
与训练集损失不同,开发集损失总是在增加

我为文本分类问题设计了一个网络。为此,我使用huggingface transformet的BERT模型,上面有一个线性层进行微调。我的问题是训练集上的损失在减少,这很好,但是当涉及到在开发集上的每个时代之后进行评估时,损失会随着时代而增加。我正在发布我的代码来调查它是否有问题。
for epoch in range(1, args.epochs + 1):
total_train_loss = 0
trainer.set_train()
for step, batch in enumerate(train_dataloader):
loss = trainer.step(batch)
total_train_loss += loss
avg_train_loss = total_train_loss / len(train_dataloader)
logger.info(('Training loss for epoch %d/%d: %4.2f') % (epoch, args.epochs, avg_train_loss))
print("\n-------------------------------")
logger.info('Start validation ...')
trainer.set_eval()
y_hat = list()
y = list()
total_dev_loss = 0
for step, batch_val in enumerate(dev_dataloader):
true_labels_ids, predicted_labels_ids, loss = trainer.validate(batch_val)
total_dev_loss += loss
y.extend(true_labels_ids)
y_hat.extend(predicted_labels_ids)
avg_dev_loss = total_dev_loss / len(dev_dataloader)
print(("\n-Total dev loss: %4.2f on epoch %d/%d\n") % (avg_dev_loss, epoch, args.epochs))
print("Training terminated!")
下面是训练器文件,我使用它对给定批次进行前向传递,然后相应地反向传播。
class Trainer(object):
def __init__(self, args, model, device, data_points, is_test=False, train_stats=None):
self.args = args
self.model = model
self.device = device
self.loss = nn.CrossEntropyLoss(reduction='none')
if is_test:
# Should load the model from checkpoint
self.model.eval()
self.model.load_state_dict(torch.load(args.saved_model))
logger.info('Loaded saved model from %s' % args.saved_model)
else:
self.model.train()
self.optim = AdamW(model.parameters(), lr=2e-5, eps=1e-8)
total_steps = data_points * self.args.epochs
self.scheduler = get_linear_schedule_with_warmup(self.optim, num_warmup_steps=0,
num_training_steps=total_steps)
def step(self, batch):
batch = tuple(t.to(self.device) for t in batch)
batch_input_ids, batch_input_masks, batch_labels = batch
self.model.zero_grad()
outputs = self.model(batch_input_ids,
attention_mask=batch_input_masks,
labels=batch_labels)
loss = self.loss(outputs, batch_labels)
loss = loss.sum()
(loss / loss.numel()).backward()
torch.nn.utils.clip_grad_norm_(self.model.parameters(), 1.0)
self.optim.step()
self.scheduler.step()
return loss
def validate(self, batch):
batch = tuple(t.to(self.device) for t in batch)
batch_input_ids, batch_input_masks, batch_labels = batch
with torch.no_grad():
model_output = self.model(batch_input_ids,
attention_mask=batch_input_masks,
labels=batch_labels)
predicted_label_ids = self._predict(model_output)
label_ids = batch_labels.to('cpu').numpy()
loss = self.loss(model_output, batch_labels)
loss = loss.sum()
return label_ids, predicted_label_ids, loss
def _predict(self, logits):
return np.argmax(logits.to('cpu').numpy(), axis=1)
最后,以下是我的模型(即分类器)类:
import torch.nn as nn
from transformers import BertModel
class Classifier(nn.Module):
def __init__(self, args, is_eval=False):
super(Classifier, self).__init__()
self.bert_model = BertModel.from_pretrained(
args.init_checkpoint,
output_attentions=False,
output_hidden_states=True,
)
self.is_eval_mode = is_eval
self.linear = nn.Linear(768, 2) # binary classification
def switch_state(self):
self.is_eval_mode = not self.is_eval_mode
def forward(self, input_ids, attention_mask=None, labels=None):
bert_outputs = self.bert_model(input_ids,
token_type_ids=None,
attention_mask=attention_mask)
# Should give the logits to the the linear layer
model_output = self.linear(bert_outputs[1])
return model_output
为了可视化整个时代的损失:
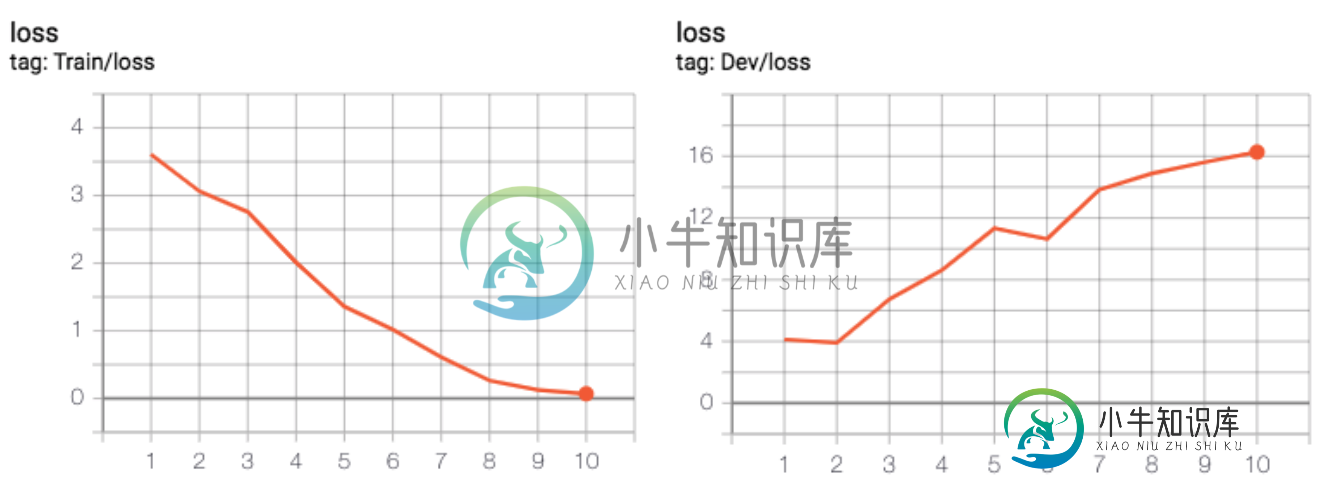
共有2个答案

