
OpenCV和Tesseract关于门标签检测

我对OpenCv和tesseract相当陌生。我最近正在建立一个使用计算机视觉检测门标签的项目。希望这对视障群体有益。
该方案的思想是对输入图像进行二值化预处理,然后用canny边缘检测门牌轮廓,最后对canny边缘结果进行扩展。之后,将图像输入到tesseract,同时尝试显示用方框检测到的文本。
预期结果是文本上的绿色矩形。同时打印出文本本身。
问题是缺少矩形和文本检测失败。
我尝试过这些:
- 在 Opencv 中使用精明边缘检测识别图像中的文本
- OpenCv pytesseract for OCR
- 在执行字符识别之前使用 OpenCV 对图像进行预处理(镶嵌)
问题和解决方案要么过于简单,要么不那么相关。有些人也不在蟒蛇中。
下面是我对代码的尝试:
import pytesseract as pytess
import cv2 as cv
import numpy as np
from PIL import Image
from pytesseract import Output
img = cv.imread(r"C:\Users\User\Desktop\dataset\p\Image_31.jpg", 0)
# edges store the canny version of img
edges = cv.Canny(img, 100, 200)
# ker as in kernel
# (5, 5) is the matrix while uint8 is datatype
ker = np.ones((3, 3), np.uint8)
# dil as in dilation
# edges as the src, ker is the kernel we set above, number of dilation
dil = cv.dilate(edges, ker, iterations=1)
# setup pytesseract parameters
configs = r'--oem 3 --psm 6'
# feed image to tesseract
result = pytess.image_to_data(dil, output_type=Output.DICT, config=configs, lang='eng')
print(result.keys())
boxes = len(result['text'])
# make a new copy of edges
new_item = dil.copy()
for sequence_number in range(boxes):
if int(result['conf'][sequence_number]) > 30: # removed constraints
(x, y, w, h) = (result['left'][sequence_number], result['top'][sequence_number],
result['width'][sequence_number], result['height'][sequence_number])
new_item = cv.rectangle(new_item, (x, y), (x + w, y + h), (0, 255, 0), 2)
# detect sentence with tesseract
# pending as rectangle not achieved
cv.imshow("original", img)
cv.imshow("canny", edges)
cv.imshow("dilation", dil)
cv.imshow("capturedText", new_item)
#ignore below this line, it is only for testing
#testobj = Image.fromarray(dil)
#testtext = pytess.image_to_string(testobj, lang='eng')
#print(testtext)
cv.waitKey(0)
cv.destroyAllWindows()

代码的测试部分返回结果,如下所示:
a)
Meets
这显然不符合目标。
编辑
发布问题后,我意识到我一开始可能做错了。在发送矩形中的任何内容进行OCR识别之前,我应该尝试使用OpencV检测门标签的轮廓并隔离包含文本的部分。
第二版
由于我们的堆栈溢出成员,现在我发现了这个问题,现在我正尝试添加图像校正/图像包装技术来检索直前视图,以获得更好的系统准确性。很快更新。
编辑3
在修复了某些错误之后,在允许函数在原始图像上绘制的同时减少约束,我实现了以下结果。还附加了更新的代码。
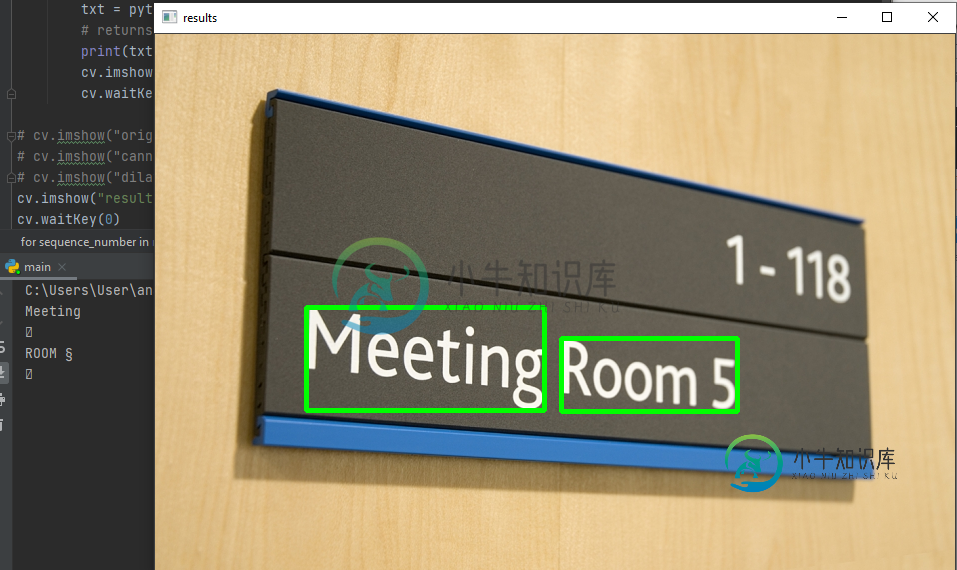
import cv2 as cv
import numpy as np
import pytesseract as pytess
from pytesseract import Output
# input of img source
img = cv.imread(r"C:\Users\User\Desktop\dataset\p\Image_31.jpg")
# necessary image color conversion
img2 = cv.cvtColor(img, cv.COLOR_BGR2GRAY)
# edges store the canny version of img
edges = cv.Canny(img2, 100, 200)
# ker as in kernel
# (5, 5) is the matrix while uint8 is datatype
ker = np.ones((3, 3), np.uint8)
# dil as in dilation
# edges as the src, ker is the kernel we set above, number of dilation
dil = cv.dilate(edges, ker, iterations=1)
# setup pytesseract parameters
configs = r'--oem 3 --psm 6'
# feed image to tesseract
result = pytess.image_to_data(dil, output_type=Output.DICT, config=configs, lang='eng')
# number of boxes that encapsulate the boxes
boxes = len(result['text'])
# make a new copy of edges
new_item = dil.copy()
for sequence_number in range(boxes):
if int(result['conf'][sequence_number]) > 0: #removed constraints
(x, y, w, h) = (result['left'][sequence_number], result['top'][sequence_number],
result['width'][sequence_number], result['height'][sequence_number])
# draw rectangle boxes on the original img
cv.rectangle(img, (x, y), (x + w, y + h), (0, 255, 0), 3)
# Crop the image
crp = new_item[y:y + h, x:x + w]
# OCR
txt = pytess.image_to_string(crp, config=configs)
# returns recognised text
print(txt)
cv.imshow("capturedText", crp)
cv.waitKey(0)
# cv.imshow("original", img)
# cv.imshow("canny", edges)
# cv.imshow("dilation", dil)
cv.imshow("results", img)
cv.waitKey(0)
cv.destroyAllWindows()
共有2个答案

