
Selenium ChromeDriver:增加WebElement文本获取时间

我有一个代码,我在其中遍历表的行和列,我想把它的值添加到列表中。
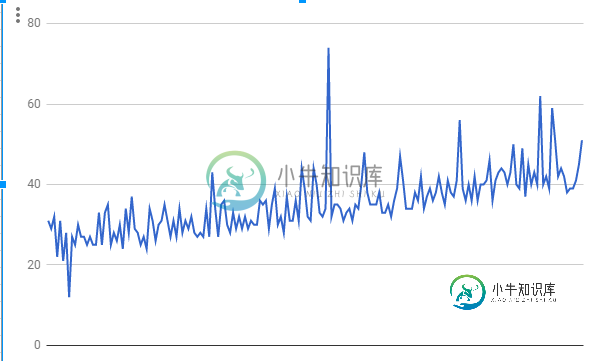
这花了我很多时间。
所以我添加了一个时间度量,我注意到由于某种原因,时间从行到行都在增加。
我不明白为什么。
你能给我个建议吗?
private void buildTableDataMap() {
WebElement table = chromeWebDriver.findElement(By.id("table-type-1"));
List<WebElement> rows = table.findElements(By.tagName("tr"));
theMap.getInstance().clear();
String item;
for (WebElement row : rows) {
ArrayList<String> values = new ArrayList<>();
List<WebElement> tds = row.findElements(By.tagName("td"));
if(tds.size() > 0){
WebElement last = tds.get(tds.size() - 1);
long time = System.currentTimeMillis();
values.addAll(tds.stream().map(e->e.getText()).collect(Collectors.toList()));
System.out.println(System.currentTimeMillis() - time);
//remove redundant last entry:
values.remove(tds.size() - 1);
callSomeFunc(values, last);
item = tds.get(TABLE_COLUMNS.NAME_COL.getNumVal()).getText();
item = item.replaceAll("[^.\\- /'&A-Za-z0-9]", "").trim();//remove redundant chars
theMap.getInstance().getMap().put(item, values);
}
}
}
伙计们,我继续调查。首先,Florent友好的回答对我没有帮助,因为,至少据我所知,它返回给我一个字符串数组列表,我必须解析,我不太喜欢这种解决方案······
WebElement last = null;
for (WebElement e : tds){
last = e;
long tm1 = 0, tm2 = 0;
if(Settings.verboseYN) {
tm1 = System.currentTimeMillis();
}
s = e.getText(); //This action increases in time!!!
if(Settings.verboseYN) {
tm2 = System.currentTimeMillis();
}
values.add(s); //a 0 ms action!!!
if(Settings.verboseYN) {
System.out.println("e.getText()) took " + (tm2 - tm1) + " ms...");
}
}
void func(WebElement anchorsElement){
List<WebElement> anchors = anchorsElement.findElements(By.tagName("a"));
for (WebElement a : anchors) {
if (a.getAttribute("class").indexOf("a") > 0)
values.add("A");
else if (a.getAttribute("class").indexOf("b") > 0)
values.add("B");
else if (a.getAttribute("class").indexOf("c") > 0)
values.add("C");
}
}
每个函数只有5次迭代,但是每次调用函数都会增加它的执行时间。这个问题也有解决办法吗?
共有1个答案

调用驱动程序是一个昂贵的操作。为了显著减少执行时间,使用带有executescript的JavaScript注入,在一次调用中读取整个表。然后用Java处理/过滤客户端的数据。
public ArrayList<?> readTable(WebElement table)
{
final String JS_READ_CELLS =
"var table = arguments[0]; " +
"return map(table.querySelectorAll('tr'), readRow); " +
"function readRow(row) { return map(row.querySelectorAll('td'), readCell) }; " +
"function readCell(cell) { return cell.innerText }; " +
"function map(items, fn) { return Array.prototype.map.call(items, fn) }; " ;
WebDriver driver = ((RemoteWebElement)table).getWrappedDriver();
Object result = ((JavascriptExecutor)driver).executeScript(JS_READ_CELLS, table);
return (ArrayList<?>)result;
}
-
我使用了以下代码, 这会引发错误“表达式不是合法表达式”。“代码:“12”nsresult:“0x805b0033(SyntaxError)”位置:”“]”。 当我缩小搜索范围到 它工作正常,我得到了特定行中的所有文本。然而,当我将其扩展到特定于第1个代码中所示的列时,我得到了错误。 html代码段,
-
问题内容: 请参阅以下元素: 找到我的元素: 因此,找到后并使用带有selenium 或return 的文本: 所以我的问题是如何在没有此情况的情况下仅获得最后一行 问题答案: 所需的文本出现在文本节点中,并且无法直接使用Selenium检索,因为它仅支持元素节点。 您可以删除开头: 您还可以使用正则表达式从中提取所需的内容: 或使用一段JavaScript:
-
问题内容: 请参阅以下元素: 找到我的元素: 因此,找到后并使用带有selenium 或return 的文本: 所以我的问题是如何只获得没有这一点的最后一行 问题答案: 所需的文本出现在文本节点中,并且无法直接使用Selenium检索,因为它仅支持元素节点。 您可以删除开头: 您还可以使用正则表达式从中提取所需的内容: 或使用一段JavaScript:
-
请参阅以下元素: 找到我的元素: 因此,在找到这个并使用selenium和或获取文本后,返回: 所以我的问题是如何只得到最后一行没有这个
-
问题内容: 我想找到使用XPath基于文本的任何WebElement。 基本上,我要通过文本检索的WebElement包含一个输入元素。 我目前正在使用, 找不到上面的WebElement,但通常可以检索所有 其他Web元素。 甚至, 没有给我任何结果。虽然我对精确的文字匹配感兴趣。 我正在寻找一种通过文本来查找Web元素的方法,该文本 对Web元素内部存在的元素不重要。如果文本匹配,则应返回 W
-
我想找到任何基于使用XPath的文本的WebElement。 我感兴趣的网页元素, 它的HTML, 基本上,我试图通过文本检索的WebElement包含一个输入元素。 我目前使用的, 它找不到上面的WebElement,但通常可以检索所有其他web元素。 即使 没有给我任何结果。虽然我对精确的文本匹配感兴趣。 我正在寻找一种通过文本查找web元素的方法,该文本与web元素中存在的元素无关。如果文本