《深信服面经》专题
-
多克服务在一段时间后停止通信
我有6个集装箱在码头群中运行。Kafka Zookeeper、MongoDB、A、B、C和接口。接口是来自公共的主要访问点-只有这个容器发布端口-5683。接口容器在启动期间连接到A、B和C。我使用docker组合文件docker堆栈部署,每个服务都有一个名称,用作接口的主机。一切都开始顺利,运转良好。过了一段时间(20分钟、1小时……),我无法向接口提出请求。接口接收到我的请求,但应用程序与服务
-
web服务器元文件信息发现 (OTG-INFO-003)
综述 这章节描述如何从robots.txt中发现泄露的web应用路径信息。更进一步,这些应该被蜘蛛、机器人和网页抓取软件忽略的目录列表能很好地作为建立应用流程的参考。 测试目标 web应用路径或者文件夹泄露信息。 建立被蜘蛛机器人忽略的目录列表。 如何测试 robots.txt Web蜘蛛、机器人和网页抓取软件通过获取页面,递归遍历超链接来获取更多的网页内容。他们的行为应该遵循在网站根目录下rob
-
微信服务号与订阅号的主要区别
订阅号和服务号都是微信公众号的一种,对于一个普通的微信用户,可能感受的差别只是所有订阅号的消息都收纳在了微信会话列表的【订阅号消息】中,而服务号消息则是一个个服务号出现在了微信会话列表中; 对于企业市场人员,微信服务号与订阅号的主要区别体现在以下几点: 1. 带参数的二维码 微信服务号支持参数二维码,支持在不同的场景下生成微信服务号参数二维码,可以帮助企业识别微信服务号粉丝关注来源。 订阅号不支持
-
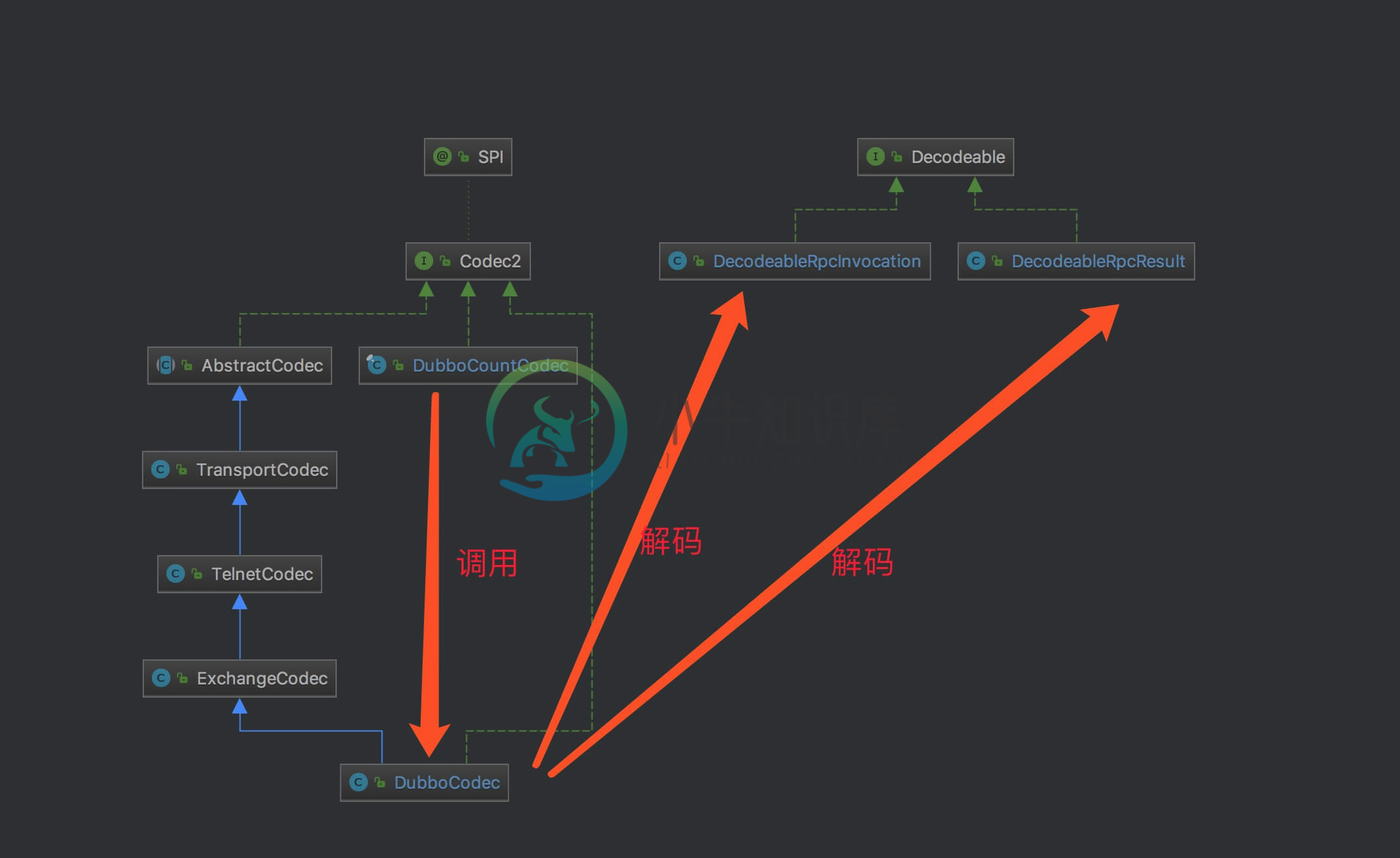 Dubbo 服务调用之远程调用-通信实现
Dubbo 服务调用之远程调用-通信实现主要内容:1.概述,2.ExchangeHandler,3. Codec1.概述 本文涉及类图如下: 2.ExchangeHandler 在 DubboProtocol 中,实现了 ExchangeHandler ,代码如下: 3. Codec 实现 Codec2 接口,支持多消息的编解码器。 3.1 DubboCountCodec 3.2 DubboCodec 实现 Codec2 接口,继承 ExchangeCodec 类,Dubbo 编解码器实现类。 构造方法 3
