《高途》专题
-
高级: 第三方工具
注意: 这些工具并没有经过Gitea的检验,在这里列出它们只是为了便捷. 此列表并不是完整的列表,可以随时咨询如何添加! 持续集成 BuildKite 连接器 Jenkins 插件 Gitea搭配Drone 迁移 Gitea安装脚本 GitHub迁移 移动端 安卓客户端GitNex 编辑器扩展 Gitea的Visual Studio扩展 从 Visual Studio 扩展市场 下载
-
第3章 高级主题
设计软件有两种方法:一种是简单到明显没有缺陷,另外一种复杂到缺陷不那么明显。——托尼.霍尔 在学习了前面第2章的基础入门后,已经可以能够胜任一般性的接口服务功能开发,和应付根据项目具体情况而定制扩展的业务场景。但实际上项目的开发要更为复杂,相应地,我们需要学习更为强大的工具。例如对各种后端资源服务的管理,类文件的命名规范和自动加载,以及架构明显的编程风格。除此之外,本章还会包含更高层面、更广范畴上
-
UMD™ Cache(高速缓存)
UMD™ Cache(高速缓存) 将使用频率较高的数据蓄积至PSP™主机的内存,以减少UMD™的读取次数,加快数据读取速度的设定。 关 不变更UMD™的读取速度。 开 减少UMD™的读取频率。 提示 设定为[开]时,可能无法经由Ad Hoc模式与其他PSP™正确通讯。此时请调整为[关]。
-
17. 高效编码举例
下面的例子尽管有些不太现实,但却有可能实现与有噪声信道的完全匹配。 存在两个信道符号0和1,噪声对七个该等符号组成的块产生影响。一组七个符号要么无错误传送,要么恰有一个符号错误。这八种可能性是等概率的。有: 下面给出一种高效编码,它能够完全纠正所有错误,并以速率C进行传送(此种编码方式是由R.汉明发明的一种方法发现的): 设一组七个符号为。其中的为消息符号,由信源任何选择。其他三个为冗余,其计算如
-
1.9 高级队列功能
多读者/Tag createTag() deleteTag() listTag() getTagInfo() 死信队列 setQueueRedrivePolicy() removeQueueRedrivePolicy() 从死信队列中接收消息 向死信队列发送消息 多读者/Tag相关 Topic Queue Priority Queue
-
提高 After Effects 的性能
您可以通过优化您的计算机系统、After Effects、您的项目和您的工作流程来改进性能。此处提供的某些建议不是通过提高渲染速度而是通过降低其他操作(例如,打开项目)所需的时间来改进性能的。 注意:到目前为止,用来改进总体性能的最好方法是提前规划、针对您的工作流程和输出管道运行早期测试、并确认您所提供的内容是您的客户实际需要和预期的内容。(请参阅规划您的工作。) Lloyd Alvarez 在
