
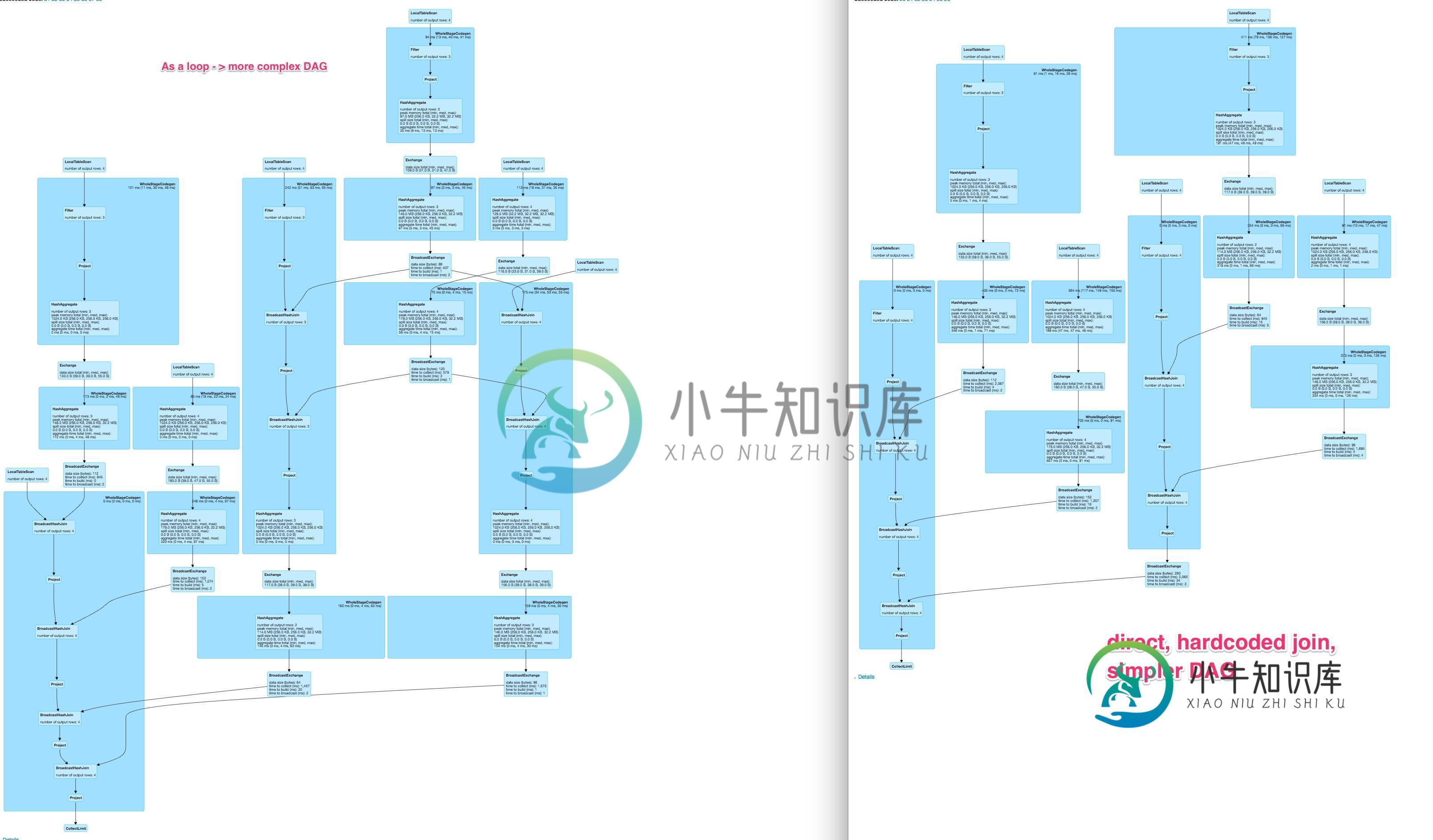
Spark dynamic DAG比硬编码DAG慢得多,而且不同于硬编码DAG

我在spark中有一个操作,应该对数据帧中的几列执行。通常,有两种可能来指定这样的操作
- hardcode
handleBias("bar", df)
.join(handleBias("baz", df), df.columns)
.drop(columnsToDrop: _*).show
- 从colnames列表动态生成它们
var isFirst = true
var res = df
for (col <- columnsToDrop ++ columnsToCode) {
if (isFirst) {
res = handleBias(col, res)
isFirst = false
} else {
res = handleBias(col, res)
}
}
res.drop(columnsToDrop: _*).show

def handleBias(col: String, df: DataFrame, target: String = "FOO"): DataFrame = {
val pre1_1 = df
.filter(df(target) === 1)
.groupBy(col, target)
.agg((count("*") / df.filter(df(target) === 1).count).alias("pre_" + col))
.drop(target)
val pre2_1 = df
.groupBy(col)
.agg(mean(target).alias("pre2_" + col))
df
.join(pre1_1, Seq(col), "left")
.join(pre2_1, Seq(col), "left")
.na.fill(0)
}

