《数梦工场》专题
-
关于数据迁移工具
Navicat 提供一系列强大的工具让你处理数据,包括导入向导、导出向导、数据传输、数据同步、结构同步、转储 SQL 文件、运行 SQL 文件。使用这些工具,你可以轻松地在不同的服务器、数据库和格式之间迁移数据。
-
关于数据迁移工具
Navicat 提供一系列强大的工具让你处理数据,包括导入向导、导出向导、数据传输、数据同步、结构同步、转储 SQL 文件、运行 SQL 文件。使用这些工具,你可以轻松地在不同的服务器、数据库和格式之间迁移数据。
-
 腾讯数据工程二面
腾讯数据工程二面全程无八股 项目: 1、介绍你的工作内容 2、数据库构建过程 3、服务架构 4、如果一个业务很慢怎么办 5、微服务架构的选型 6、大数据处理的技术(不太会。。。。) 算法: 手撕 四则运算,一个string数组,{“1”,“+”,”4“,”/“,”6“,”*“,”2“}算结果(两个辅助栈) 反问: 还有几轮(最多一轮技术面+hr) 整体情况还可以 PS:流程现在显示复试,没有之前会议连接,是不是秒
-
 大疆 数据工程实习
大疆 数据工程实习一面 实习介绍 设计过哪些数据指标,这些指标的意义 项目介绍 具体分层怎么做的 表怎么设计的 对数仓和数据湖的理解 连续登录3天的用户 问的太少了,估计没想招我 #面经##大疆#
-
 潍柴动力-数据工程
潍柴动力-数据工程IT岗,8.21投递,有测评,没有技术笔试 8.29 一面 综合面,hr面,12分钟 自我介绍就1分钟,也没介绍啥 说一个大学以来遇到的困难,以及如何克服的 说一个大学以来与他人合作的例子 为什么选择潍柴 单休,能接受吗 反问环节 下一步的流程?答曰技术面,等邮件 潍柴工作时间?8:30-11:30,13:30-18:00 出差情况?出差不多,会有 住房补贴?跟招聘信息里写的一样 8.30 二面
-
 腾讯数据工程凉经
腾讯数据工程凉经讲一讲项目 clickhouse的存储结构 说一说你对数仓的理解 B+树和B树的理解: 复杂度,能支持的查询类型,存储方式,并发性。 MySQL的两个引擎的区别 ClickHouse的插入和删除 数仓的建设 MergeTree的引擎 sql 找出昨天每个城市中的消费top10 的uid 数仓的岗位,感觉不是很匹配,30分钟结束…
-
 人工智能与大数据
人工智能与大数据主要内容:1.关系,2.区别1.关系 现在,没有什么流行词比大数据和人工智能更常见了。无数的分析家向我们保证,将从根本上重塑我们的日常生活。事实上,对于围绕人工智能和大数据的所有讨论,很少有人提到这两种新兴技术的融合,尤其是在解释人工智能为什么迫切需要大数据以取得成功的时候。 这是人工智能和大数据操作之间的秘密联系,以及这两种新兴趋势将如何主导21世纪。 没有大数据就不能拥有智能机器 在开始描述人工智能和大数据如何一起工作之
-
 三战腾讯 数据工程
三战腾讯 数据工程占个坑先,谢谢面经攒人品。 前两次面鹅都挺难绷的,一点大数据没问 第一次光子测开不知道怎捞了我,人生第一面,估计是我一开始就问为啥捞我到测开?就随便问了点,速度面完秒挂 0.自我介绍,项目(估计不相干,所以讲完就过了) 平常如何自我提升技能 1.session和cookies的区别 2.get和post的区别 2.5元组和列表的区别 3.讲讲数据库的索引 4.什么时候用索引什么时候不用 5.进程和
-
 大数据工程师面经
大数据工程师面经👥 面试题目 hadoop的三个核心组件,以及hdfs的读写原理 hive的内部表与外部表有什么区别 hive里面的数据倾斜是什么?怎么去处理?该怎么去预防? 数据仓库的分为几层?每一层是做什么的?是根据什么进行分层的? hive里面的窗口函数有没有用过?rank(),,dense_rank(),row_number()这三个有什么区别? hive里面数据表合并是怎么合并的? hive里面的列
-
明智的员工部门,员工人数超过5名
问题内容: 我想显示带有的以及,并且计数应大于5,并且我想让一月份没有被雇用的员工。 我尝试了以下查询 但是在这里我没有数。我也想数。 问题答案: 该查询返回department_id,并且由于我按department_id分组,因此将返回属于每个部门的员工数 输出看起来像这样
-
Python的range函数如何工作?
