
利用置换矩阵进行稀疏矩阵的Cholesky分解

我对大型稀疏矩阵的Cholesky分解感兴趣。我遇到的问题是,Cholesky因子不一定是稀疏的(就像两个稀疏矩阵的乘积不一定是稀疏的)。
例如,对于仅沿第一行,第一列和对角线具有非零的矩阵,Cholesky因子具有100%的填充(下三角形和上三角形是100%的密度)。在下面的图像中,灰色为非零,而白色为零。

我知道的一个解决方案是,找到一个置换P矩阵,然后对psupt/supap进行Cholesky分解。例如,对于相同的矩阵,通过应用将第一行移动到最后一行,将第一列移动到最后一列的置换矩阵,Cholesky因子是稀疏的。

我的问题是一般如何确定P?
要从一个更真实的矩阵中了解A和PSUPT/SUPAP的Cholesky分解的区别,请看下面的图像。我从http://www.seas.ucla.edu/vandenbe/103/lectures/chol.pdf上获取了所有这些图像
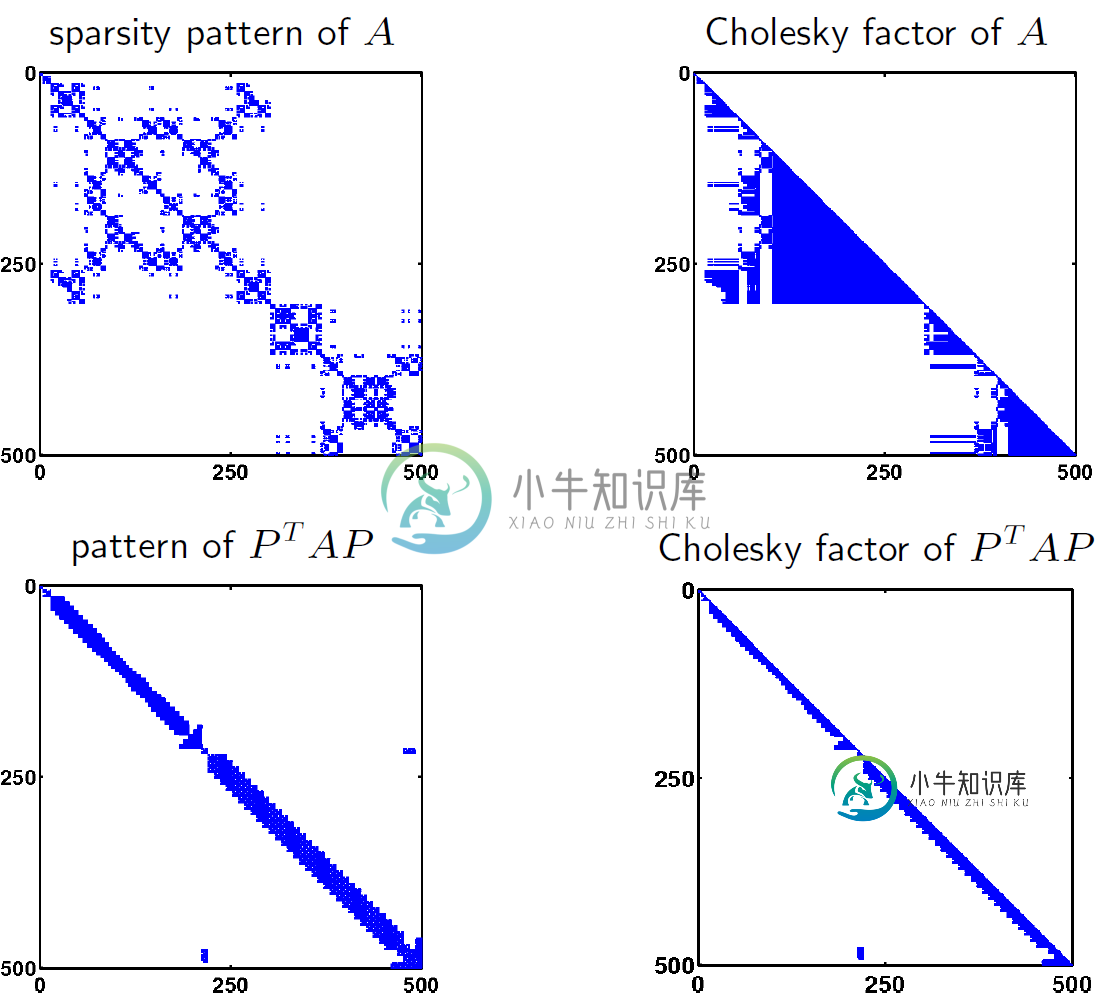
根据课堂讲稿
有许多启发式方法(我们没有讨论)来选择好的置换矩阵P。
我想知道其中的一些方法是什么(用C,C++,甚至Java编写的代码会是理想的)。
共有1个答案