-
2.1. 高斯混合模型
校验者: @why2lyj @Shao Y. 翻译者: @glassy sklearn.mixture 是一个应用高斯混合模型进行非监督学习的包,支持 diagonal,spherical,tied,full 四种协方差矩阵 (注:diagonal 指每个分量有各自不同对角协方差矩阵, spherical 指每个分量有各自不同的简单协方差矩阵, tied 指所有分量有相同的标准协方差矩阵, ful
-
高级分支与合并
在合并过程中得到解决冲突的协助 git会把所有可以自动合并的修改加入到索引中去, 所以git diff只会显示有冲突的部分. 它使用了一种不常见的语法: $ git diff diff --cc file.txt index 802992c,2b60207..0000000 --- a/file.txt +++ b/file.txt @@@ -1,1 -1,1 +1,5 @@@ ++<<<<<<<
-
2.1. Python 高级功能(Constructs)
这一章是关于Python语言的高级特性 -- 从不是每种语言都有这些特性的角度来说,也可以从他们在更复杂的程序和库中更有用这个角度来说,但是,并不是说特别专业或特别复杂。 需要强调的是本章是纯粹关于语言本身 -- 关于由特殊语法支持的特性,用于补充Python标准库的功能,聪明的外部模块不会实现这部分特性。 开发Python程序语言的流程、语法是非常透明的。提议的修改会通过Python增强建议-P
-
Tea-代码高亮设置
本文面向准备为编辑器添加 Tea 语法高亮功能的读者。 扩展名 Tea 语言代码的默认扩展名名 .tea 。包文件为 .teapkg。 项目文件为 .teaproj 。 数据文件为 .teadata 。 高亮策略 1. 数字 数字格式只有这三种:1、-0.3、0x1。 2. 字符串 字符串的格式只有这三种:'这是没有任何转义的字符串,字符串内部用''代替'、"这是支持\转义的字符串,转义的情况和J
-
 小米高性能计算
小米高性能计算👥面试题目 一面 项目 cuda详细说(好久了有的忘记了说的磕磕巴巴的) 然后 讲了实习的东西 感觉和他们目前的业务比较match 基础问题 c加加和cuda的基础问题 一个膨胀卷积实现的手撕 呃问我怎么优化 没回答出来 给我讲解了我还是没明白 笑死 面试官无语 反问 两轮技术面 技术业务偏向移动端硬件优化这边 面试官比较友好 亲切 没开摄像头 希望可以进二面 跪求
