
Python Selenium为使用文档打开的windows截图并另存为PDF。写()

我正在使用Selenium和Python(在Jupyter笔记本中)。我打开了许多选项卡,比如说5个选项卡(所有元素都已加载完毕),我想在它们之间循环并做两件事:
- 截图,
- (作为奖励)使用Chrome内置的另存为PDF功能,使用A4横向、正常缩放和指定的默认目录将每个打印到PDF,无需用户交互。
(在下面的代码中,我主要关注屏幕截图要求,但也非常想知道如何将其保存为PDF)
此代码允许在选项卡之间循环:
numTabs = len(driver.window_handles)
for x in range(numTabs):
driver.switch_to.window(driver.window_handles[x])
time.sleep(0.5)
但是,如果我尝试添加驱动程序。save_screenshot()调用如下所示,代码在拍摄第一个屏幕截图后似乎会停止。具体来说,"0"。为第一个选项卡(索引为0)创建“png”,并切换到下一个选项卡(索引为1),但停止进一步处理。它甚至不循环到下一个选项卡。
numTabs = len(driver.window_handles)
for x in range(numTabs):
driver.switch_to.window(driver.window_handles[x])
driver.save_screenshot(str(x) + '.png') #screenshot call
time.sleep(0.5)
编辑1:我修改了如下所示的代码,开始从窗口句柄[1]而不是[0]截图,因为我并不需要[0]中的截图,但现在甚至没有生成一个截图。因此,save\u screenshot()调用似乎在最初的切换到之后都不起作用。window()调用。
tabs = driver.window_handles
for t in range(1, len(tabs)):
print("Processing tab " + tabs[t])
driver.switch_to.window(tabs[t])
driver.save_screenshot(str(t) + '.png') #screenshot call, but the code hangs. No screenshot taking, no further cycling through tabs.
编辑2:我已经发现了为什么我的代码是“悬挂”的,不管我使用哪种打印到PDF或截屏的方法。我之前提到过,新选项卡是通过点击主页上的按钮打开的,但是经过仔细检查,我现在看到新选项卡的内容是使用文档生成的。写()。有一些ajax代码检索waybillHTML内容,然后使用document.write(waybillHTML)写入新窗口
这是一个订单系统,主页上有一个订单列表,每个订单旁边有一个按钮,打开一个带有运单的新选项卡。重要的是,运单实际上是使用文档生成的。write()由按钮单击触发。我注意到,右键单击新选项卡时,“查看页面源”选项变灰。当我使用时,切换到。window()要切换到这些选项卡之一,请单击页面。printToPDF在300秒后超时(我想是这样)。
---------------------------------------------------------------------------
TimeoutException Traceback (most recent call last)
<ipython-input-5-d2f601d387b4> in <module>
14 driver.switch_to.window(handles[x])
15 time.sleep(2)
---> 16 data = driver.execute_cdp_cmd("Page.printToPDF", printParams)
17 with open(str(x) + '.pdf', 'wb') as file:
18 file.write(base64.b64decode(data['data']))
...
TimeoutException: Message: timeout: Timed out receiving a message from renderer: 300.000
(Session info: headless chrome=96.0.4664.110)
所以我精炼的问题应该是如何使用Page.printToPDF在新窗口中打印页面(用文档动态生成的)。写())而不超时?
我尝试的一种方法是:
from selenium.html" target="_blank">webdriver.common.desired_capabilities import DesiredCapabilities
caps = DesiredCapabilities().CHROME
caps["pageLoadStrategy"] = "none"
driver = webdriver.Chrome(options=chrome_options, desired_capabilities=caps)
指的是:这个问题
但问题是这太“激进”,阻止代码登录到订购系统并进行导航
Edit3:在这一点上,我尝试了一些简单的方法,比如获取页面源代码
try:
pageSrc = driver.find_element(By.XPATH, "//*").get_attribute("outerHTML")
print(pageSrc)
动态生成的选项卡(在他们完成渲染很久之后,我可以在屏幕上看到内容(在调试的这个阶段不使用无头)),甚至这本身就是抛出一个TimeoutExcure,所以我不认为这是一个等待内容的问题加载。不知何故,驱动程序无法看到内容。这些页面的生成方式可能有些奇怪——我不知道。答案中建议的截图和保存PDF的所有方法都很好,我相信对于其他正常的窗口来说。Chrome视图页面源代码仍然是灰色的,但是我可以使用检查看到常规的超文本标记语言内容。
Edit4:使用Chrome的检查功能,动态生成页面的页面源具有以下HTML结构:
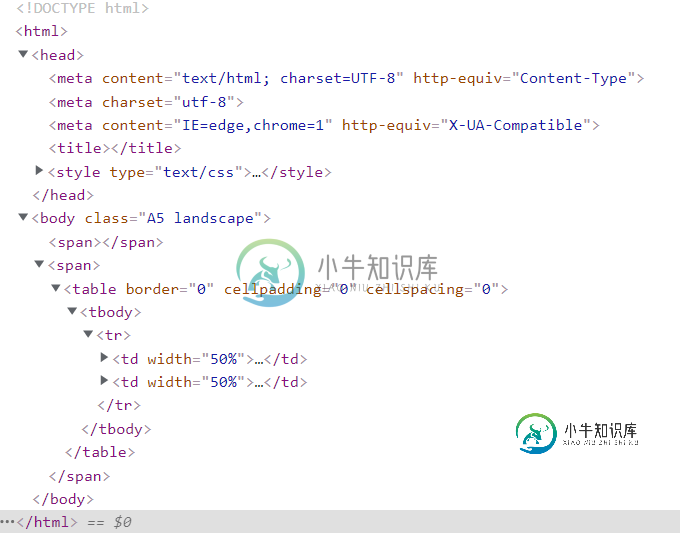
共有3个答案

更新2
基于最近的Edit 3,我现在通过AJAX调用检索新窗口来获取它的源。驱动程序获取的主页是:
测验html
<!doctype html>
<html>
<head>
<meta name=viewport content="width=device-width,initial-scale=1">
<meta charset="utf-8">
<script src="https://cdnjs.cloudflare.com/ajax/libs/jquery/1.12.4/jquery.min.js"></script>
<script>
function makeRequest() {
var req = jQuery.ajax({
'method': 'GET',
'url': 'http://localhost/Booboo/test/testa.html'
