-
主查询和子查询是什么关系?
在一个 select 语句中,嵌入了另外一个 select 语句, 那么被嵌入的 select 语句称之为子查询语句,外部那个select语句则称为主查询。 主查询和子查询的关系: 1.子查询是嵌入到主查询中。 2.子查询是辅助主查询的,要么充当条件,要么充当数据源。 3.子查询是可以独立存在的语句,是一条完整的 select 语句。 子查询的使用 子查询是一个完整的SQL语句,子查询被嵌入到一对
-
Python中NumPy和SciPy有什么区别?
NumPy是一个定义了数值数组和矩阵类型和它们的基本运算的语言扩展。 SciPy是另一种使用NumPy来做高等数学、信号处理、优化、统计和许多其它科学任务的语言扩展。 NumPy,代表 Numerical Python,用于操作数值数组数据的元素。SciPy,代表 Scientific Python,用于 Python 中的数值计算。这两个包都提供了使用 Python 的扩展功能。让我们了解 NumPy 和 SciPy 之间的一些基本区别
-
常见的数据库管理系统哪些?
在电脑上安装了数据库管理系统后,就可以通过数据库管理系统创建数据库来存储数据,也可以通过该系统对数据库中的数 据进行数据的增删改查相关的操作。MySQL是一款开源免费的中小型数据库。我们平时说的MySQL数据库就是是MySQL数据库管理系统。 通过上面的描述,大家应该已经知道了 数据库管理系统 和 数据库 的关系。那么有哪些常见的数据库管理系统呢? 接下来对上面列举的数据库管理系统进行简单的介绍:
-
VMware是什么?VMware虚拟机最新安装教程
VMware(威睿) 是全球桌面到数据中心虚拟化解决方案的领导厂商。全球不同规模的客户依靠VMware来降低成本和运营费用、确保业务持续性、加强安全性并走向绿色。VMware使企业可以采用能够解决其独有业务难题的云计算模式。 VMware Workstation是一款虚拟机软件,允许用户将Linux、Windows等多个操作系统作为虚拟机在单台PC上运行。
-
MapReduce是什么?有哪些特征和优点?
MapReduce是什么 Hadoop MapReduce是一个分布式计算框架,用于轻松编写分布式应用程序,这些应用程序以可靠,容错的方式并行处理大型硬件集群(数千个节点)上的大量数据(多TB数据集)。 MapReduce是一种面向海量数据处理的一种指导思想,也是一种用于对大规模数据进行分布式计算的编程模型。 发展历程 MapReduce最早由Google于2004年在一篇名为《MapReduce
-
Python解释器的种类以及相关特点?
python的解释器是什么? Python的解释器是一种可以执行Python代码的软件程序。Python官方提供了多个解释器,包括CPython、Jython、IronPython、PyPy等。其中,CPython是最常用的一个,也是官方默认的解释器。 Python解释器有多种不同的实现,以下是其中一些常见的解释器及其特点。
-
什么是操作系统?操作系统分类
对于什么是操作系统可能很多人都没认真考虑过,甚至可能都不知道自己其实用过很多种类的操作系统。今天我们就介绍介绍关于操作系统的基本知识。 首先我们先介绍一下具体什么是操作系统。 什么是操作系统 为了理解什么是操作系统,我们将Linux操作系统的整体架构示意图展示在这里。从图中可以看出,操作系统位于硬件之上,而处于应用程序之下。所以操作系统是介于应用软件与硬件之间的一个软件系统。
-
如何对MySQL的limit分页查询进行优化?
针对分页这个问题,了解其为什么慢就知道优化方法了,因为,当在进行分页查询时,如果执行limit 9000000,10,此时需要MySQL排序前9000010记录,仅仅返回9000000 - 9000010的记录,其他记录丢弃,查询排序的代价非常大 。 优化思路:一般分页查询时,通过创建覆盖索引能够比较好地提高性能,可以通过覆盖索引加子查询形式进行优化。
-
什么是表层网页?什么是深层网页?
在互联网中,网页按存在方式可以分为表层网页和深层网页两类。 所谓的表层网页,指的是不需要提交表单,使用静态的链接就能够到达的静态页面;而深层网页则隐藏在表单后面,不能通过静态链接直接获取,是需要提交一定的关键词后才能够获取到的页面,深层网络爬虫(deep Web crawler)最重要的部分即为表单填写部分。
-
sum()函数和count()函数的区别是什么?
python中函数COUNT()的功能是统计字符串里某个字符出现的次数,语法为【str.count("char", start,end)】,其中str为要统计的字符,star为索引字符串的起始位置,end为索引字符串的结束位置。 ython中函数SUM()顾名思义,sum() 函数用于对序列求和计算。
-
Python中如何给变量加注释?
