
使用Python的wordcloud库时,为什么不将停用词排除在词云之外?

我想将“ The”,“他们”和“
My”排除在我的词云中。我正在使用如下所示的python库’wordcloud’,并使用这3个其他停用词来更新STOPWORDS列表,但wordcloud仍包括它们。我需要更改什么才能排除这三个词?
我导入的库是:
import numpy as np
import pandas as pd
from wordcloud import WordCloud, STOPWORDS
import matplotlib.pyplot as plt
我曾尝试按照以下步骤将元素添加到STOPWORDS集中,但是即使单词添加成功,wordcloud仍显示我添加到STOPWORDS集中的3个单词:
len(STOPWORDS) 输出:192
然后我跑了:
STOPWORDS.add('The')
STOPWORDS.add('They')
STOPWORDS.add('My')
然后我跑了:
len(STOPWORDS) 输出:195
我正在运行python版本3.7.3
我知道我可以在运行wordcloud之前修改文本输入以删除3个单词(而不是尝试修改WordCloud的STOPWORDS集),但是我想知道WordCloud是否存在错误,或者我是否未正确更新/使用STOPWORDS?
问题答案:
Wordcloud的默认设置是collocations=True,因此两个相邻单词的常用短语都包含在云中-
对于您的问题,重要的是,搭配使用时,停用词的去除方式有所不同,例如“谢谢”是有效的搭配,并且可能即使默认单词中的“
you”也会出现在生成的云中。仅包含停用词的 并置会被 删除。
听起来不合理的理由是,如果在构建搭配列表之前删除停用词,则例如“非常感谢”将提供“非常感谢”作为搭配,我当然不希望这样。
因此,为了使您的停用词按预期运行,即云中完全没有停用词出现,可以这样使用collocations=False:
my_wordcloud = WordCloud(
stopwords=my_stopwords,
background_color='white',
collocations=False,
max_words=10).generate(all_tweets_as_one_string)
更新:
- 如果并置为False,则停用词都将全部小写,以便在删除时将其与小写文本进行比较-因此无需添加’The’等。
- 如果搭配词为True(默认),而停用词是小写的,则在寻找所有停用词搭配以将其删除时,源文本不是小写的,因此
The删除时文本中的鸡蛋也不会the被删除-这就是@Balaji Ambresh的原因代码有效,您将看到云中没有上限。不确定,这可能是Wordcloud中的缺陷。但是,The在停用词中添加例如不会影响这一点,因为停用词总是小写,无论并置为True / False
这在源代码中都是可见的:-)
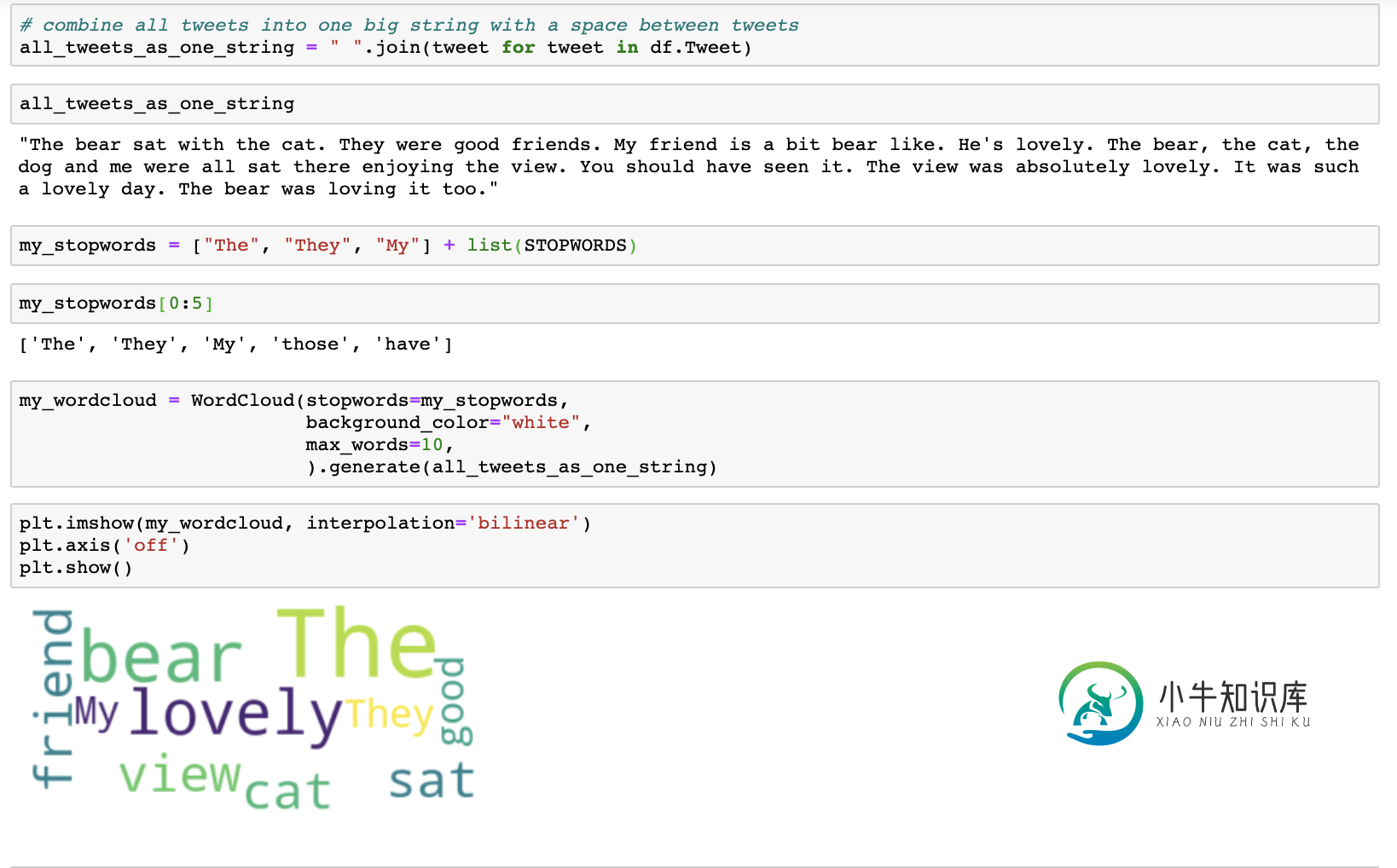
例如,使用默认值,collocations=True我得到:

