
故障理解卷积神经网络

我从这里读到了卷积神经网络。然后我开始玩torch7。我对CNN的卷积层感到困惑。
从教程中,
一层中的神经元将只连接到它之前的一个小区域,而不是以完全连接的方式连接所有神经元
<代码>例如,假设输入卷的大小为[32x32x3],(例如,RGB CIFAR-10图像)。如果感受野的大小为5x5,则Conv层中的每个神经元将对输入体积中的[5x5x3]区域具有权重,总共5×5×3=75个权重
如果输入层是[32x32x3],CONV层将计算连接到输入中局部区域的神经元的输出,每个神经元计算其权重与输入体积中连接到的区域之间的点积。这可能会产生[32x32x12]等体积
我开始玩CONV层对图像可能做的事情。我在torch7中做到了。这是我的实现,
require 'image'
require 'nn'
i = image.lena()
model = nn.Sequential()
model:add(nn.SpatialConvolutionMM(3, 10, 5, 5)) --depth = 3, #output layer = 10, filter = 5x5
res = model:forward(i)
itorch.image(res)
print(#i)
print(#res)

3
512
512
[torch.LongStorage of size 3]
10
508
508
[torch.LongStorage of size 3]
现在让我们看看CNN的结构
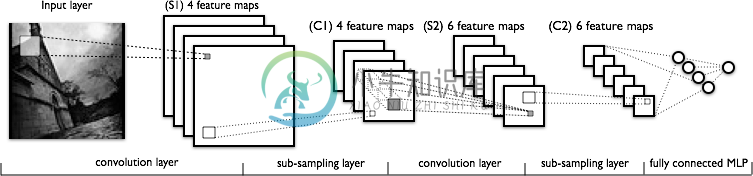
所以,我的问题是,
卷积是这样完成的吗——假设我们取一张32x32x3的图像。有5x5过滤器。然后5x5过滤器将穿过整个32x32图像并产生卷积图像?好吧,所以在整个图像上滑动5x5过滤器,我们得到一张图像,如果有10个输出层,我们得到10张图像(如您从输出中看到的)。我们如何得到这些?(如果需要,请参阅图像以进行澄清)

conv层的神经元数量是多少?是输出层的数量吗?在我上面写的代码中,模型:add(nn.SpatialConvolutionMM(3,10,5,5))。是10号吗?(输出层的数量?)
如果是这样,第2点就没有任何意义了。根据该,如果接受域的大小为5x5,那么Conv Layer中的每个神经元将对输入体积中的[5x5x3]区域具有权重,总共为5*5*3=75个权重。那么这里的权重是多少?我对此感到非常困惑。在torch中定义的模型中,没有权重。那么权重在这里是如何发挥作用的呢?
有人能解释一下这是怎么回事吗?
共有2个答案

免责声明:我下面提供的信息主要摘自以下论文:猫视觉皮层中的信息处理基于梯度的学习应用于猫视觉皮层中的文档识别新皮质激素受体场
卷积是这样做的吗——假设我们取一张32x32x3的图像。有5x5过滤器。然后5x5过滤器将穿过整个32x32图像并产生卷积图像?
是的,一个5x5滤波器将穿过整个图像,创建一个28x28 RGB图像。所谓的“特征图”中的每个单元都接收连接到输入图像中5x5区域的5x5x3输入(这个5x5邻域称为该单元的“局部接受场”)。特征图中相邻(相邻)单元的接受场以前一层中的相邻(相邻)单元为中心。
好的,在整个图像上滑动5x5过滤器,我们得到一个图像,如果有10个输出层,我们得到10个图像(正如您从输出中看到的)。我们如何得到这些?(如有需要,请参见图片以了解说明)
请注意,特征图层上的单元共享相同的权重集,并对图像的不同部分执行相同的操作。(也就是说,如果您移动原始图像,特征图上的输出也将移动相同的量)。也就是说,对于每个特征图,您将每个单元的权重集约束为相同的;您只有5x5x3的未知权重。
由于这一限制,并且由于我们希望从图像中提取尽可能多的信息,我们添加了更多的层、特征映射:具有多个特征映射有助于我们在每个像素处提取多个特征。
不幸的是,我不熟悉Torch7。

