
Azure Databricks,无法读取带有嵌套列表的逗号分隔的CSV文件

我有一个相当大的逗号分隔的CSV文件(12GB)。我有4列,其中1列包含带有JSON的嵌套列表。我可以从Excel创建一个连接,它可以正确地读取它(尽管我在那里有一些嵌套列表,这意味着更多的逗号)。然而,当我试图通过spark来实现它时,它在每次出现逗号时都会被切分,这造成了很多混乱。
好的,所以我已经尝试提供一个模式。显然CSV不支持数组类型,所以我不能这么容易地做到这一点。我可以用字符串而不是数组定义模式,但我的最后一列如下所示:
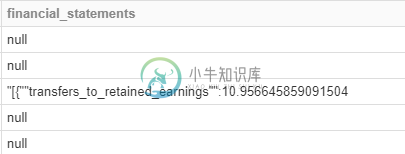
所以,我得到了第一个逗号之前的一切,Rest就消失了。


与类似定义的模式相同:
user_schema = StructType([
StructField("businessID", StringType(), True),
StructField("vid", StringType(), True),
StructField("company_name", StringType(), True),
StructField("financial_statements", StringType(), True)
])
共有1个答案

尝试[作为选项
val schema = StructType(
Seq(
StructField("businessID", StringType),
StructField("vid", StringType),
StructField("company_name", StringType),
StructField("financial_statements", StringType),
),
)
val df = spark.read
.schema(schema)
.format("csv")
.option("quote", "[")
.load(path)
val jsonSchema = StructType(
Seq(
StructField("key1", StringType),
StructField("key2", IntegerType),
StructField("key3", BooleanType),
),
)
val dfClean = df.withColumn("financial_statements_json", from_json($"financial_statements", jsonSchema))
dfClean.printSchema()
dfClean.show(false)
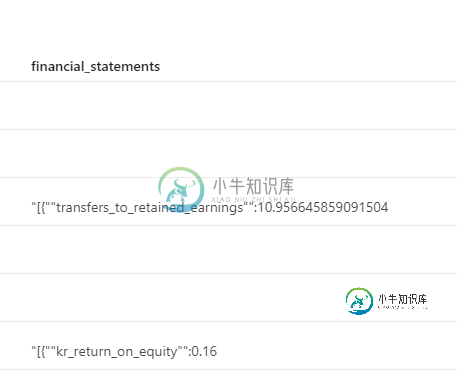
产出:
+----------+---+------------+-------------------------------------------+-------------------------+
|businessID|vid|company_name|financial_statements |financial_statements_json|
+----------+---+------------+-------------------------------------------+-------------------------+
|1 |A |AAA |{"key1": "va1", "key2": 123, "key3": true}]|[va1, 123, true] |
+----------+---+------------+-------------------------------------------+-------------------------+
-
我有一个txt文件,数据如下所示 我在使用这段代码时读到了数据: 由于我的时间列,它不能正常工作,因为是通过逗号分隔的。我该如何解决这一点,如何使它工作,即使在我有多列这样的时间格式的情况下? 我想获得一个如下所示的数据帧: 多谢!
-
问题内容: 我有看起来像这样的数据: 对于每个customer_id,我需要用逗号分隔的列表,以指示该客户运营的月份: 等等。如何使用SQL Server 2005 SQL(而不是T-SQL)轻松生成此逗号分隔的列表? 我在Stack Overflow和其他地方在这里看到的大多数解决方案似乎都是基于联接多个行值而不是列值来创建逗号分隔的列表: T-SQL FOR XML路径(’‘) 关联的子查询与
-
目标:创建一个面向对象的图形Java应用程序,该程序将:读取一个CSV(逗号分隔值)文件,该文件由学生姓名(名字、姓氏)、ID以及内容和交付的初始标记组成(未评估学生使用-1值)。 这是我的代码,但当我点击选择文件。。当它真的应该打开文件并读取数据时,它会显示“预期的名字、姓氏、ID、内容和交付”。但不知何故,它不起作用。在此处输入图像描述 下面是我的代码: 私有类ChooseFileListen
-
问题内容: 我正在读取一个基本的csv文件,其中这些列用逗号分隔,这些列名称分别为: 但是,主体列是一个字符串,可能包含逗号。显然,这会导致问题,并且熊猫抛出错误: 有没有一种方法可以告诉熊猫忽略特定列中的逗号,或者可以解决该问题? 问题答案: 想象一下,我们正在读取名为的数据框: 您可以做的一件事是使用以下命令在列中指定字符串的定界符: 在这种情况下,以逗号分隔的字符串将被视为总数,而不管它们之
-
问题内容: 我需要运行类似的查询: 但是我希望子选择返回逗号分隔的列表,而不是数据列。这有可能吗?如果可以,怎么办? 问题答案: 您可以使用GROUP_CONCAT执行该操作,例如