
尽可能高效地在矩阵中查找序列

很少的要求。
在发布你的答案之前,请!!
1)确保函数不会对其他数据产生错误,模拟几个类似的矩阵。(关掉种子)
2)确保你的功能比我的快
3)确保你的函数和我的完全一样,在不同的矩阵上模拟它(关闭种子)
举个例子
for(i in 1:500){
m <- matrix(sample(c(F,T),30,T),ncol = 3) ; colnames(m) <- paste0("x",1:ncol(m))
res <- c(my_fun(m),your_function(m))
print(res)
if(sum(res)==1) break
}
m
目前我已收到多达5个答案,但没有一个适合上述任何一点:
======================================================函数在逻辑矩阵的第一列中查找真,如果找到真,则转到第2列和新行,依此类推。。如果找到序列,则返回trueIf notfalse
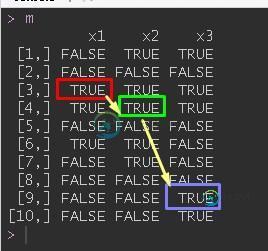
set.seed(15)
m <- matrix(sample(c(F,T),30,T),ncol = 3) ; colnames(m) <- paste0("x",1:ncol(m))
m
x1 x2 x3
[1,] FALSE TRUE TRUE
[2,] FALSE FALSE FALSE
[3,] TRUE TRUE TRUE
[4,] TRUE TRUE TRUE
[5,] FALSE FALSE FALSE
[6,] TRUE TRUE FALSE
[7,] FALSE TRUE FALSE
[8,] FALSE FALSE FALSE
[9,] FALSE FALSE TRUE
[10,] FALSE FALSE TRUE
我的慢示例函数
find_seq <- function(m){
colum <- 1
res <- rep(FALSE,ncol(m))
for(i in 1:nrow(m)){
if(m[i,colum]==TRUE){
res[colum] <- TRUE
print(c(row=i,col=colum))
colum <- colum+1}
if(colum>ncol(m)) break
}
all(res)
}
find_seq(m)
row col
3 1
row col
4 2
row col
9 3
[1] TRUE
如何使它尽可能快?
UPD=========================
I showed a test of only those functions that meet all three points above.
microbenchmark::microbenchmark(Jean_Claude_Arbaut_fun(m),
+ ThomasIsCoding_fun(m),
+ my_fun(m))
Unit: microseconds
expr min lq mean median uq max neval cld
Jean_Claude_Arbaut_fun(m) 2.850 3.421 4.36179 3.9915 4.5615 27.938 100 a
ThomasIsCoding_fun(m) 14.824 15.965 17.92030 16.5350 17.1050 101.489 100 b
my_fun(m) 23.946 24.517 25.59461 25.0880 25.6580 42.192 100 c
共有3个答案

如果您的示例具有代表性,我们假设nrow(m)
ff = function(m)
{
i1 = 1
for(j in 1:ncol(m)) {
i1 = match(TRUE, m[i1:nrow(m), j]) + i1
#print(i1)
if(is.na(i1)) return(FALSE)
}
return(TRUE)
}

如果我正确地理解了这个问题,一个行循环就足够了。以下是使用Rcpp实现这一点的方法。这里我只返回真/假答案,如果你需要索引,它也是可行的。
library(Rcpp)
cppFunction('
bool hasSequence(LogicalMatrix m) {
int nrow = m.nrow(), ncol = m.ncol();
if (nrow > 0 && ncol > 0) {
int j = 0;
for (int i = 0; i < nrow; i++) {
if (m(i, j)) {
if (++j >= ncol) {
return true;
}
}
}
}
return false;
}')
a <- matrix(c(F, F, T, T, F, T, F, F, F, F,
T, F, T, T, F, T, T, F, F, F,
T, F, T, T, F, F, F, F, T, T), ncol = 3)
a
hasSequence(a)
为了获得索引,下面的函数返回一个列表,其中至少有一个元素(名为'found',true或false),如果found=true,则另一个元素名为'indexs':
cppFunction('
List findSequence(LogicalMatrix m) {
int nrow = m.nrow(), ncol = m.ncol();
IntegerVector indices(ncol);
if (nrow > 0 && ncol > 0) {
int j = 0;
for (int i = 0; i < nrow; i++) {
if (m(i, j)) {
indices(j) = i + 1;
if (++j >= ncol) {
return List::create(Named("found") = true,
Named("indices") = indices);
}
}
}
}
return List::create(Named("found") = false);
}')
findSequence(a)
了解Rcpp的几个链接:
你必须至少了解一点C语言(最好是C,但是对于一个基本的用法,你可以把Rcpp想象成带有R数据类型一些神奇语法的C)。第一个链接解释了Rcpp类型的基础知识(向量、矩阵和列表,如何分配、使用和返回它们)。其他链接是很好的补充。