-
在kubernetes上部署微服务时服务间通信的连接超时问题
我正在做一个演示项目,它有5个微服务-发现服务器,api-gateway,user-order-detail,order和user Service。 我将在GKE上内部公开订单和用户服务 我将对外公开user-order-detail服务,它将使用restendpoint调用其他两个服务 google kubernetes引擎上的服务: user-order-detail LoadBalancer
-
用docker和kubernetes部署的Spring-boot微服务应用程序:服务不通信
我的应用程序服务无法相互通信。我拥有的是一个由身份验证服务、发现服务器、api网关和商家服务组成的应用程序。我使用eureka服务器和客户端依赖关系进行服务发现。每个服务都用docker进行容器化,我使用K8进行编排。 当我向服务器发送请求时,我得到的响应是: 以下是我的尤里卡属性和K8配置文件: 发现服务器文件 身份验证服务application.properties文件 商户服务 API 网关
-
 北京发那科 Java开发 深圳 一二面 已offer
北京发那科 Java开发 深圳 一二面 已offer9.2 投递 10.14 一面 10.27 测评 10.28 二面 10.31 oc 一面(群面)3个人 1.轮流自我介绍 2.轮流问项目、实习经历 3.轮流问实习经历和项目中遇到喜欢的事情和不擅长,不喜欢的地方,以及一些hr问题 轮流反问 时长:51分钟 二面(群面)6个人 2.1、线上无领导小组面试 1小时 主要就是考察综合能力 2.2、线上总经理面试 1小时 1.轮流
-
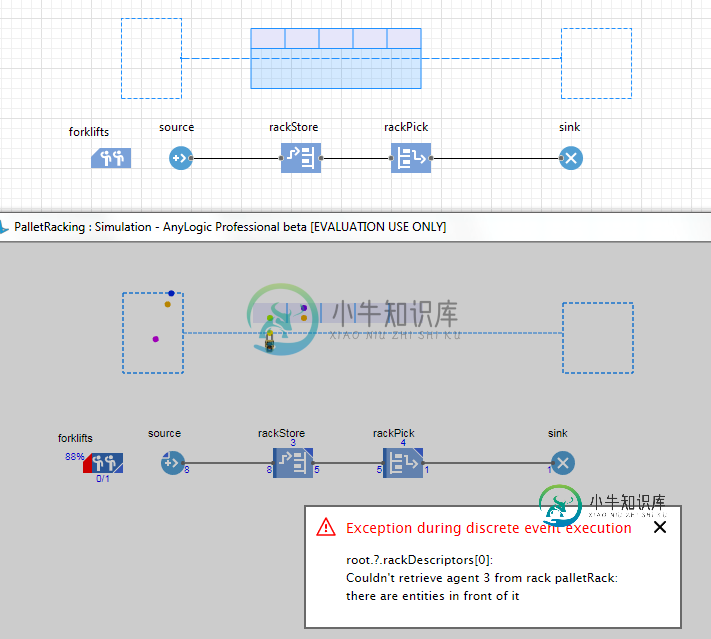 从两个深托盘架上挑选前面的物品
从两个深托盘架上挑选前面的物品我把两个特工藏在一个托盘架上,用一个行李架块。当我用rackStore从货架上取出物品时,它尝试先取后面的代理,我得到下面的错误,说它不能被挑选,因为前面有其他代理。 有人知道我怎么从前面挑吗?
