
使用OpenCV检测图像中已知形状/物体的方法

我的任务是使用OpenCV检测给定图像中的对象(我不关心它是Python还是C++实现)。下面的三个示例中显示的对象是一个黑色矩形,其中包含五个白色矩形。所有维度都是已知的。

但是,图像的旋转、比例、距离、透视、光照条件、相机对焦/镜头、背景都是未知的。黑色矩形的边缘不能保证是完全可见的,但是在五个白色矩形前面不会有任何东西--它们总是完全可见的。最终目标是能够在图像中检测到该对象的存在,并旋转、缩放和裁剪以显示该对象,同时去掉透视。我很有信心,我可以调整图像,以裁剪正好对象,给定它的四个角。然而,我不是那么有信心,我可以可靠地找到那四个角。在模棱两可的情况下,找不到对象比错误地识别图像的某些其他特征为对象更好。
使用OpenCV我想出了以下方法,但是我觉得我可能缺少一些明显的东西。是否还有其他可用的方法,或者这些方法中的一种是最优解?
第一个想法是寻找物体的外边缘。
利用Canny边缘检测(缩放到已知的大小,灰度化和高斯模糊化后),找到一个与物体外形最匹配的轮廓。这处理透视,颜色,大小问题,但当有一个复杂的背景,例如,如果有一些东西的形状类似的对象在图像的其他地方。也许这可以通过一套更好的规则来找到正确的轮廓--也许包括五个白色矩形以及外边缘。
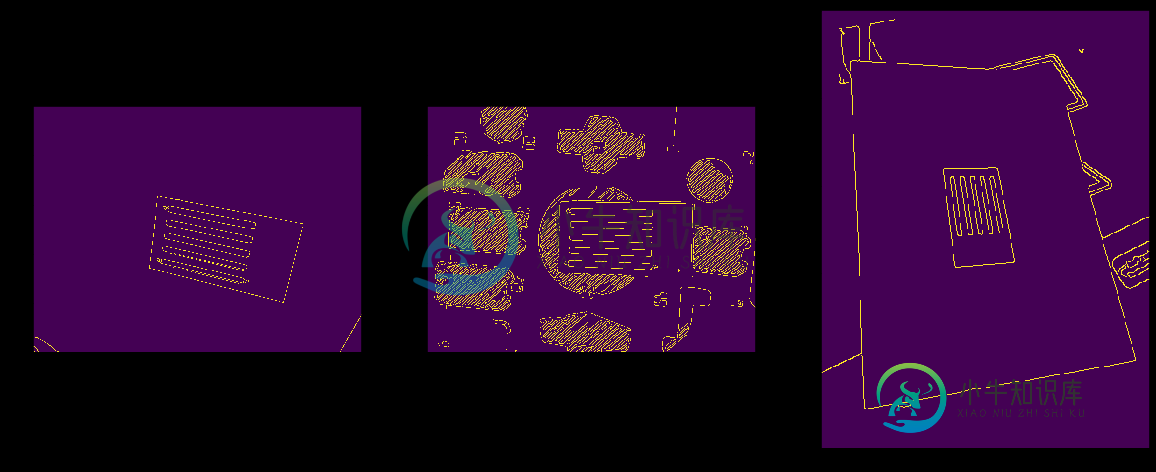
接下来的想法是使用特征检测来匹配一个已知的模板。
使用ORB特征检测、描述符匹配和单应性(来自本教程)失败了,我相信是因为它正在检测的特征与对象中的其他特征非常相似(很多Corener精确地是四分之一白和四分之三黑)。然而,我确实喜欢匹配到已知模板的想法--这个想法对我来说是有意义的。我想,因为对象在几何上是非常基本的,所以在特征匹配步骤中很可能会发现很多误报。

使用Houghlines或HoughLinesP,寻找间隔均匀的平行线。我刚刚开始这条路,所以需要研究阈值化的最佳方法等。虽然复杂背景的图像看起来很乱,但我认为它可能会很好地工作,因为我可以依赖于这样一个事实,即黑色物体中的白色矩形应该总是高对比度的,给出线在哪里的良好指示。

我最后的想法是通过行扫描图像,寻找从白到黑的模式。
我还没有开始这种方法,但想法是将图像取一条带(以某种角度),转换到HSV颜色空间,并寻找值列中依次出现五次的规则的黑白模式。这个想法听起来很有希望,因为我认为它应该忽略许多未知的变量。
我已经看了很多OpenCV教程,以及像这一个这样的问题,但是,由于我的对象在几何上非常简单,我在实现给出的思想时遇到了问题。
我觉得这是一个可以实现的任务,但我的斗争是知道哪种方法继续下去。我已经对前两个想法进行了相当多的实验,虽然我还没有实现任何非常可靠的东西,但也许我缺少了一些东西。有没有一种我没有想到的标准方法来完成这项任务,或者是我建议的方法中的一种是最明智的?
编辑:一旦使用上述方法之一(或其他方法)找到角点,我正在考虑使用Hu矩或OpenCV的matchShapes()函数来去除任何误报。
Edit2:根据@Timo的请求添加了更多的输入图像示例
- 原始1
- 原始2
- 原始3
- 额外图像1
- 额外图像2
- 额外图像3
- 额外图像4
共有1个答案

