《小米集团》专题
-
06 Map 集合
概述 Map 集合是无序的 key-value 数据结构。 Map 集合中的 key / value 可以是任意类型,但所有的 key 必须属于同一数据类型,所有的 value 必须属于同一数据类型,key 和 value 的数据类型可以不相同。 声明 Map //demo_14.go package main import ( "fmt" ) func main() { va
-
集成方式
一、导入Mobile SDK 1.1 maven导入(推荐方式) 1.1.1 引入 maven 仓库地址 在工程根目录的 build.gradle 找到(或增加) allprojects -> repositories 节点,然后在该节点加入 maven 仓库地址 https://dl.bintray.com/rokid/maven/,如下所示: allprojects { reposit
-
集成指南
一、 概要 1.1、 简介 Android 活体检测SDK 是一个 Android 端活体检测解决方案,将真实人脸与照片、视频等假冒人脸区分开,有效防止假冒攻击。 目前SDK支持最低版本minSdkVersion 18; 目前SDK不提供开放下载,获取SDK包请联系 market@linkface.cn 1.2、技术原理 活体检测技术是由人脸检测、动作分析和人脸图像采集三部分组成。 人脸检测、定位
-
为什么JVM报告的已提交内存比linux进程驻留集大小更多?
问题内容: 在启用了本机内存跟踪的Java应用程序(在YARN中)运行时(请参阅https://docs.oracle.com/javase/8/docs/technotes/guides/vm/nmt-8.html和https:// docs。 oracle.com/javase/8/docs/technotes/guides/troubleshoot/tooldescr007.html ),我
-
Java-数据结构设计-固定大小、随机访问、线程安全、排序收集
因此,在一些问题中,我需要实现以下内容:固定大小(n=10)的数据结构,总是有序的(降序,无关紧要),线程安全,支持随机访问。 我的解决方案是使用<code>TreeSet</code>,每当添加元素时,如果已经有<code>n</code<元素,则删除最小的元素(如果新元素大于它)并添加新元素。否则,只需添加新元素。访问随机索引时,使用迭代器进行迭代,直到达到所需的索引。 我不太喜欢这个解决方案
-
贪心算法,用于寻找与所有其他区间重叠的最小区间集
我正在学习贪婪算法,遇到了一个我不知道如何解决的问题。给定一组开始时间为a,结束时间为b的区间(a,b),给出一个贪婪算法,该算法返回该集合中每隔一个区间重叠的最小区间数。例如,如果我有: (1,4) (2,3) (5,8) (6,9) (7,10) 我将返回(2,3)和(7,8),因为这两个区间覆盖了集合中的每个区间。我现在得到的是: 通过增加结束时间对间隔进行排序 将结束时间最小的间隔推到堆栈
-
如果封顶集合达到最大大小,为什么MongoDB不会删除旧文档?
我有一个有上限的集合,它是在java代码中创建的: 现在在这个集合的统计数据中,我们有: 如果我尝试使用此代码插入集合中的文档: 我发现了这个错误: 我做错了什么?如何修复它?(排除到. down()此集合并重新创建)感谢您的回答!
-
Java中的列表vs队列vs集合集
问题内容: 列表,队列和集合之间有什么区别? 问题答案: 简单来说: 一个 列表 是一个对象,在同一个对象可能出现不止一次的有序列表。例如:[1,7,1,3,1,1,1,5]。谈论列表中的“第三要素”是有意义的。您可以在列表中的任何位置添加元素,在列表中的任何位置更改元素,或从列表中的任何位置删除元素。 一个 队列 也定购,但你永远只触摸元件的一端。所有元素都在队列的“结尾”处插入,并从队列的“开
-
Java垃圾收集器-什么时候收集?
