
树遍历-运行时后将节点附加到相邻矩阵

我正在构建一个树遍历程序,允许用户运行BFS和DFS遍历,以及添加和删除节点。
由于扩展邻接矩阵的问题,我坚持的是添加节点。对于此示例,我想将一个新的子节点 X 添加到父节点 H:
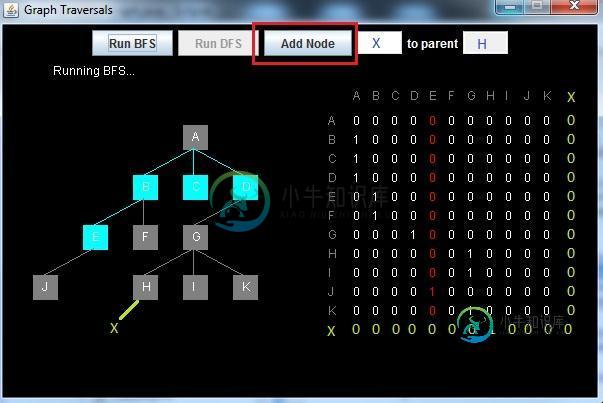
现在,我已经对节点< code>X进行了硬编码,但是以后将允许自定义输入。
用户点击添加节点按钮:
//try and create and connect node via button
AddButton.addActionListener(new ActionListener() {
public void actionPerformed(ActionEvent e)
{
Nodes nX = new Nodes("X", nodeX, nodeY, nodeWidth, nodeHeight);
appendNode(rootNode, nX);
}
});
该函数调用appendNode():该函数应该创建一个具有更新大小的新邻接矩阵(给定额外的节点X)……从旧矩阵中复制数据adjMatrix,然后为新节点添加一个额外的插槽
public void appendNode(Nodes parent, Nodes child) {
//add new node X to nodeList
addNode(child);
//loop through all nodes again to be connected, plus new one... then create new adjMatrix
int newSize = nodeList.size();
//make a new adj matrix of the new size...
int[][] adjMatrixCopy = new int[newSize][newSize];
int fromNode = nodeList.indexOf(parent);
int toNode = nodeList.indexOf(child);
//copy adjMatrix data to new matrix...
for (int i = 0; i < adjMatrix.length; i++) {
for (int j = 0; j < adjMatrix[i].length; j++) {
adjMatrixCopy[i][j] = adjMatrix[i][j];
}
}
for (int col = 0; col < newSize; col++) {
adjMatrixCopy[newSize][col] = 1;
}
// still need to add newly added node
// adjMatrixCopy[fromNode][toNode] = 1;
// adjMatrixCopy[toNode][fromNode] = 0;
// adjMatrix = null;
}
当我单击<code>appendNode</code>时,它会抛出以下错误:
Exception in thread "AWT-EventQueue-0" java.lang.ArrayIndexOutOfBoundsException: 12
at Graph.appendNode(Graph.java:306)
at Graph$3.actionPerformed(Graph.java:141)
共有1个答案

adjMatrixCopy[newSize][col] = 1;
这是错误的。也许你想要
adjMatrixCopy[newSize - 1][col] = 1;
取而代之?
-
这是一个相当简单的问题,我注意到当我表示一棵树时,无论我用哪种方式(后排序,按顺序,前排序)树叶总是以相同的顺序出现,从左到右。 我只是想知道为什么,这是有原因的吗? 我刚开始研究它们,就想到了这个。 编辑: 我有一棵这样的树: 叶节点为:D、E和F 预购顺序为:A、B、D、C、E、F 顺序是:D,B,A,E,C,F 后序是:D,B,E,F,C,A 叶子节点总是从左到右出现,不管我选择哪个顺序,问
-
在具有父子指针的通用树结构中,是否可以在不遍历完整树的情况下遍历叶节点?例如,从最左边的叶节点开始。想法是在深树上进行优化。
-
主要内容:src/runoob/graph/DenseGraphIterater.java 文件代码:,src/runoob/graph/SparseGraphIterater.java 文件代码:图论中最常见的操作就是遍历邻边,通过一个顶点遍历相关的邻边。邻接矩阵的遍历邻边的时间复杂度为 O(V),邻接表可以直接找到,效率更高。 邻接矩阵迭代: ... public Iterable <Integer > adj ( int v ) { assert v >= 0 && v < n ;
-
我在编码挑战中遇到了一个问题。 完整二叉树是一种二叉树,其中除叶节点外的每个节点都有两个子节点,且树的最后一级边高度有叶节点。 您的任务很简单,给定完整二叉树的遍历,请按顺序遍历打印其
-
我正在尝试编写一个函数,该函数将使用级别顺序遍历将一个元素插入到二叉树中。我的代码遇到的问题是,当我在树中插入一个新节点后打印级别顺序遍历时,它以无限循环的方式打印元素。1,2,3,4,5,6,7,8这个数字一直在飞驰过终点站。我将感谢任何关于如何补救这种情况的指示和建议。 这是我通过修改级别顺序遍历技术将一个元素插入到树中的地方 主
-
我有一个通用的树结构。我需要一个算法来遍历它,并删除一些不包含在给定列表中的叶子。如果所有的叶子都从子树中删除,那么也删除整个子树。 示例树: 要保留的叶子:{4,6} 结果树: 输入数据结构包含在 HashMap 中,其中键是节点的父 ID,值是父节点正下方的节点列表(但不是递归所有子节点)。根节点的父 ID 为空字符串。 我想,某种递归DFS遍历算法应该可以工作,但我不知道它是如何工作的。