问题内容: 如果我写 然后给出0、1、2、3、4,这 是否意味着Python同时向i分配了0、1、2、3、4? 但是,如果我写了: 然后我叫a,它只给出5, 但是如果我加上“ print a”,它得到1、2、3、4、5。 所以我的问题是,这有什么区别? 是字符串还是列表还是其他? 也许有人可以帮助我进行梳理: 如果运行此类代码,则仅当l = 5时才能得到答案。 如何使它们开始循环? 即l = 0获
-
Google云数据流工作线程
-
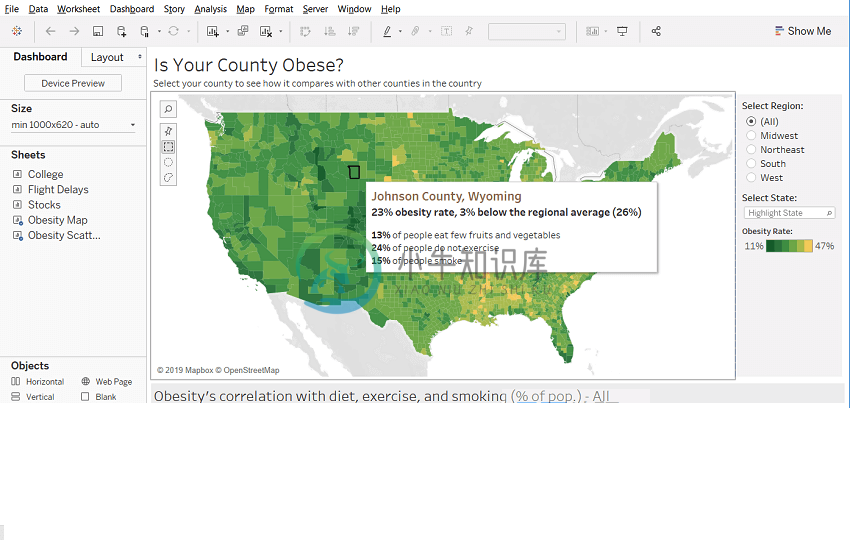 数据可视化工具(推荐)
数据可视化工具(推荐)有一些工具可以帮助您在几分钟内可视化所有数据。这些工具已经存在多年并且已经很成熟; 只需按照您的要求选择正确的数据可视化工具即可。 数据可视化用于与数据交互。Google,Apple,Facebook和Twitter都更好地询问他们的数据更好的问题,并通过使用数据可视化做出更好的业务决策。 以下常见的十大数据可视化工具: 1. Tableau Tableau是一种数据可视化工具。可以创建图形,图表
-
数据库索引如何工作?
问题内容: 鉴于索引随着数据集的增加而变得非常重要,有人可以解释在数据库不可知的级别上索引是如何工作的吗? 问题答案: 为什么需要它? 当数据存储在基于磁盘的存储设备上时,它将作为数据块存储。完全访问这些块,使它们成为原子磁盘访问操作。磁盘块的结构与链接列表几乎相同。两者都包含一个数据节,一个指向下一个节点(或块)位置的指针,并且都不需要连续存储。 由于许多记录只能在一个字段上排序,因此我们可以说
-
Primefaces数据导出器不工作
我正在使用primeface 5.1。我试图简单地将数据导出为pdf格式。要使用primeface 5.1的数据导出器,需要添加itext2.1.7依赖项。我的项目是一个基于maven的项目。我添加了依赖项: 代码的相关部分是: datatable工作正常。我认为代码不是问题所在。无论如何,这是我从glassfish 4.1控制台得到的错误: 任何帮助都将是伟大的!