当验证损失增加时,表示您的模型过度拟合

当我使用Bert进行文本分类时,我的模型通常按照您所说的那样工作。这在一定程度上是意料之中的,因为预先训练的模型往往需要很少的时间来微调,实际上,如果你查看Bert的论文,建议微调的时间数在2到4之间。
另一方面,我通常会在一两个时期内找到最佳值,这也与您的情况一致。我的猜测是:当微调预训练模型时,在适应下游任务和忘记预训练中学习的权重之间存在一种权衡。根据你掌握的数据,平衡点可能迟早会出现,然后开始过度拟合。但这一段是根据我的经验推测出来的。
-
关于使用Lenet5网络解释MNIST上某些优化器的性能,我有几个问题,以及验证损失/精度与训练损失/精度图确切地告诉我们什么。因此,所有的事情都是在Keras中使用标准的LeNet5网络完成的,它运行了15个历元,批处理大小为128。 有两个图,列车acc vs val acc和列车损失vs val损失。我生成了4个图,因为我运行了两次,一次是validation_split=0.1,一次是va
-
我和keras在VGG网络上做了一个小实验。我使用的数据集是花卉数据集,有5个类,包括玫瑰、向日葵、蒲公英、郁金香和雏菊。 有一点我想不通:当我使用一个小的CNN网络(不是VGG,在下面的代码中)时,它收敛很快,仅经过大约8个周期就达到了大约75%的验证准确率。 然后我切换到VGG网络(代码中注释掉的区域)。网络的损失和准确性根本没有改变,它输出如下内容: 纪元1/50 402/401 [====
-
问题内容: 我有一个“一键编码”(全1和全0)的数据矩阵,具有260,000行和35列。我正在使用Keras训练简单的神经网络来预测连续变量。组成网络的代码如下: 但是,在训练过程中,我看到损失下降得很好,但是在第二个时期的中间,它就变成了nan: 我尝试使用代替,尝试替代,尝试使用和不使用辍学,但都无济于事。我尝试使用较小的模型,即仅具有一个隐藏层,并且存在相同的问题(在不同的点它变得很困难)。
-
问题内容: 我正在看TensorFlow“ MNIST对于ML初学者”教程,我想在每个训练步骤之后打印出训练损失。 我的训练循环目前看起来像这样: 现在,定义为: 我要打印的损失在哪里: 一种打印方式是在训练循环中显式计算: 我现在有两个问题: 鉴于已经在期间进行了计算,因此将其计算两次效率低下,这需要所有训练数据的前向通过次数的两倍。有没有一种方法可以访问在计算期间的value ? 我如何打印?
-
问题内容: 目前,我使用以下代码: 它告诉Keras,如果损失在2个时期内没有改善,就停止训练。但是我要在损失小于某个恒定的“ THR”后停止训练: 我在文档中已经看到有可能进行自己的回调:http : //keras.io/callbacks/ 但没有找到如何停止训练过程的方法。我需要个建议。 问题答案: 我找到了答案。我调查了Keras的资源,并找到了EarlyStopping的代码。我基于此
-
嗨,我正在尝试创建一个VariationalDenseLayer,其中KL损失在调用函数中计算。 然而,当我试图将我的最终损失定义为neg_log_likelihhoodkl_loss时,我得到了以下错误: TypeError:函数构建代码之外的op被传递一个“图形”张量。通过包含tf,可以使图张量从函数构建上下文中泄漏出来。函数构建代码中的init_范围。例如,以下函数将失败:@tf。函数def