-
 太初 高性能 一面
太初 高性能 一面太初好像也能给3,冲一波 面试时长:40min 面试内容: * 自我介绍 * 实习介绍 * linux信号 * 信号量的处理 * 死锁条件、解决 * 多线程库用过哪些 * gil锁 * auto和decltype * delete和private * static用法 * 单例模式 * unique_ptr原理 * std::move原理 * 智能指针 * cuda如何优化 * AI框架了解哪些优
-
 Kafka高性能设计-3
Kafka高性能设计-3主要内容:1.消费消息的性能优化手段,2.消费者组1.消费消息的性能优化手段 1.1 稀疏索引 Kafka 利用offset 和 timestamp 查到消息。 B Tree 类的索引并不适用于 Kafka。哈希索引看起来却非常合适。 为了加快读操作,如果只需要在内存中维护一个「从 offset 到日志文件偏移量」的映射关系即可,每次根据 offset 查找消息时,从哈希表中得到偏移量,再去读文件即可。(根据 timestamp 查消息也可以采用
-
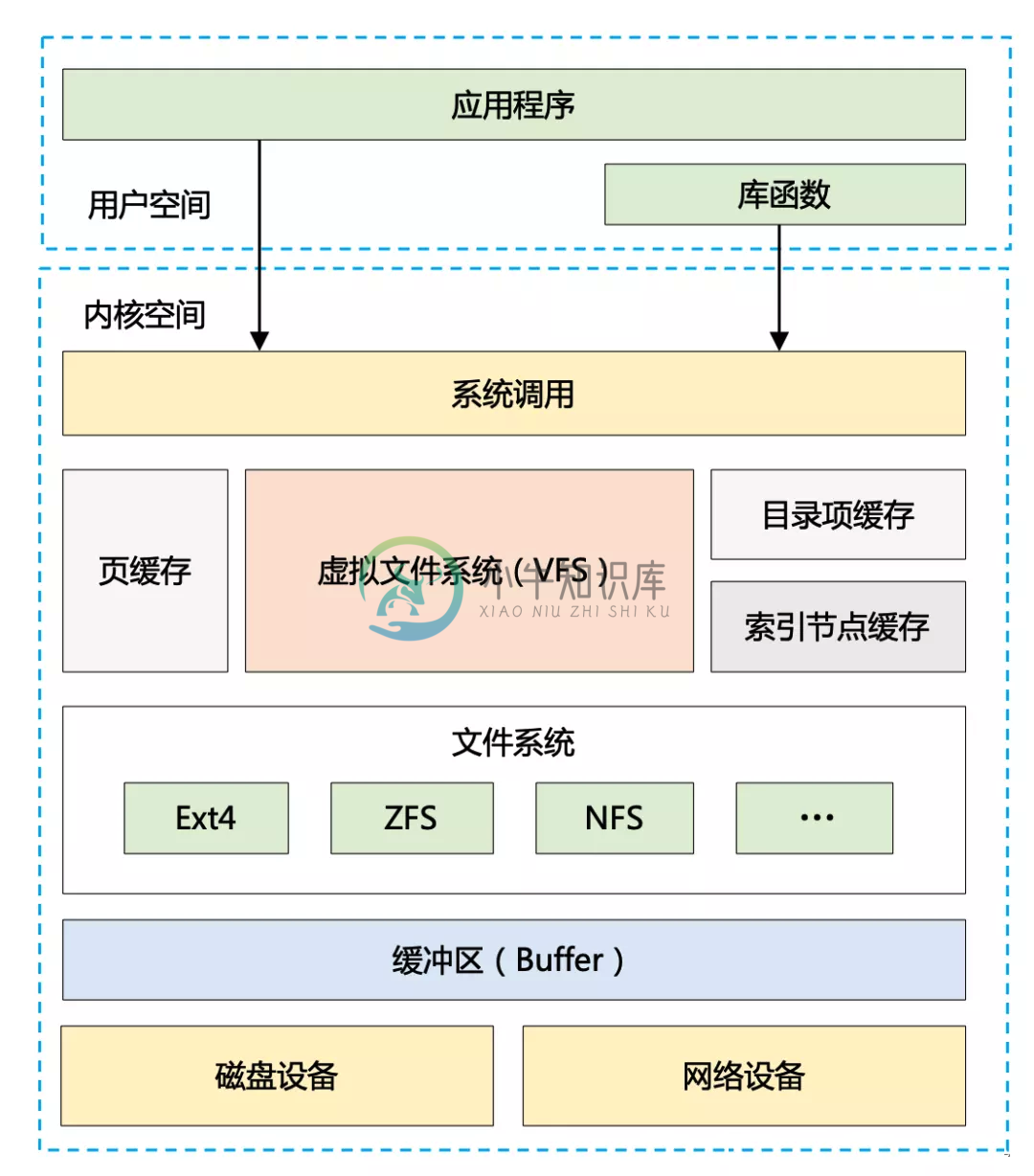
 Kafka高性能设计-2
Kafka高性能设计-2主要内容:1. 存储消息的性能优化手段1. 存储消息的性能优化手段 存储消息属于 Broker 端的核心功能 IO多路复用, 磁盘顺序写, page缓存, 分区分段结构 1.1 IO 多路复用 对于 Kafka Broker 来说,要做到高性能,首先要考虑的是:设计出一个高效的网络通信模型,用来处理它和 Producer 以及 Consumer 之间的消息传递问题。 SocketServer : Kafka采用的是Reactor 网络
-
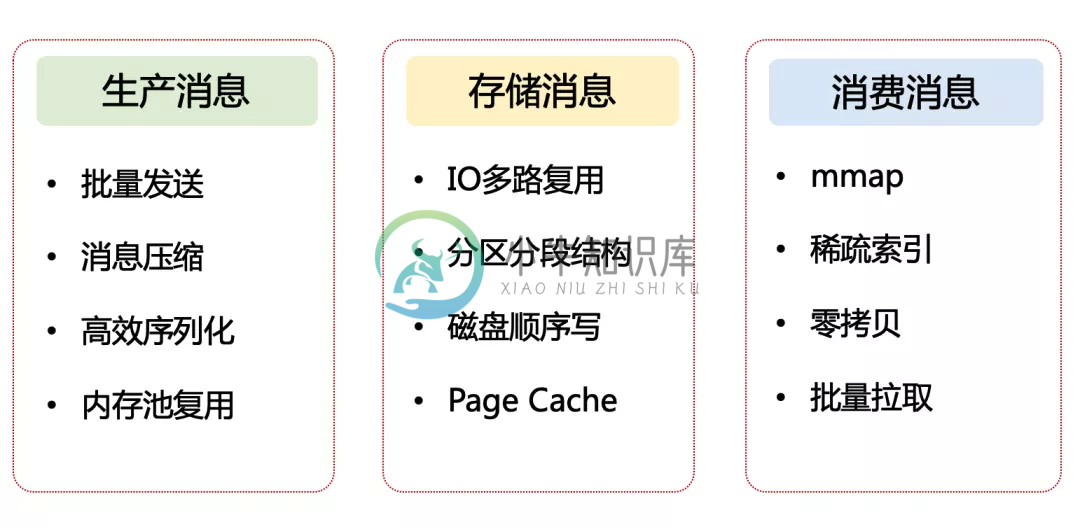
 Kafka高性能设计-1
Kafka高性能设计-1主要内容:1. 如何理解高性能设计,2. Kafka 高性能设计的全景图,3. 生产消息的性能优化手段,4.Kafka源码分析Kafka 的高性能设计可以说是全方位的,从 Prodcuer 、到 Broker、再到 Consumer, 1. 如何理解高性能设计 对于线程池、多级缓存、IO 多路复用、零拷贝等技术是一个系统性的问题,至少需要深入到操作系统层面。从 CPU 和存储入手,去了解底层的实现机制,然后再自底往上,一层一层去解密和贯穿起来。 高性能设计离不开的就是计算和IO 计算: 1、让更