
使用dfs和Map的二叉树垂直顺序遍历

我正在尝试对二叉树进行垂直顺序遍历,这个问题:https://leetcode.com/problems/vertical-order-traversal-of-a-binary-tree/
我的方法是:我对树中的每个节点进行深度优先搜索,其中根为0。左边的任何内容都是当前根-1,右边的任何内容都是当前根1。我还有一个HashMap,其中键是节点的值(具有相同位置匹配的值),值是具有相同位置(键值)的所有树节点的链接列表。
当我打印HashMap的值时,我看到它将正确的元素分组在一起。
问题是,当我返回最终列表时,整数列表的顺序不正确,应该是从最大的负数到最大的正数-相反,与根位置相同的元素首先被打印出来。我想这是因为我不能用负数作为HashMap的键,但我想不出一个解决方法。
例如:
如果输入树为:
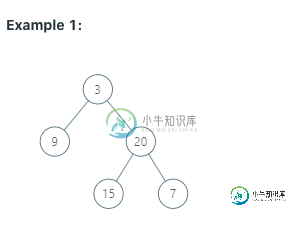
程序应该返回:[[9],[3,15],[20],[7]]
但是,我的返回:[[3,15],[9],[20],[7]]
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode() {}
* TreeNode(int val) { this.val = val; }
* TreeNode(int val, TreeNode left, TreeNode right) {
* this.val = val;
* this.left = left;
* this.right = right;
* }
* }
*/
class Solution {
public List<List<Integer>> verticalTraversal(TreeNode root) {
/*dfs getting value of node & adding it to list*/
List<List<Integer>> list = new ArrayList<>();
Map<Integer, List<Integer>> map = new HashMap<>();
if(root == null) {
return list;
}
dfs(root, map, 0);
for(Map.Entry<Integer, List<Integer>> m : map.entrySet()) {
List<Integer> temp = new ArrayList<>();
for(int i : m.getValue()) {
temp.add(i);
}
list.add(temp);
}
return list;
}
public static void dfs(TreeNode root, Map<Integer, List<Integer>> map, int curVal) {
if(root == null) {
return;
}
// System.out.println("root val = " + root.val);
// System.out.println("curVal = " + curVal);
if(map.containsKey(curVal)) {
List temp = map.get(curVal);
temp.add(root.val);
map.put(curVal, temp);
}
else {
List<Integer> tempList = new ArrayList<>();
tempList.add(root.val);
map.put(curVal, tempList);
}
dfs(root.left, map, curVal - 1);
dfs(root.right, map, curVal + 1);
}
}
共有1个答案

负键没有问题,就是少了几个东西。
>
相反,您应该按照其键值的顺序迭代映射。
当多个值被添加到同一个地图条目(因为键是相同的)时,您也将按照访问它们的顺序添加它们。但是这个顺序不能保证是所需的顺序:深度第一次迭代将在树中上下移动,所以不能保证您将在较低节点之前处理较高节点。如果你想要这样,你需要广度优先。或者,您可以将y坐标(级别)作为参数传递。
当两个节点具有相同的x和y坐标时,应按升序报告它们的值。你没有这方面的准备。如果您首先坚持使用深度,那么在地图条目中,您将需要另一个由y坐标设置关键帧的地图。然后,当您发现当前y坐标已经存在一个条目时,您应该确保以正确的顺序添加当前节点的值。请注意,这将为数据结构添加嵌套级别。最好先添加值而不进行排序,然后在算法的最后阶段遍历完整的数据结构并对所有这些小数组进行排序。
-
我尝试按如下方式执行二叉树的垂直顺序遍历:1)找出每个节点与根节点之间的最小和最大水平距离2)创建一个hashmap,将水平距离映射到相应的节点(Map) 然而,我得到了不想要的输出,我认为在实现中有一些错误,因为算法对我来说似乎是正确的。 以下是完整的代码: 输出:{-1=[99999],0=[99999,12],-2=[99999],1=[99999],2=[99999]}那么我的apProc
-
我正在学习如何使用Postorder遍历删除二叉树。我知道要删除一个节点,首先我们需要删除它的子节点,然后是节点本身,所以Postorder遍历最适合删除二叉树。我想使用Inorder遍历做同样的事情,一切都很好,但我不明白下面的代码是如何工作的?
-
我想对二叉树执行级别顺序遍历。因此,对于给定的树,说: 产出将是: 我知道我可以使用某种队列,但在C中递归地实现这一点的算法是什么?感谢您的帮助。
-
这是一个相当简单的问题,我注意到当我表示一棵树时,无论我用哪种方式(后排序,按顺序,前排序)树叶总是以相同的顺序出现,从左到右。 我只是想知道为什么,这是有原因的吗? 我刚开始研究它们,就想到了这个。 编辑: 我有一棵这样的树: 叶节点为:D、E和F 预购顺序为:A、B、D、C、E、F 顺序是:D,B,A,E,C,F 后序是:D,B,E,F,C,A 叶子节点总是从左到右出现,不管我选择哪个顺序,问
-
这是一个leetcode问题。 给定一个二叉树,返回其节点值的级序遍历(即从左到右,逐级)。 例如:给定二叉树, 将其级别顺序遍历返回为: 但我正在用JavaScript尝试一种新的方式,而不是完全按照他们的解决方案。到目前为止,我能够打印阵列,但 如何在新行中打印不同的级别 以下是我目前的代码: 输入:[3,9,20,空,空,15,7], LeetCode问题链接:BinarytreeTrave
-
我正在研究爪哇的树木,在我正在研究的书中偶然发现了一些令人困惑的台词。给出的顺序遍历图如下: 遍历(递归)的代码是: 我感到困惑的是: 我已经突出了我所困住的部分。首先,我认为在第三步中,inOrder(C)[而不是inOrder(B)]返回inOrder(A)。第二,访问节点的顺序应该是B->A->C。 请帮帮我吧!