
列出列值在数据帧中不唯一的行 [重复]

我有一个数据帧,其中重复了一些 SongId。我想提取那些重复的行。知道怎么做吗?试:
dfB[dfB.SongId.duplicated()]
但是效果不好。
这是我的数据帧的一个示例。在此示例中重复 SongId 0、10 和 16:
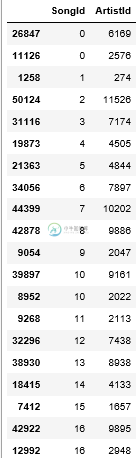
共有1个答案

试试这个,
df=pd.DataFrame({"Song ID":[0,0,1,3,1,4,5],'ArtistID':[12,13,34,1,21,43,22]})
print df[df.duplicated(subset=['Song ID'],keep=False)]
输出:
Song ID value
0 0 12
1 0 13
2 1 34
4 1 21
-
本文向大家介绍如何在R数据帧的列中查找唯一值?,包括了如何在R数据帧的列中查找唯一值?的使用技巧和注意事项,需要的朋友参考一下 分类变量具有多个类别,但是如果数据集很大且类别也很大,那么识别它们就会有些困难。因此,我们可以为分类变量提取唯一值,这将有助于我们轻松识别分类变量的类别。我们可以通过对R数据帧的每一列使用唯一的方法来做到这一点。 示例 请看以下数据帧- 在列x1中找到唯一值- 在列x2中
-
我有以下数据框: 我想将其转换为: i、 e.我希望保留前4列,但将剩余的每列值分配到单独的行中。有没有一种不使用for循环的方法来实现这一点?
-
问题内容: 我有一个: 我可以过滤库存编号‘600809’如下的行: 我想将一些股票的所有行汇总在一起,例如[‘600809’,‘600141’,‘600329’]。这意味着我想要这样的语法: 由于大熊猫不接受上述命令,如何实现目标? 问题答案: 使用isin方法。 。
-
我试图做的是从列“in_reply_to_user_id”(不在图片中,因为df太宽,无法容纳)与给定id具有相同值的行中获取文本,并将文本附加到列表中,然后将其放入新列中。例如,所有tweet中的“in_reply_to_user_id”列等于第一条tweet的“id”的文本都应该放在一个列表中,然后添加到数据框中名为“reples”的新列中。以下是我尝试过的一些事情:
-
有一个数据帧: 以及熊猫系列: 如何创建包含c1在list1中的行的新数据帧。 输出:
-
当我尝试重命名和删除列从熊猫data.frame我遇到一个错误说