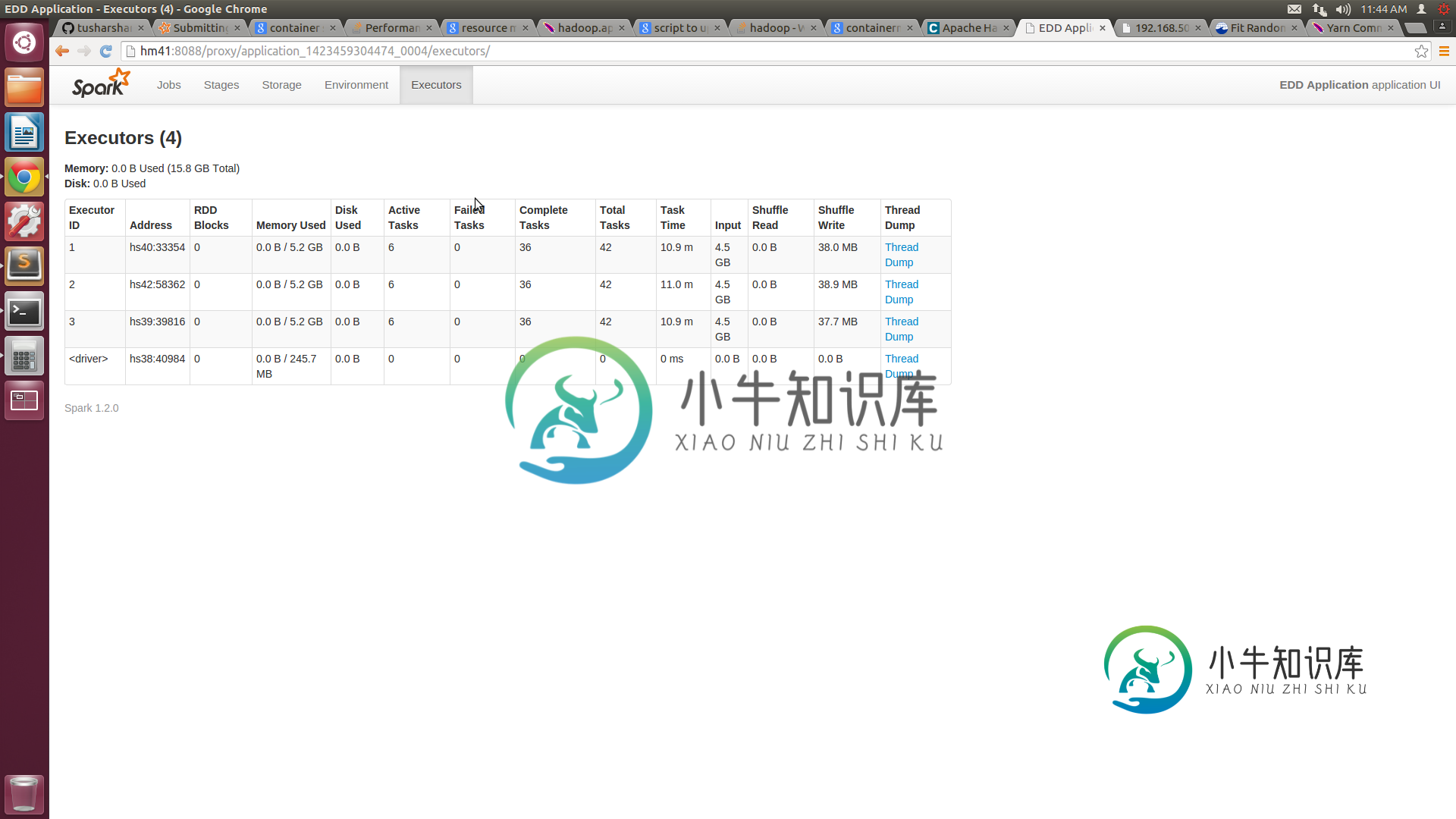 火花线的性能问题
火花线的性能问题我们正在尝试在纱线上运行我们的火花集群。我们有一些性能问题,尤其是与独立模式相比。 我们有一个由5个节点组成的集群,每个节点都有16GB的RAM和8个核心。我们已将纱线站点中的最小容器大小配置为3GB,最大为14GB。xml。向纱线集群提交作业时,我们提供的执行器数量=10,执行器内存=14 GB。根据我的理解,我们的工作应该分配4个14GB的容器。但spark UI仅显示3个容器,每个容器的容量
-
JS实现放烟花效果
本文向大家介绍JS实现放烟花效果,包括了JS实现放烟花效果的使用技巧和注意事项,需要的朋友参考一下 本文实例为大家分享了JS实现放烟花效果的具体代码,供大家参考,具体内容如下 move.js 更多JavaScript精彩特效分享给大家: Javascript菜单特效大全 javascript仿QQ特效汇总 JavaScript时钟特效汇总 以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大
-
Kafka连接S3-JSON到拼花
Kafka是否将S3支持从JSON连接到Parquet?感谢使用Kafka Connect S3提供的可用和替代建议
-
引发异常的火花sortby
我正在尝试按键对JavaPairRDD进行排序。 块引号
-
Spark dataframe CSV vs拼花地板
我是Spark的初学者,试图理解Spark数据帧的机制。当从csv和parquet加载数据时,我比较了spark sql dataframe上sql查询的性能。我的理解是,一旦数据加载到spark数据框中,数据的来源(csv或parquet)应该无关紧要。然而,我看到了两者之间的显著性能差异。我使用以下命令加载数据,并对其编写查询。 请解释差异的原因。
-
火花createDataFrame()不使用Seq RDD
CreateDataFrame接受2个参数,一个rdd和模式。 我的图式是这样的 <代码>val schemas=结构类型(Seq(StructField(“number”,IntegerType,false),StructField(“notation”,StringType,false))) 在一种情况下,我能够从RDD创建数据帧,如下所示: 在以下其他情况下。。我不能 data2不能成为Da
-
火花内存不足错误
我的spark程序在小数据集上运行良好。(大约400GB)但是当我将其扩展到大型数据集时。我开始得到错误
-
CountVectorizerModel错误与apache火花-JavaAPI
我正在使用Apache Spark的示例代码follow文档:https://spark.apache.org/docs/latest/ml-features.html#countvectorizer 但我收到错误消息: 22年10月15日23:04:20信息BlockManagerMaster:使用703.6 MB RAM注册block manager localhost:56882,Block
-
火花数据帧滤波器
我想过滤掉具有“c2”列前3个字符的记录,无论是“MSL”还是“HCP”。 所以输出应该如下所示。 有谁能帮忙吗? 我知道df。过滤器($c2.rlike(“MSL”))--用于选择记录,但如何排除记录? 版本:Spark 1.6.2 Scala:2.10