卷积是这样做的吗——假设我们取一张32x32x3的图像。有5x5过滤器。然后5x5过滤器将穿过整个32x32图像并产生卷积图像?
对于32x32x3输入图像,5x5过滤器将迭代每个像素,并针对每个像素查看5x5邻域。该邻域包含5*5*3=75个值。下面是单个输入通道上3x3滤波器的示例图像,即具有3×3×1值邻域的输入通道(源)。
对于每个单独的邻居,过滤器将有一个参数(又名权重),因此有75个参数。然后为了计算一个单一的产出值(像素x, y处的值),它读取这些邻居值,将每个邻居值与相应的参数/权重相乘,并在最后相加(参见离散卷积)。必须在训练期间学习最佳权重。
因此,一个过滤器将在图像上迭代并逐像素生成新的输出。如果有多个过滤器(即,SpatialConvolutionMM中的第二个参数为
好的,在整个图像上滑动5x5过滤器,我们得到一个图像,如果有10个输出层,我们得到10个图像(正如您从输出中看到的)。我们如何得到这些?(如有需要,请参见图片以了解说明)
每个输出平面由其自己的过滤器生成。每个过滤器都有自己的参数(示例中为5*5*3个参数)。多个过滤器的过程与一个过滤器的过程完全相同。
conv层的神经元数量是多少?是输出层的数量吗?在我上面编写的代码中,model:add(nn.SpatialConvolutionMM(3,10,5,5))。是10号吗?(输出层的数量?)
你应该称它们为权重或参数,“神经元”并不真正适合于卷积层。如前所述,在您的示例中,每个过滤器的参数数为5*5*3=75。由于有10个过滤器(“输出平面”),所以总共有750个参数。如果使用模型:add(nn.SpatialConvolutionMM(10,10,5,5))向网络添加第二层,则每个过滤器将有额外的5*5*10=250个参数,总计250*10=2500个。请注意这个数字是如何快速增长的(一个层中512个过滤器/输出平面在256个输入平面上运行并不罕见)。
要进一步阅读,您应该查看http://neuralnetworksanddeeplearning.com/chap6.html。向下滚动到“介绍卷积网络”一章。在“局部接受域”下有一些可视化可能会帮助您理解过滤器的作用(如上所示)。
-
卷积运算 再次引用上一篇里的内容《自己动手做聊天机器人 二十二-神奇算法之人工神经网络》: 卷积英文是convolution(英文含义是:盘绕、弯曲、错综复杂),数学表达是: 上面连续的情形如果不好理解,可以转成离散的来理解,其实就相当于两个多项式相乘,如:(x*x+3*x+2)(2*x+5),计算他的方法是两个多项式的系数分别交叉相乘,最后相加。用一句话概括就是:多项式相乘,相当于系数向量的卷积
-
注意: 本教程适用于对Tensorflow有丰富经验的用户,并假定用户有机器学习相关领域的专业知识和经验。 概述 对CIFAR-10 数据集的分类是机器学习中一个公开的基准测试问题,其任务是对一组大小为32x32的RGB图像进行分类,这些图像涵盖了10个类别: 飞机, 汽车, 鸟, 猫, 鹿, 狗, 青蛙, 马, 船以及卡车。 想了解更多信息请参考CIFAR-10 page,以及Alex Kriz
-
卷积神经网络(Convolutional Neural Network, CNN)是一种前馈神经网络,它的人工神经元可以响应一部分覆盖范围内的周围单元,对于大型图像处理有出色表现。卷积神经网络由一个或多个卷积层和顶端的全连通层(对应经典的神经网络)组成,同时也包括关联权重和池化层(pooling layer)。这一结构使得卷积神经网络能够利用输入数据的二维结构。与其他深度学习结构相比,卷积神经网络
-
下午好在第一阶段,在卷积神经网络(输入层)的输入上,我们接收一个源图像(因此是手写英文字母的图像)。首先,我们使用一个从左到右的nxn窗口来扫描图像并在内核(卷积矩阵)上乘法来构建特征映射?但没有人写过内核应该具有什么样的精确值(换句话说,我应该将从n*n窗口检索到的数据相乘到什么样的内核值)。是否适合在这个用于边缘检测的卷积核上乘以数据?有许多卷积核(浮雕、高斯滤波器、边缘检测、角度检测等)?但
-
在了解了机器学习概念之后,现在可以将注意力转移到深度学习概念上。深度学习是机器学习的一个分支。深度学习实现的示例包括图像识别和语音识别等应用。 以下是两种重要的深度神经网络 - 卷积神经网络 递归神经网络 在本章中,我们将重点介绍CNN - 卷积神经网络。 卷积神经网络 卷积神经网络旨在通过多层阵列处理数据。这种类型的神经网络用于图像识别或面部识别等应用。CNN与其他普通神经网络之间的主要区别在于
-
主要内容:卷积神经网络深度学习是机器学习的一个分支,它是近几十年来研究人员突破的关键步骤。深度学习实现的示例包括图像识别和语音识别等应用。 下面给出了两种重要的深度神经网络 - 卷积神经网络 递归神经网络。 在本章中,我们将关注第一种类型,即卷积神经网络(CNN)。 卷积神经网络 卷积神经网络旨在通过多层阵列处理数据。这种类型的神经网络用于图像识别或面部识别等应用。 CNN与任何其他普通神经网络之间的主要区别在于CNN