问题内容: 是什么决定了垃圾收集器何时真正收集?它是在一定时间之后还是在一定数量的内存用完之后发生的吗?还是还有其他因素? 问题答案: 它在确定是时候运行时运行。在世代垃圾收集器中,一种常见的策略是在第0代内存分配失败时运行收集器。也就是说,每次你分配一小块内存(大块通常直接放置在“旧”代中)时,系统都会检查gen-0堆中是否有足够的可用空间,如果没有,则运行GC释放空间以使分配成功。然后将旧数据
-
在Apache上集成PHP,在Tomcat上集成Java
1)我正在使用 2)这两种语言不需要集成Tomcat就可以在Apache服务器上运行。 3)但是,为了增强网站的逻辑性,我们使用Java作为另一种后端编程语言。 4)目前,该Java需要与网站的JSP和PHP页面进行集成。 5)因此,在一个JSP文件中,一部分代码可以是Java的,一部分代码可以是PHP的。 6)理想情况下,如果部分PHP代码运行在Apache服务器上,Java代码运行在Tomca
-
使用共享Zookeeper集合创建Solr集合
我建立了一个具有两个节点和外部Zookeper集合的SOLR集群。该ZK集合有3个节点。我使用参数启动solr实例: 这意味着,我希望SOLR配置在/solr5下,而不是默认情况下的/下。 文件夹 /solr5在ZK中创建: 我还可以毫无问题地将SOLR配置上传到/solr5中。 我的问题是,在创建集合时,如何将生成的文件置于/solr5之下? 我用来创建集合的命令是: 我查看了本页上的文档,但没
-
Docker1.12 Worker无法加入集群(集群:待定)
问题内容: 管理员版本, 工人版本。 创建了Swarm管理器: 然后创建工人 我已经检查了工人的日志 在中,我看到了“虫群:待定” 我也做到了!尽管如此,该工作人员仍无法加入集群。所以,我该怎么爱 更新1 卸载并删除配置文件,然后再次安装docker 1.12版本。 仍然面临着相同的问题(无法加入和中的“ Swarm:Pending” ),其中存在DIFFERENT错误 谢谢。 问题答案: 问题是
-
Spring Boot 2集成Brave MySQL-集成到Zipkin中
我正在尝试将Brave MySql检测集成到Spring Boot2.x服务中,以自动地让它的拦截器通过涉及MySql查询的范围来丰富我的跟踪。 当前的Gradle-依赖关系如下 你有什么建议给我如何正确地连接东西吗?
-
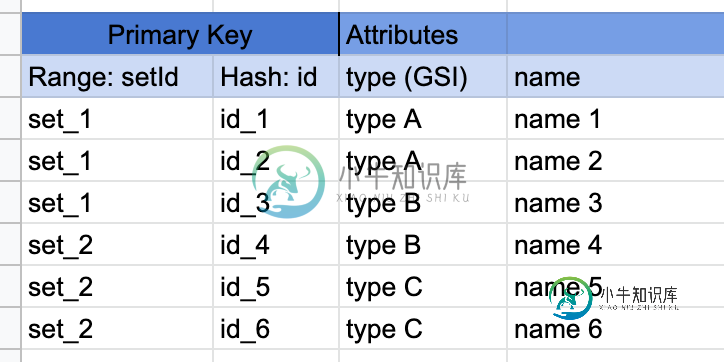 (DynamoDB集合)集合查询是否需要sortKey?
(DynamoDB集合)集合查询是否需要sortKey?我正在制作一些lambda来从dynamoDB表中获取数据。 DynamoDB表具有 复合主键 'setId'作为分区键(范围键)(我用这个词'set'作为名词,就像'group'一样) 'id'作为排序键(散列键) 如果我理解正确, 我可以使用setId来查询,因为DynamoDb通过分区键进行集合。 所以我尝试了这个参数。 但它返回错误 Q. 获取集合是否需要排序键? 提前谢谢! 仅供参考)我
-
如何从集合映射到集合属性?
假设我有以下映射目标。 如何从其他属性的Iterable映射到其他属性? 我可以这样做吗?