
如何优化Apache Spark应用中的shuffle溢出

我正在运行一个有2个工作者的Spark流式应用程序。应用程序具有联接和联合操作。
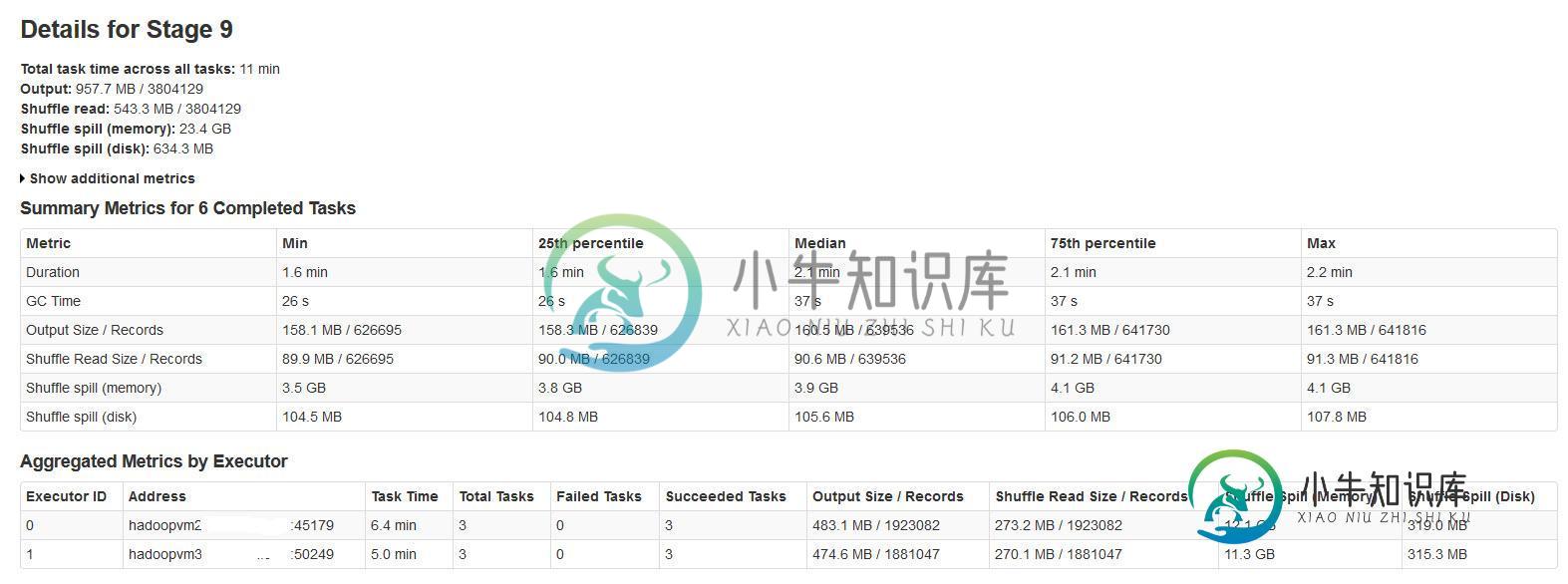
所有批处理都成功完成,但注意到shuffle溢出度量与输入数据大小或输出数据大小不一致(溢出内存超过20次)。
对此进行研究后发现
注意到这个溢出内存的大小对于大的输入数据是难以置信的大。
我的问题是:
这种溢出对性能有很大影响吗?
有没有什么火花属性可以减少/控制这种巨大的溢出?
共有1个答案

学习性能调整Spark需要相当多的调查和学习。有几个很好的资源包括这个视频。Spark1.4在界面中有一些更好的诊断和可视化功能,可以帮助您。
总而言之,当阶段结束时RDD分区的大小超过了可用于shuffle缓冲区的内存量时,就会溢出。
您可以:
- 手动
repartition()您的前一个阶段,以便从输入中获得更小的分区。 - 通过增加执行程序进程(
spark.executor.memory)中的内存来增加洗牌缓冲区 - 通过从默认值0.2增加分配给它的执行程序内存(
spark.shuffle.memoryfract)的部分来增加洗牌缓冲区。您需要返回spark.storage.memoryfraction。 - 通过降低工作线程(
spark_worker_cores)与执行程序内存的比率来增加每个线程的洗牌缓冲区
如果有专家在听,我很想知道更多关于memoryFraction设置是如何交互的,以及它们的合理范围。
-
我开始写前端应用的时候,并不知道一个 Web 应用需要优化那么多的东西。编写应用的时候,运行在本地的机器上,没有网络问题,也没有多少的性能问题。可当我把自己写的博客部署到服务器上时,我才发现原来我的应用在生产环境上这么脆弱。 我的第一个真正意义上的 Web 应用——开发完应用,并可供全世界访问,是我的博客。它运行在一个共享 256 M 内存的 VPS 服务器上,并且服务器是在国外,受限于网络没有备
-
如何清理linux不需要的软件包
-
我正在ApacheSpark上的数据库中构建一个族谱,使用递归搜索来查找数据库中每个人的最终父级(即族谱顶部的人)。 假设搜索id时返回的第一个人是正确的家长 它给出以下错误 “原因:org.apache.spark.SparkException:RDD转换和操作只能由驱动程序调用,不能在其他转换中调用;例如,
-
我们使用API网关Lambda函数DynamoDB来获取数据,并使用DynamoDB查询方法。对于260.4KB的数据(项目总计数:675 |扫描计数:3327),需要3.49秒。 要求: 我们有4个客户,我们每天计算客户销售用户的数据,并将其存储在数据库中。 表结构: 主键:ClientId 排序键:日期UserId 其他属性:日期 在查询中-我们使用主键ClientId 目前,我们正在为Dyn
-
我正在尝试创建一个spark应用程序,它对创建、读取、写入和更新MySQL数据非常有用。那么,有没有办法使用Spark创建一个MySQL表? 下面是在MySQL数据库中创建表的Scala JDBC代码。我怎样才能通过Spark做到这一点?
-
我想知道如何优化我的画圆方法。在将顶点发送到opengl之前,我寻求如何尽快生成顶点。 FillRect函数只绘制一个四边形,因此DrawCircle函数绘制100个四边形,这些四边形按cos、sin和半径移动。 我怎么能以不同的方式画圆呢?