});
req.done(function(html) {
let w = window.open('', '_blank');
w.document.write(html);
w.document.close();
});
}
</script>
<body>
</body>
<script>
$(function() {
makeRequest();
});
</script>
</html>
testa.html,它正在检索的文档是新窗口的源:
种皮。html
<!doctype html>
<html>
<head>
<meta name=viewport content="width=device-width,initial-scale=1">
<meta charset="utf-8">
</head>
<body>
<h1>It works!</h1>
</body>
</html>
最后,Selenium程序test.html并进入循环,直到它检测到现在有两个窗口。然后,它检索第二个窗口的源,并像之前一样使用Pillow和Image2Pdf获取快照。
from selenium import webdriver
import time
def save_snapshot_as_PDF(filepath):
"""
Take a snapshot of the current window and save it as filepath.
"""
from PIL import Image
import image2pdf
from tempfile import mkstemp
import os
if not filepath.lower().endswith('.pdf'):
raise ValueError(f'Invalid or missing filetype for the filepath argument: {filepath}')
# Get a temporary file for the png
(fd, file_name) = mkstemp(suffix='.png')
os.close(fd)
driver.save_screenshot(file_name)
img = Image.open(file_name)
# Remove alpha channel, which image2pdf cannot handle:
background = Image.new('RGB', img.size, (255, 255, 255))
background.paste(img, mask=img.split()[3])
background.save(file_name, img.format)
# Now convert it to a PDF:
with open(filepath, 'wb') as f:
f.write(image2pdf.convert([file_name]))
os.unlink(file_name) # delete temporary file
options = webdriver.ChromeOptions()
options.add_argument("headless")
options.add_experimental_option('excludeSwitches', ['enable-logging'])
driver = webdriver.Chrome(options=options)
try:
driver.get('http://localhost/Booboo/test/test.html')
trials = 10
while trials > 10 and len(driver.window_handles) < 2:
time.sleep(.1)
trials -= 1
if len(driver.window_handles) < 2:
raise Exception("Couldn't open new window.")
driver.switch_to.window(driver.window_handles[1])
print(driver.page_source)
save_snapshot_as_PDF('test.pdf')
finally:
driver.quit()
印刷品:
<html><head>
<meta name="viewport" content="width=device-width,initial-scale=1">
<meta charset="utf-8">
</head>
<body>
<h1>It works!</h1>
</body></html>

由于您的用例是使用Chrome内置的“另存为PDF”功能将每个链接打印为PDF,或拍摄屏幕截图,而不是同时打开所有附加链接,因此您可能希望逐个打开“相邻”选项卡中的链接,并使用以下定位策略拍摄屏幕截图:
>
num_tabs_to_open = len(elements_href)
windows_before = driver.current_window_handle
# open the links in the adjascent tab one by one to take screenshot
for href in elements_href:
i = 0
driver.execute_script("window.open('" + href +"');")
windows_after = driver.window_handles
new_window = [x for x in windows_after if x != windows_before][0]
driver.switch_to.window(new_window)
driver.save_screenshot(f"image_{str(i)}.png")
driver.close()
driver.switch_to.window(windows_before)
i = i+1
您可以在以下网站找到相关的详细讨论:
- InvalidSessionIdeException:消息:使用Selenium和Python在循环中截图的会话id无效

我对你的这些问题有点困惑:
截屏,,
(作为奖励)使用Chrome内置的使用A4横向、正常缩放和指定的默认目录将每个打印到PDF,无需用户交互。
函数save_screenshot将图像文件保存到文件系统中。要将此图像文件转换为PDF,您必须打开它并将其写入PDF文件。
这项任务很简单,可以使用各种Python PDF模块。我有这方面的代码,所以让我知道如果你需要它,我会把它添加到下面的代码。
关于将选项卡中的网页打印为PDF,您可以使用execute\u cdp\u cmd和页面。printToPDF。通过单击按钮,可以修改下面的代码以支持未知URL方案。如果你需要帮助,请告诉我。
import base64
import traceback
from time import sleep
