
dplyr mutate()。根据匹配matches()选择的特定名称的其他列中的非缺失值,对一个变量进行变异时出现问题

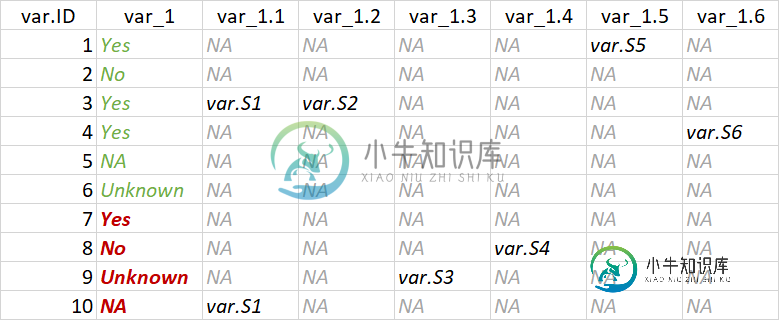
我试图根据多个其他变量中的非缺失值来改变一个变量。有一些变量,对应于是否提供测试的问题(称它们为var_1),后面是测试的结果(称它们为var_1.1、var_1.2、var_1.3等)。逻辑上,var_1中的“不”和“不”应该是指var_1.1、var_1.2、var_1.3等中的“不”吧?但有些观测值,在var_1中有“No”和“NA”,在var_1.1、var_1.2、var_1.3等中有非缺失值。所以我想把var_1中的“No”和“NA”突变成“Yes”来进行这些观察。如果你看看这个数字,我想要什么就更清楚了。var_1中的绿色变量代表正确的值。红色粗体变量不正确。总的来说,我想缩短下面的代码,让它更优雅一点:
df%>% mutate(var_1=ifelse(!is.na(var_1.1)| !is.na(var_1.2)| !is.na(var_1.3)| !is.na(var_1.4)| !is.na(var_1.n), "Yes", as.character(var_1))
以下是代码行:<code>df%
df %>% mutate_at(.vars = vars(var_1), .funs=if_else(!is.na(matches("var_1.")), "Yes", as.character(.)))
共有1个答案

我们可以对选定的列使用行总和。
cols <- grep('var_1\\.', names(df))
df$Var1[rowSums(!is.na(df[cols])) > 0] <- 'Yes'
-
本文向大家介绍根据MySQL中其他两个列的值来匹配列的值,包括了根据MySQL中其他两个列的值来匹配列的值的使用技巧和注意事项,需要的朋友参考一下 让我们首先创建一个表- 使用插入命令在表中插入一些记录- 使用select语句显示表中的所有记录- 这将产生以下输出- 以下是根据ID和MatchID显示FirstName的查询- 这将产生以下输出-
-
问题内容: 具有下表(): 另一个帮助表(): 我正在寻找一个SQL查询来输出以下内容: 所以,每一次是和是 在 响应表, 汇总 对话上下文到这一点,忽略不池中的响应结束谈话的一部分。 在上面的示例中,活动 响应文本 为1中的 3 。 我尝试了以下复杂的SQL,但有时会中断将文本汇总错误的情况: 我敢肯定有更好的方法。 问题答案: 这是我的看法: 这将扫描表一次,但是我不确定它的性能是否会比您的解
-
问题内容: 我有这样的桌子 我需要选择何时类型为0,何时类型为1,何时类型为N … 我怎样才能做到这一点? 问题答案:
-
问题内容: 假设我有这张桌子(小提琴可用)。 我按行对行进行分组,对于每个组,我都希望从column中获得一个值。但是,我不需要 任何 值,但是我想从具有maximal的行中获取值,并从所有这些中获取具有maximal的值。换句话说,我的结果应该是 当前解决方案 我知道一个查询来实现这一点: 题 但是我认为这个查询 很难看 。主要是因为它使用了一个 依赖的子查询 ,感觉就像是真正的性能杀手。因
-
问题内容: 我有以下json文件: 我正在使用jq,并想获取“位置”为“斯德哥尔摩”的对象的“名称”元素。 我知道我可以通过 但是给定子键的值(在此),我无法弄清楚如何仅打印某些对象。 问题答案: 根据关于使用jq处理JSON的文章改编而成,您可以这样使用:
-
问题内容: 从pandas数据框中选择所有行的最简单方法是什么?谁的符号在整个表中恰好出现两次?例如,在下表中,我想选择在[‘b’,’e’]中带有sym的所有行,因为这些符号的value_counts等于2。 问题答案: 我认为您可以按列和值使用: 第二个解决方案使用与布尔索引: 并用最快的解决方案和: