
根据条件高效地为数据帧创建新行

我有两个熊猫数据帧:一个带有ID和值,另一个将ID与其他ID映射。目标是创建一个基于df1的新数据帧。它循环遍历df1中的每个源ID,并查看df2(一个映射df)以查找源ID中的匹配项。如果找到匹配项,将创建与df1中的值相同的新行。因此,如果找到多个匹配项,循环将创建多个行(例如id A和C)。如果只找到一个匹配项(例如id B),则只创建一行。
下面的代码完全符合我的要求,但速度非常慢。在我的原始数据集中,df1是440K行,df2有数千个不同ID的映射-目前代码以10-25it/s的速度运行,这太多了。
有没有一种更快的方法可以从矩阵计算/Numpy/熊猫的其他好处中获益?
import pandas as pd
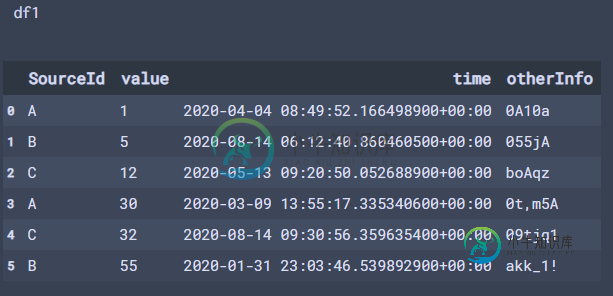
df1 = pd.DataFrame({
'SourceId': ['A', 'B', 'C', 'A', 'C', 'B'],
'value': [1, 5, 12, 30, 32, 55],
'time': [pd.to_datetime('2020-04-04 08:49:52.166498900+0000'),
pd.to_datetime('2020-08-14 06:12:40.860460500+0000'),
pd.to_datetime('2020-05-13 09:20:50.052688900+0000'),
pd.to_datetime('2020-03-09 13:55:17.335340600+0000'),
pd.to_datetime('2020-08-14 09:30:56.359635400+0000'),
pd.to_datetime('2020-01-31 23:03:46.539892900+0000')],
'otherInfo': ['0A10a', '055jA', 'boAqz', '0t,m5A', '09tjq1', 'akk_1!']})
df2 = pd.DataFrame({'SourceId': ['A', 'A', 'B', 'C', 'C', 'C'], 'TargetId': ['A', 'Q', 'B', 'C', 'B', 'X'], 'trueIfMatch': [1, 0, 1, 1, 0, 0]})
df3 = pd.DataFrame()
for r in df1.itertuples():
SourceId = r.SourceId
value = r.value
time = r.time
otherInfo = r.otherInfo
if SourceId in df2.SourceId.unique():
entries = df2.loc[df2.SourceId == SourceId].TargetId.tolist()
for entry in entries:
df3 = df3.append({
'sourceId': SourceId,
'targetId': entry,
'value': value,
'time': time,
'otherInfo': otherInfo
}, ignore_index=True)
display(df3)
共有1个答案

使用df。将与排序值合并:
In [2293]: df3 = df1.merge(df2, on='SourceId').sort_values('value')
In [2294]: df3
Out[2294]:
SourceId value TargetId
0 A 1 A
1 A 1 Q
4 B 5 B
6 C 12 C
7 C 12 B
8 C 12 X
2 A 30 A
3 A 30 Q
9 C 32 C
10 C 32 B
11 C 32 X
5 B 55 B
-
问题内容: 我想获取基于条件选择的数据帧行数。我尝试了以下代码。 输出: 输出显示数据帧中每一列的计数。相反,我需要获得满足以上所有条件的单一计数?这该怎么做?如果您需要有关我的数据框的更多说明,请告诉我。 问题答案: 您要的是所有条件都为真的条件,所以答案是len,除非我误解了您的要求
-
我有一个相当大的数据帧(几百列),我想对它执行以下操作。我在下面用一个玩具数据框和一个简单的条件来说明我需要什么。 对于每一行:条件#1:检查其中两列的值是否为零(0)。如果这是真的,请保留该行并继续下一行。如果任一列的值为零(0),则条件为真。 如果条件#1为False(第1列或第4列中没有零),请检查行中所有剩余的列。如果任何剩余列的值为零,则删除该行。 我希望过滤后的数据帧作为一个新的、独立
-
我正在为一个大的数据集创建条件平均值,这个数据集包含了几年来一周内看到的流感病例数。数据是这样组织的: 我想做的是创建一个新的列,列出往年同一周的平均病例数。例如,对于Week所在的行。数字是1和流感。今年是2017年,我希望新行给出任何一年的平均计数。数字==1 但是,由于有四年的数据* 52周,因此需要大量迭代才能阐明条件。有没有办法在dplyr中优雅地编码它?我经常遇到的问题是,我想根据周.
-
我有两个data.frames,每个都有数千行和几十列,都是通过合并几个csv文件创建的。data.frames正是我想要的。我还要补充一点,df1和df2有几列是共同的。唯一的问题是,在其中一个中,比如df1,对于某些列,有一些NAs(这是预期的/正常的)。好的一面是,我有NAs的相同列也出现在第二data.frame,比如df2,但没有NAs。我想做的是用df1同一列的值填充df2给定列中的N
-
我有一个由名字和年份组成的dataframe,并有一个虚拟变量来判断名字是否发生在一年中。 null 谢谢!
-
我需要帮助完成一项看似简单的任务。我想基于< code>dplyr::mutate中的一个条件创建几个新变量。我可以使用< code>ifelse创建一个新变量,但是我想一步创建几个。 让我们假设这是我的数据帧。 我想要这样的东西: 因此,if条件应该基于条件< code>y创建三个新变量 我想与< code>if_else和< code>case_when一起使用。 谢谢转发