
xgboost原理,怎么防过拟合?

参考回答:
XGBoost是一个树集成模型,它使用的是K(树的总数为K)个树的每棵树对样本的预测值的和作为该样本在XGBoost系统中的预测,定义函数如下:
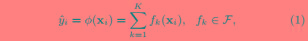
对于所给的数据集有n个样本,m个特征,定义为:

其中Xi表示第i个样本,yi表示第i个样本的类别标签。CART树的空间为F,如下:
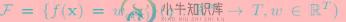
其中q表示每棵树的结构映射每个样本到相应的叶节点的分数,即q表示树的模型,输入一个样本,根据模型将样本映射到叶节点输出预测的分数;Wq(x)表示树q的所有叶节点的分数组成集合;T是树q的叶节点数量。
所以,由(1)式可以看出,XGBoost的预测值为每棵树的预测值之和,即每棵树相应的叶节点的得分之和(Wi的和,Wi表示第i个叶节点的得分)。
我们的目标就是学习这样的K个树模型f(x).。为了学习模型f(x),我们定义下面的目标函数:


其中,(2)式右边第一项为损失函数项,即训练误差,是一个可微的凸函数(比如用于回归的均方误差和用于分类的Logistic误差函数等),第二项为正则化项,即每棵树的复杂度之和,目的是控制模型的复杂度,防止过拟合。我们的目标是在L(φ)取得最小化时得出对应的模型f(x)。
由于XGBoost模型中的优化参数是模型f(x),不是一个具体的值,所以不能用传统的优化方法在欧式空间中进行优化,而是采用additive training的方式去学习模型。每一次保留原来的模型不变,加入一个新的函数f到模型中,如下:

预测值在每一次迭代中加入一个新的函数f目的是使目标函数尽量最大地降低。
因为我们的目标是最小化L(φ)时得到模型f(x),但是L(φ)中并没有参数f(x),所以,我们将上图中的最后一式代入L(φ)中可得到如下式子:
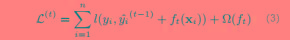
对于平方误差(用于回归)来说(3)式转换成如下形式:

对于不是平方误差的情况下,一般会采用泰勒展开式来定义一个近似的目标函数,以方便我们的进一步计算。
根据如下的泰勒展开式,移除高阶无穷小项,得:


(3)式等价于下面的式子:
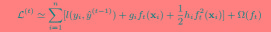
由于我们的目标是求L(φ)最小化时的模型f(x)(也是变量),当移除常数项时模型的最小值变化,但是取最小值的变量不变(比如:y=x^2+C,无论C去何值,x都在0处取最小值)。所以,为了简化计算,我们移除常数项,得到如下的目标函数:

定义 为叶节点j的实例,重写(4)式,将关于树模型的迭代转换为关于树的叶子节点的迭代,得到如下过程:
为叶节点j的实例,重写(4)式,将关于树模型的迭代转换为关于树的叶子节点的迭代,得到如下过程:

此时我们的目标是求每棵树的叶节点j的分数Wj,求出Wj后,将每棵树的Wj相加,即可得到最终的预测的分数。而要想得到最优的Wj的值,即最小化我们的目标函数,所以上式对Wj求偏导,并令偏导数为0,算出此时的W*j为:


将W*j代入原式得:

方程(5)可以用作得分(score)函数来测量树结构q的质量。该得分类似于评估决策树的不纯度得分,除了它是针对更广泛的目标函数得出的。
在xgboost调中,一般有两种方式用于控制过拟合:1)直接控制参数的复杂度:包括max_depth min_child_weight gamma;2)add randomness来使得对训练对噪声鲁棒。包括subsample colsample_bytree,或者也可以减小步长 eta,但是需要增加num_round,来平衡步长因子的减小。
-
本文向大家介绍怎么防止过拟合相关面试题,主要包含被问及怎么防止过拟合时的应答技巧和注意事项,需要的朋友参考一下 参考回答: 1).在训练和建立模型的时候,从相对简单的模型开始,不要一开始就把特征做的非常多,模型参数跳的非常复杂。 2).增加样本,要覆盖全部的数据类型。数据经过清洗之后再进行模型训练,防止噪声数据干扰模型。 3).正则化。在模型算法中添加惩罚函数来防止过拟合。常见的有L1,L2正则化
-
本文向大家介绍xgboost特征并行化怎么做的?相关面试题,主要包含被问及xgboost特征并行化怎么做的?时的应答技巧和注意事项,需要的朋友参考一下 参考回答: 决策树的学习最耗时的一个步骤就是对特征值进行排序,在进行节点分裂时需要计算每个特征的增益,最终选增益大的特征做分裂,各个特征的增益计算就可开启多线程进行。而且可以采用并行化的近似直方图算法进行节点分裂。
-
正则化方法:防止过拟合,提高泛化能力 在机器学习各种模型训练数据不够多时,或者overtraining时,常常会导致overfitting(过拟合)。其直观的表现如下图所示,随着训练过程的进行,模型复杂度增加,在training data上的error渐渐减小,但是在验证集上的error却反而渐渐增大——因为训练出来的网络过拟合了训练集,对训练集外的数据却不work。 为了防止overfittin
-
本文向大家介绍怎么防止死锁?相关面试题,主要包含被问及怎么防止死锁?时的应答技巧和注意事项,需要的朋友参考一下 尽量使用 tryLock(long timeout, TimeUnit unit)的方法(ReentrantLock、ReentrantReadWriteLock),设置超时时间,超时可以退出防止死锁。 尽量使用 Java. util. concurrent 并发类代替自己手写锁。 尽量
-
本文向大家介绍问题:如何防止过拟合?相关面试题,主要包含被问及问题:如何防止过拟合?时的应答技巧和注意事项,需要的朋友参考一下 参考回答: 1.早停法;2.l1和l2正则化;3.神经网络的dropout;4.决策树剪枝;5.SVM的松弛变量;6.集成学习 解析:能够达到模型权重减小,模型简单的效果
-
什么是 xgboost? XGBoost :eXtreme Gradient Boosting 项目地址:https://github.com/dmlc/xgboost 是由 Tianqi Chenhttp://homes.cs.washington.edu/~tqchen/最初开发的实现可扩展,便携,分布式 gradient boosting (GBDT, GBRT or GBM) 算法的一个库