
opencsv:如何在单元格内用双引号解析数据?

我正在尝试使用opencsv(3.10版)解析一些公共数据。以下是获取CSV并将记录映射到POJO列表的代码片段:
URL permitsURL = new URL("http://assessor.boco.solutions/ASR_PublicDataFiles/Permits.csv");
InputStream permitInputStream = permitsURL.openStream();
Reader permitStreamReader = new InputStreamReader(permitInputStream);
CsvToBean<PermitRecord> csvToBean = new CsvToBean<PermitRecord>();
Map<String, String> columnMapping = new HashMap<String, String>();
columnMapping.put("strap", "strap");
columnMapping.put("issued_by", "issuedBy");
columnMapping.put("permit_num", "permitNum");
columnMapping.put("permit_category", "permitCategory");
columnMapping.put("issue_dt", "issueDt");
columnMapping.put("estimated_value", "estimatedValue");
columnMapping.put("description", "description");
HeaderColumnNameTranslateMappingStrategy<PermitRecord> strategy = new HeaderColumnNameTranslateMappingStrategy<PermitRecord>();
strategy.setType(PermitRecord.class);
strategy.setColumnMapping(columnMapping);
List<PermitRecord> permitRecordList = null;
CSVReader csvReader = new CSVReader(permitStreamReader);
permitRecordList = csvToBean.parse(strategy, csvReader);
解析列表中的记录比CSV中的少。查看数据,我注意到单元格值中有时会有双引号。这是一个例子:
"R0601364 ","LAFAYETTE","14-0486","DECK","4/29/2014 12:00:00 AM","3834","deck under 36\"""
"R0601365 ","LAFAYETTE","13-0570","NEW CONSTRUCTION","5/22/2013 12:00:00 AM","121899","SIN FAMILY HOME PLN CUSTOM FIN BASEMENT"
“36”以下的组块导致后续记录与描述一致。通过IDE查看时,这一点更为明显:
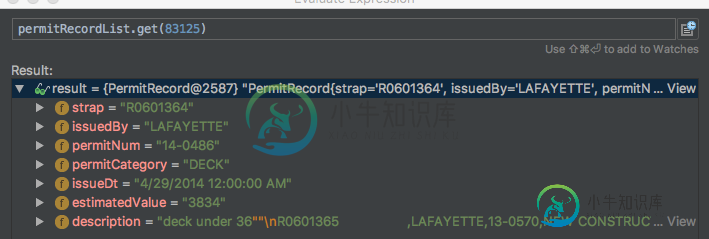
你能看出我做错了什么吗?我怀疑有一个简单的解决方案,因为Excel正确解析了它,而opencsv似乎是Java CSV解析的实际标准。
共有1个答案

Univocity CSV解析器非常易于使用。将CSV列映射到POJO属性很容易。
我在pom中添加了以下依赖项。xml:
<dependency>
<groupId>com.univocity</groupId>
<artifactId>univocity-parsers</artifactId>
<version>2.5.4</version>
</dependency>
CSV列使用注释映射到属性。请注意方便的注释:
Parsed(field=“abc”):将CSV列映射到变量@Trim:删除前导/尾随空格@Format(formats={“MM/dd/yyyy”}):允许我们指定日期格式
以下是POJO:
package io.woolford.entity;
import com.univocity.parsers.annotations.Format;
import com.univocity.parsers.annotations.Parsed;
import com.univocity.parsers.annotations.Trim;
import java.util.Date;
public class PermitRecord {
@Trim
@Parsed(field = "strap")
private String strap;
@Parsed(field = "issued_by")
private String issuedBy;
@Parsed(field = "permit_num")
private String permitNum;
@Parsed(field = "permit_category")
private String permitCategory;
@Format(formats = {"MM/dd/yyyy"})
@Parsed(field = "issue_dt")
private Date issueDt;
@Parsed(field = "estimated_value")
private Integer estimatedValue;
@Parsed(field = "description")
private String description;
// getters & setters removed for brevity
}
然后,要从CSV文件中的记录创建POJO列表:
URL permitsURL = new URL("http://assessor.boco.solutions/ASR_PublicDataFiles/Permits.csv");
InputStream permitInputStream = permitsURL.openStream();
List<PermitRecord> permitRecordList = new CsvRoutines().parseAll(PermitRecord.class, permitInputStream);
这一优雅的解决方案归功于@JeronimoBackes。感谢Univocity提供出色的CSV解析器。
-
我正在尝试使用OpenCSV解析CSV文件。其中一列以YAML序列化格式存储数据,并被引用,因为其中可以包含逗号。它里面也有引号,所以它通过放两个引号来转义。我能够在Ruby中轻松解析这个文件,但使用OpenCSV我无法完全解析它。这是一个UTF-8编码的文件。 这是我的Java片段,它试图读取文件 这是此文件中的2行。第一行没有被正确解析,并且在处被拆分,因为我猜是转义双引号。
-
我正在使用opencsv读取csv文件。有时csv文件中包含单引号或双引号。如何读取它们而不更改csv文件本身中的数据。 现在,如果我用两个单引号替换一个单引号,它工作正常,与双引号相同,用两个替换单个引号,它的工作原理。但我不想碰源文件。 要访问的代码如下: 这样做的结果是跳过下一行(也包含双引号),插入所有奇数行,跳过偶数行 提前谢谢
-
我有以下csv文件, 我无法用opencsv jar读取上述csv文件。它无法读取,因为数据中有双引号。我的csv阅读器构造函数如下所示:,
-
问题内容: 如何使用PHP 用(我认为其称为单引号)替换(我认为它称为双引号)? 问题答案: 或重新分配
-
我目前正在使用一个替换脚本来自动修复单引号和双引号。 但是,我找不到一个解决方案来更改嵌套在另一个双引号内的任何地方的双引号 “在'abc'开头和结尾有一些额外的文本” 目前,我只能自动修复这个类型,如果它在其他引号旁边(例如“abc”)使用一个简单的替换脚本 和
-
问题内容: 我正在读取CSV文件,并且有一些值,例如 将文件读取为并转换后,我将文件内容分割为:。 在迭代字符串时,我得到以下值: 如何将两个双引号替换为像这样的“双”的单双 这是我的代码:- 问题答案: 使用。 http://ideone.com/xPQqL