好的变量和注释并非为计算机而写,而是为每个阅读代码的人而写。变量与注释是表达作者思想的基础,他们对代码质量的贡献母庸质疑。 不论我们编写什么程序,写注释是一个很好的习惯。这不仅方便自己今后能读懂程序,也方便别人能读懂你的程序。特别是在维护程序时,注释显得特别重要,即使自己写的程序,时间长了,很可能也忘记你的具体思路。
-
Python如何区别可变数据类型和不可变数据类型?
1、可变数据类型内存地址并没有开辟新的内存,包括列表、字典、集合。 可变数据类型是当该数据类型对应变量的值发生变化时,对应内存地址并没有开辟新的内存。 2、不可变数据类型相反。包括数字、字符串、元组。 不可变数据类型是当该数据类型对应变量的值发生变化时,原来内存中的值不变,而是会开辟一块新的内存,变量指向新的内存地址。
-
 关于SpringBoot项目整合Mybatis时XXXMapper.xml文件存放位置你了解多少?
关于SpringBoot项目整合Mybatis时XXXMapper.xml文件存放位置你了解多少?我们在SpringBoot项目整合Mybatis时或多或少遇到过这个问题,怎么他的XXXMapper.xml文件放在resources目录下了?哎?他的又在src/main/java/xxx目录下? 带着这些疑问,我们来了解下不同位置下XXXMapper.xml文件到底该怎么处理。 1 SpringBoot整合Mybatis 1.1 pom依赖 <!-- mybatis依赖 --> <depend
-
 SpringBoot整合数据库之如何整合JdbcTemplate并支持多个数据源?
SpringBoot整合数据库之如何整合JdbcTemplate并支持多个数据源?使用JDBC是开发者必备的基础技能,只有熟悉了基础的JDBC,才能更加深入地学习其他的ORM框架。 下面给大家SpringBoot整合数据库之如何整合JdbcTemplate并支持多个数据源? 1 整合JdbcTemplate 1.1 引入需要的pom依赖
-
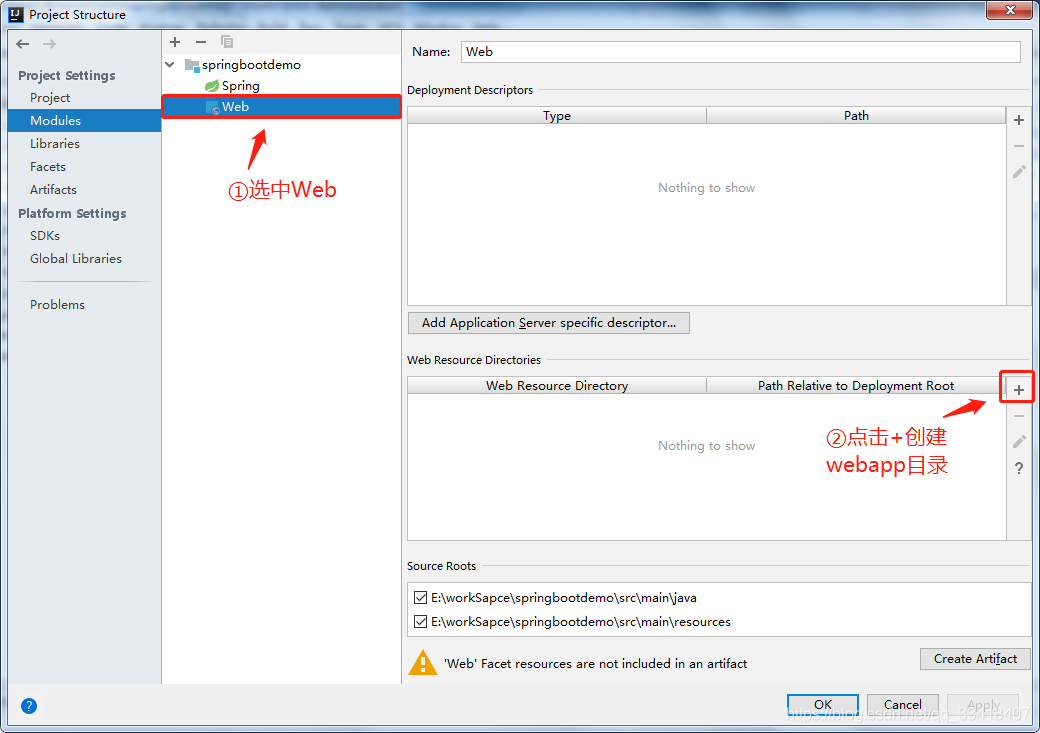 Intellij IDEA中Spring Boot怎么整合jsp?
Intellij IDEA中Spring Boot怎么整合jsp?Springboot默认是不持jsp的, 它的默认是Thymeleaf模板, 所以我们要手动对其进行配置。在IDEA中添加webapp 选中我们的项目,然后右击,选择Open Module Settings,快捷键使用F4