求矩阵的行和列的最佳排列以求最小填充矩阵因子分解的问题并不是一个简单的问题(如评注中所指出的)。因此,启发式算法在实际应用中得到了应用。
有一些库实现启发式重编号/排序策略,通常基于矩阵邻接图的图算法。一个是尽量减少相应邻接矩阵的带宽。一种易于实现的算法是Cuthill-McKee算法或最小度排序算法。关于这个问题的更多信息可以在Yousef Saad:Iterative Methods for Sparse Linear Systems(2003)一书中找到。
许多库实现了启发式算法,例如
其中一些库还提供了稀疏的Cholesky分解方法,可以直接使用。
-
我正在实现一个稀疏矩阵类,使用映射向量来存储数据(映射表示矩阵的一行,其中键是列的索引,值是该位置的maitrix的值)我已经编写了计算行列式的函数,但我不知道是否有一种方法可以计算这种节省的时间(因为矩阵是稀疏的,大多数值为零)在这里我的实现: 这是类接口 我计算行列式的方式是什么?假设运算符()以这种方式重载 提前感谢您的帮助
-
稀疏矩阵(Sparse Matrix) 注:压缩存储的矩阵可以分为特殊矩阵和稀疏矩阵。对于那些具有相同元素或零元素在矩阵中分布具有一定规律的矩阵,被称之为特殊矩阵。对于那些零元素数据远远多于非零元素数目,并且非零元素的分布没有规律的矩阵称之为稀疏矩阵。 1. 稀疏矩阵的概念 在矩阵中,若数值为0的元素数目远远多于非0元素的数目时,则称该矩阵为稀疏矩阵。与之相反,若非0元素数目占大多数时,则称该矩阵
-
2.5.1 介绍 (密集) 矩阵是: 数据对象 存储二维值数组的数据结构 重要特征: 一次分配所有项目的内存 通常是一个连续组块,想一想Numpy数组 快速访问个项目(*) 2.5.1.1 为什么有稀疏矩阵? 内存,增长是n**2 小例子(双精度矩阵): In [2]: import numpy as np import matplotlib.pyplot as plt x = np.li
-
如何将稀疏矩阵划分为最少数量的连接组件,这样每个组件在整个组件中都有一个公共行或列。我应该使用什么数据结构来在最短的时间内完成这个任务。我认为要做到这一点,我必须最大化每个组件中的元素数量,所以在输入时,我在每行和每列中存储了元素数量。我对列表进行排序,然后用max(min(行中的元素,列中的元素))进行行或列排序,即, 对于矩阵: 然后我将首先删除第1列,然后我将不得不更新剩余的数组,这将占用大
-
在课堂上,我必须为稀疏矩阵编写自己的线性方程求解器。我可以自由地使用任何类型的数据结构为稀疏矩阵,我必须实现几个解决方案,包括共轭梯度。 谢了!
-
在使用numpy的python中,假设我有两个矩阵: 稀疏矩阵 密集的x*y矩阵 现在我想做,它将返回一个密集的矩阵。 但是,我只关心中非零的单元格,这意味着如果我这样做了,对我的应用程序不会有任何影响 <代码>S\u=S*S\u 显然,这将是对操作的浪费,因为我想把在
-
我正在计算两大组向量(具有相同特征)之间的余弦相似度。每组向量表示为一个scipy CSR稀疏矩阵a和B。我想计算一个x B^T,它不会稀疏。但是,我只需要跟踪超过某个阈值的值,例如0.8。我正试图用vanilla RDD在Pyspark中实现这一点,目的是使用为scipy CSR矩阵实现的快速向量操作。 A和B的行是标准化的,所以为了计算余弦相似度,我只需要找到A中每一行与B中每一行的点积。A的
-
问题内容: 我有一个Sqlite数据库,其中包含以下类型的架构: 该表包含术语及其在文档中的各自计数。喜欢 该矩阵可以被视为稀疏矩阵,因为每个文档都包含很少的具有非零值的项。 我将如何使用numpy从稀疏矩阵创建密集矩阵,因为我必须使用余弦相似度来计算文档之间的相似度。 这个密集的矩阵看起来像一个表格,第一列为docid,所有术语列为第一行,其余单元格将包含计数。 问题答案: 我用熊猫解决了这个问