-
 面了一家初创公司深度学习实习岗
面了一家初创公司深度学习实习岗今年真是太卷了,加上上海的疫情,只能线上实习。投了几十份简历,至今就这一个面试。 面试内容虽然没啥,还是分享一下吧。 我的主要根据我简历上写的项目问的,也没有算法题(原以为可能会有1-2道),可能是实习吧,也就面了15分钟。 问了2个项目: 1. 一个课程作业,关于单个图像去雾算法的研究。问了我网络的大概结构,我做的优化(提高了收敛速度),以及为啥这样做可以提高收敛速度(原理)。 2. 最近参加的
-
 软件测试实习-安克创新(深圳)-电话面
软件测试实习-安克创新(深圳)-电话面自我介绍 软件测试基本流程是怎样的? 软件测试的方法有哪些? 给你一个登录页面如何测试? HTTP 和 HTTPS有什么区别? postman 如何设置全局变量? 你常用的Linux命令有哪些? 你的学习能力怎么样? 对于这个岗位,你的职业发展规划是怎样的? 你手上有没有其他公司的 offer?你会怎样选择? 你是怎样看待加班的?怎样看待调休? 反问环节 ---------------------
-
深入了解库
问题内容: 我试图了解如何使用Golang和forks。情况如下,我在写一个依赖于library的库,这不是我的。 由于缺少我需要的一些方法,因此将其分叉到。但是,我不能只是这样做,库引用了自己,所以它坏了。 在本文中,他们提供了可能的解决方案: 现在,这充其量是hacky。从库代码中无法得知依赖项来自其他存储库。任何使用我的图书馆的人都无法使其正常运行。 由于dep有望成为正式的依赖管理器。我发
-
JSON.stringify深层对象
问题内容: 我需要一个从任何参数构建JSON有效字符串的函数,但: 通过不两次添加对象来避免递归问题 通过截断给定深度来避免调用堆栈大小问题 通常,它应该能够处理大对象,但要以截断为代价。 作为参考,此代码失败: 避免递归问题很简单: 但是到目前为止,除了复制和更改Douglas Crockford的代码 以跟踪深度之外,我还没有找到任何方法来避免在诸如或any之类的非常深的对象上发生堆栈溢出。有
-
16 深度遍历
def deep(root): if not root: return print root.data deep(root.left) deep(root.right) if __name__ == '__main__': lookup(tree) deep(tree)
-
1.16 深度学习
现在开始学深度学习。在这部分讲义中,我们要简单介绍神经网络,讨论一下向量化以及利用反向传播(backpropagation)来训练神经网络。 1 神经网络(Neural Networks) 我们将慢慢的从一个小问题开始一步一步的构建一个神经网络。回忆一下本课程最开始的时就见到的那个房价预测问题:给定房屋的面积,我们要预测其价格。 在之前的章节中,我们学到的方法是在数据图像中拟合一条直线。现在咱们不
-
深入理解(function(){... })();
本文向大家介绍深入理解(function(){... })();,包括了深入理解(function(){... })();的使用技巧和注意事项,需要的朋友参考一下 1.他叫做立即运行的匿名函数(也叫立即调用函数) 2.当一个匿名函数被括起来,然后再在后面加一个括号,这个匿名函数就能立即运行起来!有木有很神奇哦~ 3.要使用一个函数,我们就得首先声明它的存在。而我们最常用的方式就是使用functio