如果你追求的是速度,可以试试下面的R基解
TIC_fun <- function(m) {
p <- k <- 1
nr <- nrow(m)
nc <- ncol(m)
repeat {
if (p > nr) {
return(FALSE)
}
found <- FALSE
for (i in p:nr) {
if (m[i, k]) {
# print(c(row = i, col = k))
p <- i + 1
k <- k + 1
found <- TRUE
break
}
}
if (!found) {
return(FALSE)
}
if (k > nc) {
return(TRUE)
}
}
}
你会看到
Unit: microseconds
expr min lq mean median uq max neval
my_fun(m) 18.600 26.3010 41.46795 41.5510 44.3010 121.302 100
TIC_fun(m) 10.201 14.1515 409.89394 22.6505 24.4005 38906.601 100
你可以试试下面的代码
lst <- with(as.data.frame(which(m, arr.ind = TRUE)), split(row, col))
# lst <- apply(m, 2, which)
setNames(
stack(
setNames(
Reduce(function(x, y) y[y > x][1],
lst,
init = -Inf,
accumulate = TRUE
)[-1],
names(lst)
)
),
c("row", "col")
)
这给了
row col
1 3 1
2 4 2
3 9 3
一个更有趣的实现可能是使用递归(只是为了好玩,但由于效率低下,不推荐使用)
f <- function(k) {
if (k == 1) {
return(data.frame(row = which(m[, k])[1], col = k))
}
s <- f(k - 1)
for (i in (tail(s, 1)$row + 1):nrow(m)) {
if (m[i, k]) {
return(rbind(s, data.frame(row = i, col = k)))
}
}
}
这给了
> f(ncol(m))
row col
1 3 1
2 4 2
3 9 3
-
假设我们想检查一个矩阵(或数据框)中的哪些行存在于另一个矩阵中。我找到的所有解决方案,这个肯定基本的操作似乎要么需要一个库(这个{data.table} 4-线性),要么是冗长和模糊的,例如: 有人知道一种使用基函数的更优雅的方法,其效率与本例相当吗? 代码无效。
-
问题内容: 在这里处理一些矩阵代数。有时我需要将一个可能为奇数或病态的矩阵求逆。我知道简单地做到这一点是pythonic的: 但不确定效率如何。这会更好吗? numpy.linalg是否可以简单地执行我所要求的测试? 问题答案: 因此,根据此处的输入,我将显式测试标记为原始代码块作为解决方案: 令人惊讶的是,numpy.linalg.inv函数不执行此测试。我检查了一下代码,发现它经过了所有处理,
-
问题内容: 我正在尝试编写一种算法,用于在给定的子矩阵中查找子矩阵。为了解决这个问题,我编写了以下代码: 这段代码可以正常工作,但是我不确定这是问题的确切解决方案还是可以解决。请提供您的专家意见。提前致谢。 问题答案: 该算法对4×4矩阵和2×2子矩阵进行了硬编码。否则,它看起来像蛮力算法。 我会这样表示: 如果您想要更有效的方法,建议您将它们压扁,如下所示: 并在此序列中搜索以下模式: 使用标准
-
问题内容: 这是我目前的方式。有什么办法可以使用矩阵运算吗?X是数据点。 问题答案: 您是否要使用高斯核进行图像平滑?如果是这样,则scipy中有一个函数: 更新的答案 这应该可以工作- 尽管仍不能100%准确,但它会尝试考虑网格每个像元内的概率质量。我认为在每个像元的中点使用概率密度的准确性稍差,尤其是对于小内核。有关示例,请参见https://homepages.inf.ed.ac.uk/rb
-
在一个m行n列二维数组中,每一行都按照从左到右递增的顺序排序,每一列都按照从上到下递增的顺序排序。请完成一个函数,输入这样的一个二维数组和一个整数,判断数组中是否含有该整数。 使用Step-wise线性搜索。 def get_value(l, r, c): return l[r][c] def find(l, x): m = len(l) - 1 n = len(l[0]) - 1
-
问题陈述:- 我想在每个k个列表中搜索单个元素。 显然,我可以单独对每个数组进行二分搜索,这将得到O(k log n),其中k是排序数组的数目。 我们能在O(k+logn)中做吗,其中k是排序数组的个数?我想可能有更好的方法,因为我们现在做了k次同样的搜索- 这有可能实现吗?谁能提供一个例子,这是如何工作的基础上我的例子?