
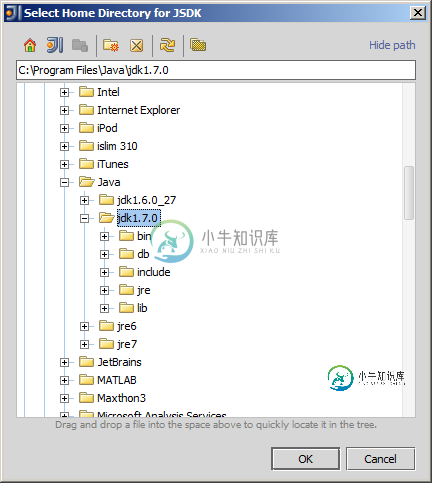
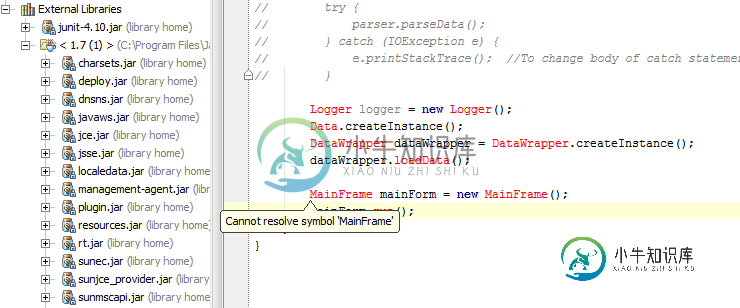
IntelliJ IDEA无法设置JDK

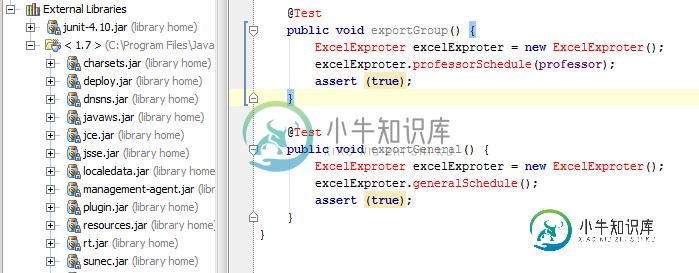
所以我告诉IDEA它应该使用什么JDK,但它仍然要求我设置一个JDK。这是一个窃听器还是我遗漏了什么?我能应用任何变通方法使一切照常工作吗?



共有1个答案

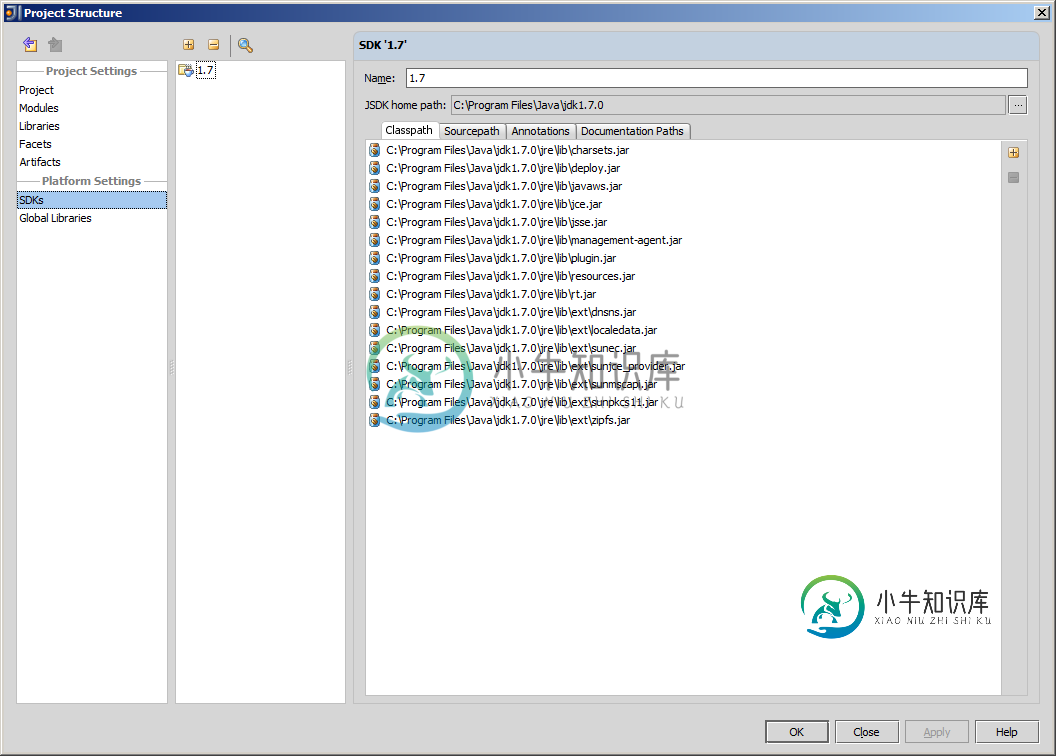
文件无效缓存是遇到此类问题时首先应该尝试的事情。
-
JSON查询应该可以使用多个搜索参数。为此,服务器需要获取每个参数作为搜索对象,例如: 我们在swagger中使用下面的声明: 问题是,从swagger生成的PHP库创建的请求如下: 这是服务器无法使用的。为了解决这个问题,我发现可以通过将属性“collectionFormat”设置为csv而不是multi来影响这个行为。 我的问题是,声明取自示例页面https://swagger.io/docs
-
问题内容: 我正在尝试在Django中开发示例项目,并且在运行syncdb命令时遇到错误。 这是我的项目结构的样子: / Users / django_demo / godjango / bookings: 我的manage.py文件如下: 我的PYTHONPATH和DJANGO_SETTINGS_MODULE设置如下 我的WSGI.py文件如下所示: 当我运行python manage.py s
-
我试图在具有动态输入字段的pdf表单中设置值,但流编写器不断出错。 我研究了填写表格(http://mail-archives.apache.org/mod_mbox/pdfbox-users/201510.mbox/browser)的步骤,并阅读了类似的问题结合XFA与PDFBox和PDFBox臃肿的PDF文件大小 有什么不同的方法吗?有什么建议可以引导我走向正确的方向吗? 这是我的代码 这就是
-
我在设置kubernetes ingress-nginx时遇到了麻烦,以便在外部公开我的应用程序。下面是我所做的步骤: 应用程序部署: 创建了名为Ingress的命名空间 部署了statefulset集资源,用于在入口命名空间中描述我的应用程序(我们称之为testapp) 创建了ClusterIP服务,使我的应用程序在kube集群(testapp)中的入口命名空间中可用 入口nginx设置: nu
-
我正在尝试执行以下操作以避免稍后未选中的转换: 强制取消行上未选中得强制转换: 我如何做到这一点而不需要抑制?