随着collocations=False我得到:

码:
from wordcloud import WordCloud
from matplotlib import pyplot as plt
text = "The bear sat with the cat. They were good friends. " + \
"My friend is a bit bear like. He's lovely. The bear, the cat, the dog and me were all sat " + \
"there enjoying the view. You should have seen it. The view was absolutely lovely. " + \
"It was such a lovely day. The bear was loving it too."
cloud = WordCloud(collocations=False,
background_color='white',
max_words=10).generate(text)
plt.imshow(cloud, interpolation='bilinear')
plt.axis('off')
plt.show()
-
本文向大家介绍Python基于jieba, wordcloud库生成中文词云,包括了Python基于jieba, wordcloud库生成中文词云的使用技巧和注意事项,需要的朋友参考一下 代码如下 准备文件:需要在当前程序运行目录准备一个中文文本文件NSFC.txt。 程序运行后,完成对NSFC.txt文件中的中文统计,并输出图形文件展示词云。 图片效果如下: 以上就是本文的全部内容,希望对大家的
-
本文向大家介绍在Python中使用NLTK删除停用词,包括了在Python中使用NLTK删除停用词的使用技巧和注意事项,需要的朋友参考一下 当计算机处理自然语言时,某些极端通用的单词似乎在帮助选择符合用户需求的文档方面几乎没有值,因此完全从词汇表中排除了。这些单词称为停用词。 例如,如果您输入的句子为- 停止单词删除后,您将获得输出- NLTK收集了这些停用词,我们可以将其从任何给定的句子中删除。
-
问题内容: 是否可以使用正则表达式删除文本中的小词?例如,我有以下字符串(文本): 我想删除所有不超过3个字符的单词。结果应为: 使用正则表达式或任何其他python函数可以做到吗? 谢谢。 问题答案: 当然,这也不难: 上面的表达式选择任何以某些非单词字符开头的单词(本质上是空格或开头),其长度在1-3个字符之间,并以单词边界结尾。 该边界的比赛是很重要的位置,他们保证你不匹配只是一个字的第一个
-
问题内容: 我正在尝试从文本字符串中删除停用词: 我正在处理600万这种字符串,因此速度很重要。分析我的代码,最慢的部分是上面的几行,是否有更好的方法来做到这一点?我正在考虑使用正则表达式之类的东西,但我不知道如何为一组单词写模式。有人可以帮我忙吗,我也很高兴听到其他可能更快的方法。 注意:我尝试过有人建议用来包裹,但这没什么区别。 谢谢。 问题答案: 尝试缓存停用词对象,如下所示。每次调用函数时
-
我一直在用spaCy查找最常用的名词和noun_phrases 在寻找单个名词时,我可以成功地去掉标点符号并停止单词 然而,使用noun_chunks来确定短语会导致属性错误 spacy.tokens.span.Span对象没有属性 我理解的性质的消息但我不能为我的生活得到语法正确的地方存在的停止字在一个emmatiated字符串将排除从被附加到noun_phrases列表 不删除停止字的输出 [
-
我有以下问题:有几个文本文档需要解析和创建索引,但没有停止词和词干。我可以手动操作,但我从一位同事那里听说Lucene可以自动操作。我在网上搜索了很多我尝试过的例子,但是每个例子都使用了不同版本的lucene和不同的方法,没有一个例子是完整的。在这个过程结束时,我需要计算集合中每个术语的tf/idf。 更新:我现在已经用一个文档创建了一个索引。doc没有停止词,并且有词干。如何使用lucenc计算