共有1个答案

编辑1:从handleBias中删除一个窗口函数,并将其转换为广播连接。
编辑2:更改了空值的替换策略。
我有一些建议可以改进您的代码。首先,对于“handlebias”函数,我将使用窗口函数和“WithColumn”调用来完成,避免联接:
import org.apache.spark.sql.DataFrame
import org.apache.spark.sql.functions._
import org.apache.spark.sql.expressions.Window
def handleBias(df: DataFrame, colName: String, target: String = "foo") = {
val w1 = Window.partitionBy(colName)
val w2 = Window.partitionBy(colName, target)
val result = df
.withColumn("cnt_group", count("*").over(w2))
.withColumn("pre2_" + colName, mean(target).over(w1))
.withColumn("pre_" + colName, coalesce(min(col("cnt_group") / col("cnt_foo_eq_1")).over(w1), lit(0D)))
.drop("cnt_group")
result
}
val df = Seq((1, "first", "A"), (1, "second", "A"),(2, "noValidFormat", "B"),(1, "lastAssumingSameDate", "C")).toDF("foo", "bar", "baz")
val columnsToDrop = Seq("baz")
val columnsToCode = Seq("bar", "baz")
val target = "foo"
val targetCounts = df.filter(df(target) === 1).groupBy(target)
.agg(count(target).as("cnt_foo_eq_1"))
val newDF = df.join(broadcast(targetCounts), Seq(target), "left")
val result = (columnsToDrop ++ columnsToCode).toSet.foldLeft(df) {
(currentDF, colName) => handleBias(currentDF, colName)
}
result.drop(columnsToDrop:_*).show()
+---+--------------------+------------------+--------+------------------+--------+
|foo| bar| pre_baz|pre2_baz| pre_bar|pre2_bar|
+---+--------------------+------------------+--------+------------------+--------+
| 2| noValidFormat| 0.0| 2.0| 0.0| 2.0|
| 1|lastAssumingSameDate|0.3333333333333333| 1.0|0.3333333333333333| 1.0|
| 1| second|0.6666666666666666| 1.0|0.3333333333333333| 1.0|
| 1| first|0.6666666666666666| 1.0|0.3333333333333333| 1.0|
+---+--------------------+------------------+--------+------------------+--------+
-
null
-
原则上,我的应用程序不知道屏幕的纵横比(Android应用程序也应该如此)。现在,推荐的做法是手动添加 进入清单,因为智能手机屏幕的宽高比高于默认支持的1.86的趋势。我的问题是,与其设置一个硬编码的比率(如2.1),有没有更好的方法告诉Android,我不在乎最大宽高比是多少? 如果否,是否可以设置任意高的值,例如3.1甚至5.1?这样做安全吗?我说的不是奇怪的屏幕尺寸,而是未来的主流屏幕和未来
-
目前,我们正在使用Checkmarx扫描应用程序代码。不确定Checkmarx是否检测/扫描源代码中的任何硬编码密码。是否需要在Checkmarx服务器上添加任何额外的配置来检测密码?
-
问题内容: 我已经记录了一个上传excel的场景,在下一个后续请求中,excel中的那些记录将作为参数传递。 但是假设我需要更改excel,该请求将如何采用新值? 由于大量的值,参数化似乎不是答案。 请帮助。 问题答案: 如果需要从Excel文件中提取一些值并将其添加为HTTP请求参数,则可以使用以下方法。 下载Apache Tika二进制文件(tika-app-*。jar),并将其拖放到JMet
-
问题内容: 这两个功能都可以使用,但是我正在使用这是一个不好的做法,因为某些下拉列表和文本字段将比其他字段需要更长的时间来填充,因此我必须使用最长的睡眠值才能避免错误,如何解决这些问题2个功能使用等待。 问题答案: 当你正在调用的 WebElement 项目 ,理想情况下,你应该调用 WebDriverWait 与 EC 的,所以你必须: 更换: 与: 作为下拉需要更长的时间来填补,所以你应该调用
-
问题内容: 问: 在SQL脚本或存储过程中,避免幻数或硬编码值还有哪些其他策略? 考虑一个存储过程,该存储过程的工作是根据其或某些其他FK查找表或值的范围来检查/更新记录的值。 考虑一个表,其中ID最重要,因为它是另一个表的FK: 应避免的SQL脚本 如下所示 : 这里的问题是,这不是可移植的,并且显式依赖于硬编码的值。在将其部署到另一个没有标识插入的环境时,存在细微的缺陷。 还尝试避免基于文本的
-
我试着在谷歌上搜索,找了一段时间,但没有找到任何解释如何做好这件事的地方 变量是firstname、lastname、social security number和weekly salary。