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.common.exceptions import TimeoutException
chrome_options = Options()
chrome_options.add_argument("--start-maximized")
chrome_options.add_argument("--disable-infobars")
chrome_options.add_argument("--disable-extensions")
chrome_options.add_argument("--disable-popup-blocking")
# headless mode is required for this method of printing
chrome_options.add_argument("--headless")
# disable the banner "Chrome is being controlled by automated test software"
chrome_options.add_experimental_option("useAutomationExtension", False)
chrome_options.add_experimental_option("excludeSwitches", ['enable-automation'])
driver = webdriver.Chrome('/usr/local/bin/chromedriver', options=chrome_options)
# replace this code with your button code
###
driver.get('https://abcnews.go.com')
urls = ['https://www.bbc.com/news', 'https://www.cbsnews.com/', 'https://www.cnn.com', 'https://www.newsweek.com']
for url in urls:
driver.execute_script(f"window.open('{url}','_blank')")
# I'm using a sleep statement, which can be replaced with
# driver.implicitly_wait(x_seconds) or even a
# driver.set_page_load_timeout(x_seconds) statement
sleep(5)
###
# A4 print parameters
params = {'landscape': False,
'paperWidth': 8.27,
'paperHeight': 11.69}
# get the open window handles, which in this care is 5
handles = driver.window_handles
size = len(handles)
# loop through the handles
for x in range(size):
try:
driver.switch_to.window(handles[x])
# adjust the sleep statement as needed
# you can also replace the sleep with
# driver.implicitly_wait(x_seconds)
sleep(2)
data = driver.execute_cdp_cmd("Page.printToPDF", params)
with open(f'file_name_{x}.pdf', 'wb') as file:
file.write(base64.b64decode(data['data']))
# adjust the sleep statement as needed
sleep(3)
except TimeoutException as error:
print('something went wrong')
print(''.join(traceback.format_tb(error.__traceback__)))
driver.close()
driver.quit()
以下是我以前的一个答案,可能会很有用:
- Selenium打印A4格式的PDF
-
我目前的工作是创建机械图纸,用于发送给客户和作为施工图。当我的绘图完成后,我导出一个. pdf文件,并将其发送给客户端。 我们的客户非常喜欢黑白画,所以我试着提供他们。但是我用来画画的软件效果不好。它只有一个选项“所有颜色都是黑色”,我的画上有一些白色的“隐藏线”。当然,这些显示使用所有颜色作为黑色选项。 我找到了一个解决方案,那就是使用pdf打印机。效果很好,效果也很好。 现在我想打印这个。pd
-
问题内容: 我有一个生成PDF的动作类。该适当地设定。 我 通过Ajax调用来称呼它。我不知道将流传输到浏览器的方法。我尝试了几件事,但没有任何效果。 上面给出了错误: 您的浏览器发送了该服务器无法理解的请求。 问题答案: 您不必为此使用Ajax。只是一个环节是不够的,如果你设置到服务器端代码。这样,如果您最关心的是父页面将保持打开状态(为什么您会为此而不必要地选择Ajax?)。此外,没有办法很好
-
问题内容: 我做了一个按钮来截取屏幕截图并保存到Pictures文件夹中。我将其设置为以capture.jpeg的名称保存,但我希望将其保存为cafe001.jpeg,caf002.jpeg这样。还请您告诉我如何将其保存为time format.jpeg吗?提前谢谢你的帮助 问题答案: 您基本上有两种选择… 你可以… 列出目录中的所有文件,然后简单地将文件计数增加1并使用… 当然,如果存在具有相同
-
我做了一个按钮,以采取截图和保存到图片文件夹。我将它设置为保存在名称capture.jpeg下,但我希望它保存为像这样的cafe001.jpeg,cafe002.jpeg。你能告诉我如何将它保存为时间格式.jpeg吗?谢谢你事先的帮助
-
本文向大家介绍Android 下载并打开PDF,Doc,Dwg文档实例,包括了Android 下载并打开PDF,Doc,Dwg文档实例的使用技巧和注意事项,需要的朋友参考一下 今天项目中遇到这样一个需求 ,根据后台接口里pdf,doc,dwg文档的地址 是一个URL ,需要根据文档的url 下载到本地(内部存储或内存卡)并用手机中能打开该文档的软件弹出来并打开,(这里需要做一个缓存,第一次查看这个
-
问题内容: 我有一个生成PDF的动作类。该适当地设定。 我action 通过Ajax调用来称呼它。我不知道将流传输到浏览器的方法。我尝试了几件事,但没有任何效果。 上面给出了错误: 问题答案: 你不必为此使用Ajax。只是一个环节是不够的,如果你设置到服务器端代码。这样,如果你最关心的是父页面将保持打开状态(为什么你会为此而不必要地选择Ajax?)。此外,没有办法很好地同步处理这个问题。PDF不是