我花了一些时间研究这个问题,并制作了一个小的python脚本。我在检测你形状里的白色矩形。将代码粘贴到.py文件中,并复制输入子文件夹中的所有输入图像。映像的最终结果只是一个虚拟atm机,脚本还没有完成。我会试着在接下来的几天里继续。脚本将创建一个debug子文件夹,在其中保存一些显示当前检测状态的图像。
import numpy as np
import cv2
import os
INPUT_DIR = 'input'
DEBUG_DIR = 'debug'
OUTPUT_DIR = 'output'
IMG_TARGET_SIZE = 1000
# each algorithm must return a rotated rect and a confidence value [0..1]: (((x, y), (w, h), angle), confidence)
def main():
# a list of all used algorithms
algorithms = [rectangle_detection]
# load and prepare images
files = list(os.listdir(INPUT_DIR))
images = [cv2.imread(os.path.join(INPUT_DIR, f), cv2.IMREAD_GRAYSCALE) for f in files]
images = [scale_image(img) for img in images]
for img, filename in zip(images, files):
results = [alg(img, filename) for alg in algorithms]
roi, confidence = merge_results(results)
display = cv2.cvtColor(img, cv2.COLOR_GRAY2BGR)
display = cv2.drawContours(display, [cv2.boxPoints(roi).astype('int32')], -1, (0, 230, 0))
cv2.imshow('img', display)
cv2.waitKey()
def merge_results(results):
'''Merges all results into a single result.'''
return max(results, key=lambda x: x[1])
def scale_image(img):
'''Scales the image so that the biggest side is IMG_TARGET_SIZE.'''
scale = IMG_TARGET_SIZE / np.max(img.shape)
return cv2.resize(img, (0,0), fx=scale, fy=scale)
def rectangle_detection(img, filename):
debug_img = cv2.cvtColor(img, cv2.COLOR_GRAY2BGR)
_, binarized = cv2.threshold(img, 50, 255, cv2.THRESH_BINARY)
contours, _ = cv2.findContours(binarized, cv2.RETR_LIST, cv2.CHAIN_APPROX_SIMPLE)
# detect all rectangles
rois = []
for contour in contours:
if len(contour) < 4:
continue
cont_area = cv2.contourArea(contour)
if not 1000 < cont_area < 15000: # roughly filter by the volume of the detected rectangles
continue
cont_perimeter = cv2.arcLength(contour, True)
(x, y), (w, h), angle = rect = cv2.minAreaRect(contour)
rect_area = w * h
if cont_area / rect_area < 0.8: # check the 'rectangularity'
continue
rois.append(rect)
# save intermediate results in the debug folder
rois_img = cv2.drawContours(debug_img, contours, -1, (0, 0, 230))
rois_img = cv2.drawContours(rois_img, [cv2.boxPoints(rect).astype('int32') for rect in rois], -1, (0, 230, 0))
save_dbg_img(rois_img, 'rectangle_detection', filename, 1)
# todo: detect pattern
return rois[0], 1.0 # dummy values
def save_dbg_img(img, folder, filename, index=0):
'''Writes the given image to DEBUG_DIR/folder/filename_index.png.'''
folder = os.path.join(DEBUG_DIR, folder)
if not os.path.exists(folder):
os.makedirs(folder)
cv2.imwrite(os.path.join(folder, '{}_{:02}.png'.format(os.path.splitext(filename)[0], index)), img)
if __name__ == "__main__":
main()
下面是当前WIP的示例图像
下一步是检测多个矩形之间的模式/关系。当我有进展时,我会更新这个答案。
-
本文向大家介绍使用OpenCV检测图像中的矩形,包括了使用OpenCV检测图像中的矩形的使用技巧和注意事项,需要的朋友参考一下 本文实例为大家分享了OpenCV检测图像中矩形的具体代码,供大家参考,具体内容如下 前言 1.OpenCV没有内置的矩形检测的函数,如果想检测矩形,要自己去实现。 2.我这里使用的OpenCV版本是3.30. 矩形检测 1.得到原始图像之后,代码处理的步骤是: (1)滤波
-
我试图通过OpenCV(Python)的图像预处理技术来检测黑白足球。我的想法如下; 处理图像(例如模糊的二进制照片) 找到多个候选足球(例如通过轮廓检测) 调整这些候选者的大小(例如48x48px),并在一个非常简单的神经网络中输入其像素对应的布尔值(0=黑色像素,1=白色像素),然后为每个候选者输出置信度值 确定足球是否存在于照片中,以及球的最可能位置 我一直在寻找合适的候选人。目前,这是我的
-
我想知道如何使用OpenCV在我的摄像机上检测图像。该图像可以是500个图像中的一个。 我此刻正在做的事: 我想要检测的图像是2-5KB小的。很少有人在上面发短信,但其他的只是一些迹象。这里有一个例子: 你们知道我怎么做吗?
-
本文向大家介绍基于OpenCv的运动物体检测算法,包括了基于OpenCv的运动物体检测算法的使用技巧和注意事项,需要的朋友参考一下 基于一个实现的基于OpenCv的运动物体检测算法,可以用于检测行人或者其他运动物体。 以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持呐喊教程。
-
我如何有效地检测图像层和生成的形状之间的冲突? 我需要一种快速而全面的方法来检测可旋转图像层和生成的形状之间的碰撞。 到目前为止,我只是将图像分割成一系列包含大多数像素的圆圈,然后根据其他形状测试每个圆圈。为了提高性能,我在每个结构周围创建了周界圆,只测试这些较大的圆,直到两个结构足够接近可以碰撞为止。 真正的问题是,很难将一个可旋转的矩形碰撞成这些图像结构之一。用圆形填充矩形似乎也没有效率。更不
-
我已经了解了如何使用PIL检测图像中的边缘(图像大部分是白色背景和黑色绘图标记)。如何检测包含这些边的矩形,以便裁剪图像。 例如,我想裁剪如下内容: 成: 或者这个: 成: 我熟悉PIL中的裁剪,但不知道如何围绕对象自动居中。 我已通过执行以下操作来检测边缘: 如何得到包含所有这些边的矩形?