
如何将 spark 数据帧反序列化为另一个数据框 [重复]



共有1个答案

您可以为此使用爆炸函数。
from pyspark.sql.functions import explode
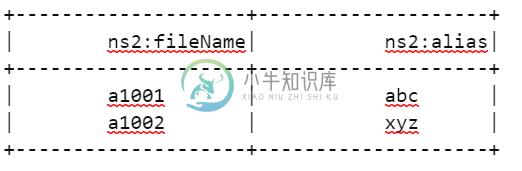
df.withColumn("ns2:fileName", explode(df.ns2:fileName))
编辑
df.withColumn("result", explode(zip($"ns2:fileName", $"ns2:alias"))).select(
$"result._1".alias("ns2:fileName"), $"result._2".alias("ns2:alias"))
可能重复。
-
情况: 两个数据帧(df1和df2)具有相同的三个索引,例如“A”、“B”、“C”。df1和df2的列数不同。df1和df2中的所有单元格都填充了float类型的数据。 DF1: DF2: 目标: 从df2中选择的列(例如“BBB”)与df1的每列相加后,结果应存储在新的数据帧(df_new)中。df_new的格式应为df1(列数和行数),并具有与df1相同的列名和索引。 new_df: 我的做法
-
我有两个数据帧df1和df2 df1如下 df2就像 我想根据df2中与df1中的列名匹配的单元格值将值从df1复制到df2,所以我的df3应该看起来像 df3 基本上,我想根据df2的单元格值(df1中的列名)从df1复制df2中的列 如果它仍然令人困惑,请告诉我
-
我正在尝试在 pyspark 中连接两个数据帧,但将一个表作为数组列连接在另一个表上。 例如,对于这些表: 我想在列和上将df1连接到df2,但和应该是单个数组类型列。此外,应保留所有名称。新数据框的输出应该能够转换为此json结构(例如前两行): 任何关于如何实现这一目标的想法都将不胜感激! 谢谢, 卡罗莱纳州
-
我有一个数据框 我有另一个数据帧df2 我希望我的最终数据帧看起来像: i、 e从一个数据帧映射到另一个数据帧,创建新列
-
我有两个数据帧df1和df2。df1就像一个具有以下值的字典 df2具有以下值: 我想基于df1数据帧中的,将df2拆分为3个新的数据帧。 日期,TLRA_权益栏应位于数据框 预期产出: > 数据帧 消费者,非周期性数据帧 请让我知道如何有效地做。我想做的是连接列名,例如,然后根据列名的前半部分分割数据帧。 代码: 但这很复杂。需要更好的解决方案。
-
我需要将下面两个foramt反序列化为单个代码中的 嵌套异常是org.springframework.http.converter.httpmessageNotreadableException:JSON解析错误:无法反序列化字符串类型的值“2020-04-23t10:51:24.238+01:00”:com.fasterxml.jackson.databind.exc.invalidformat