我认为你在这里寻找的是图像矫正(扭曲图像,使其看起来像是从另一个角度拍摄的),而python中似乎有这样的工具。然而,问题变得更加复杂,因为在您的情况下,您需要检测您想要如何纠正它。我不知道你该怎么做。

您已在图像中找到所有检测到的文本:
for sequence_number in range(boxes):
if int(result['conf'][sequence_number]) > 30:
(x, y, w, h) = (result['left'][sequence_number], result['top'][sequence_number],
result['width'][sequence_number], result['height'][sequence_number])
new_item = cv.rectangle(new_item, (x, y), (x + w, y + h), (0, 255, 0), 2)
但你也说目前的信心应该在70%以上。
-
< li >如果我们取消限制 < li >如果我们对每个新项目进行OCR each >
结果将是:
现在,如果您阅读:
txt = pytesseract.image_to_string(new_item, config="--psm 6")
print(txt)
OCR将是:
Meeting Room §
当前pytesseract版本0.3.7的输出
代码:
# Load the libraries
import cv2
import pytesseract
# Load the image
img = cv2.imread("fsUSw.png")
# Convert it to the gray-scale
gry = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# OCR detection
d = pytesseract.image_to_data(gry, config="--psm 6", output_type=pytesseract.Output.DICT)
# Get ROI part from the detection
n_boxes = len(d['level'])
# For each detected part
for i in range(1, 2):
# Get the localized region
(x, y, w, h) = (d['left'][i], d['top'][i], d['width'][i], d['height'][i])
# Draw rectangle to the detected region
cv2.rectangle(img, (x, y), (x + w, y + h), (0, 0, 255), 5)
# Crop the image
crp = gry[y:y + h, x:x + w]
# OCR
txt = pytesseract.image_to_string(crp, config="--psm 6")
print(txt)
# Display the cropped image
cv2.imshow("crp", crp)
cv2.waitKey(0)
# Display
cv2.imshow("img", img)
cv2.waitKey(0)
-
我为iOS写了一个数字OCR。我有一个测试图像png与两位数5和4。我找到轮廓了。我如何在Tesseract转乘等高线? 初始化tesseract: 用于检测轮廓的函数: GitHub项目链接:https://github.com/maxpatsy/iorc
-
我已经成功地将镶嵌到我的Android应用程序中,它可以读取我捕获的任何图像,但准确性非常低。但大多数时候,我在捕获后没有得到正确的文本,因为感兴趣区域周围的一些文本也会被捕获。 我想阅读的只是来自矩形区域的所有文本,准确,没有捕捉矩形的边缘。我已经做了一些研究,并在stackoverflow上发布了两次,但仍然没有得到满意的结果! 以下是我发的2个帖子: https://stackoverflo
-
我正试图根据本手册构建一个< code>Tesseract库:使用git-bash(版本 无论我做什么以及它如何失败,原因都是一样的-当涉及到<code>轻量级</code>时,我看到的错误如下: 找不到由“SW”提供的具有以下任何名称的软件包配置文件: SWConfig.cmake sw-config.cmake 我已经将放在PATH指示的位置,但它没有帮助 - 错误仍然存在。存储库中是否可能缺
-
我试图开发一个应用程序,使用Tesseract从手机摄像头拍摄的文件中识别文本。为了更好的识别,我使用OpenCV对图像进行预处理,使用高斯模糊和阈值方法进行二值化,但结果很糟糕。 我可以使用哪些其他过滤器来使图像对Tesseract更具可读性?
-
hotwords|热门关键词: 标签名称:hotwords 功能说明:获取网站搜索的热门关键字 适用范围:全局使用 基本语法: {dede:hotwords /} 参数说明: num='6' 关键词数目 subday='365' 天数 maxlength='16' 关键词最大长度
-
我有一个在docker容器中运行的spring-boot应用程序,其中安装了tesseract。 在Java程序中,我使用opencv预处理图像,如下所示 但是运行 给出错误: 图像太大: (1, 146327) 知道我哪里做错了吗?奇怪的是文件大小只有146kb,所以我不知道为什么宇宙魔方认为它太大了? 此外,如果我删除adaptiveThreshold步骤并直接在mat上执行<code>ime