
解释训练损失/准确性与验证损失/准确性

关于使用Lenet5网络解释MNIST上某些优化器的性能,我有几个问题,以及验证损失/精度与训练损失/精度图确切地告诉我们什么。因此,所有的事情都是在Keras中使用标准的LeNet5网络完成的,它运行了15个历元,批处理大小为128。
有两个图,列车acc vs val acc和列车损失vs val损失。我生成了4个图,因为我运行了两次,一次是validation_split=0.1,一次是validation_data=(x_test,y_test)在model.fit参数中运行。具体地说,区别如下所示:
train = model.fit(x_train, y_train, epochs=15, batch_size=128, validation_data=(x_test,y_test), verbose=1)
train = model.fit(x_train, y_train, epochs=15, batch_size=128, validation_split=0.1, verbose=1)
以下是我制作的图表:
using validation_data=(x_test, y_test):
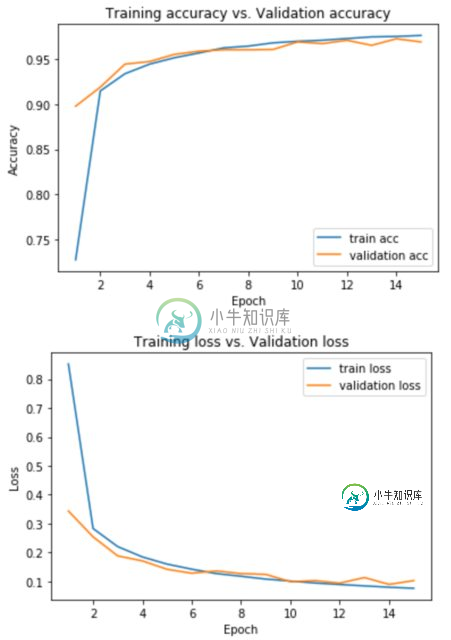
using validation_split=0.1:
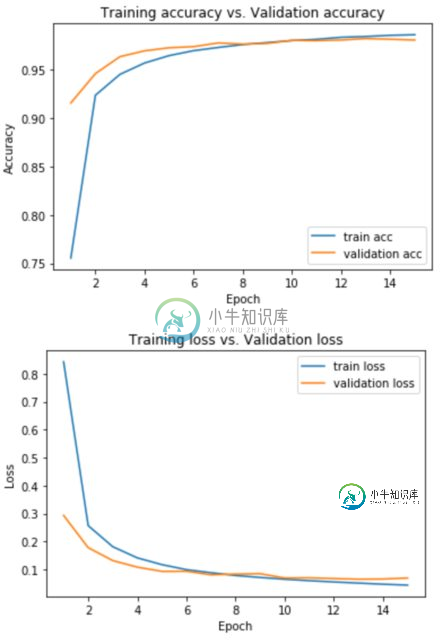
所以我的两个问题是:
1.)如何解释列车acc vs val acc和列车损失vs val acc图?比如它确切地告诉我什么,以及为什么不同的优化器有不同的性能(即图也是不同的)。
2.)为什么当我使用validation_split时,图会发生变化?哪一个会是更好的选择?
共有1个答案

我将尝试提供一个答案
>
可以看到,接近尾声时,训练精度略高于验证精度,训练损失略低于验证损失。这暗示你过度适应,如果你训练更多的时代,差距应该会扩大。
即使您使用相同的模型和相同的优化器,您也会注意到运行之间的细微差别,因为权重是随机初始化的,并且随机性与GPU实现相关联。您可以在这里了解如何解决这个问题。
-
在每个纪元结束时,我会得到以下输出: 谁能给我解释一下损失、准确性、验证损失和验证准确性之间有什么区别吗?
-
问题内容: 我找不到Keras如何定义“准确性”和“损失”。我知道我可以指定不同的指标(例如mse,交叉熵),但是keras会打印出标准的“准确性”。如何定义?同样对于损失:我知道我可以指定不同类型的正则化- 损失中的那些正则化吗? 理想情况下,我想打印出用于定义它的公式;如果没有,我会在这里解决。 问题答案: 看一下,您可以在其中找到所有可用指标的定义,包括不同类型的准确性。除非在编译模型时将其
-
当我用Theano或Tensorflow训练我的神经网络时,它们会每历元报告一个叫做“损失”的变量。 我该如何解释这个变量呢?更高的损耗是更好还是更差,或者这对我的神经网络的最终性能(准确性)意味着什么?
-
我为文本分类问题设计了一个网络。为此,我使用huggingface transformet的BERT模型,上面有一个线性层进行微调。我的问题是训练集上的损失在减少,这很好,但是当涉及到在开发集上的每个时代之后进行评估时,损失会随着时代而增加。我正在发布我的代码来调查它是否有问题。 下面是训练器文件,我使用它对给定批次进行前向传递,然后相应地反向传播。 最后,以下是我的模型(即分类器)类: 为了可视
-
在这里我使用的是基于一维cnn的模型,我不理解模型的学习曲线,因为测试/验证精度曲线是波动的,而总体模型性能大约是70%,相反验证损失只是饱和和波动?我应该如何解释我的结果,我应该考虑什么变化? 我用过亚当优化器。
-
问题内容: 我有一个“一键编码”(全1和全0)的数据矩阵,具有260,000行和35列。我正在使用Keras训练简单的神经网络来预测连续变量。组成网络的代码如下: 但是,在训练过程中,我看到损失下降得很好,但是在第二个时期的中间,它就变成了nan: 我尝试使用代替,尝试替代,尝试使用和不使用辍学,但都无济于事。我尝试使用较小的模型,即仅具有一个隐藏层,并且存在相同的问题(在不同的点它变得很困难)。