
根据熊猫中的列进行分组和自动递增

我有一个看起来像这样的熊猫框架:
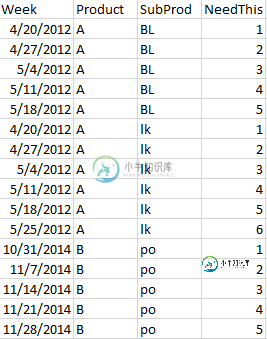
有没有一种方法可以在最后一列中添加数字而不必遍历数据帧?
我在玩熊猫分组和自动递增组ID的结果,但没有达到我的目的
这是产生数据框的代码
import pandas as pd
columns = ['Product','SubProd', 'NeedThis']
Index=['4/20/2012','4/27/2012','5/4/2012','5/11/2012','5/18/2012','4/20/2012',
'4/27/2012','5/4/2012','5/11/2012','5/18/2012','5/25/2012','10/31/2014','11/7/2014',
'11/14/2014','11/21/2014','11/28/2014']
datas = {'Product' : ['A','A','A','A','A','A','A','A','A','A','A','B','B','B','B','B'],
'SubProd' : ['BL','BL','BL','BL','BL','lk','lk','lk','lk','lk','lk','po','po','po','po','po']}
df = pd.DataFrame(data=datas, index=Index)
print(df)
谢谢
问题答案:
In [10]: df['counter'] = df.groupby(['Product','SubProd']).cumcount()+1
In [11]: df
Out[11]:
Product SubProd counter
4/20/2012 A BL 1
4/27/2012 A BL 2
5/4/2012 A BL 3
5/11/2012 A BL 4
5/18/2012 A BL 5
4/20/2012 A lk 1
4/27/2012 A lk 2
5/4/2012 A lk 3
5/11/2012 A lk 4
5/18/2012 A lk 5
5/25/2012 A lk 6
10/31/2014 B po 1
11/7/2014 B po 2
11/14/2014 B po 3
11/21/2014 B po 4
11/28/2014 B po 5
-
问题内容: 我想对以下数据框进行排序: 我想对它进行排序,以便根据列表对LSE列进行重新排序: 当然,其他列也需要相应地重新排序。有没有办法在熊猫里做到这一点? 问题答案: pandas0.15版中对s的改进支持使您可以轻松做到这一点: 如果这只是临时排序,则可能不希望将LSE列保留为a ,但是如果您希望这种排序能够在不同的上下文中使用几次,则是一个很好的解决方案。 在更高版本的,中,已被替换为,
-
我有一个熊猫数据框,大约有50列和
-
我想对两列使用不同的条件来聚合行。 当我做,我得到输出1 当我做时,我得到输出2 是否有一种方法可以进行聚合,将输出1显示到,将输出2显示到?
-
问题内容: 我有大约700万行,其中有60列以上。数据超出了我的内存容量。我正在基于列“ A”的值将数据聚合到组中。熊猫拆分/汇总/合并的文档假定我已经将所有数据都存储在了,但是我无法将整个商店读取到内存中。在分组数据的正确方法是什么? 问题答案: 这是一个完整的例子。 输出量 一些警告: 1)如果您的组密度相对较低,则此方法很有意义。大约数百或数千个组。如果获得的收益更多,则效率更高(但方法更复
-
我正在使用此数据框: 我想通过名称和水果将其聚合,得到每个名称的水果总数。 我试着按名字和水果分组,但如何得到水果的总数呢。
-
问题内容: 我有以下数据框 基本上我可以如下过滤行 我可以如下所示删除/删除一行 但是我想根据条件删除一定数量的行,我该怎么做? 问题答案: 最好的是但需要反转条件-使所有值相等且更高,如下所示: 与功能相同: 另一种可能的解决方案是通过以下方法反转掩码:
-
问题内容: 我有一些数据,导入时会得到以下不需要的列,我正在寻找一种删除所有这些数据的简便方法 它们被0索引索引,所以我尝试了类似 但这不是很有效。我尝试编写一些for循环,但这使我感到震惊,因为熊猫的行为不佳。因此,我在这里问这个问题。 我已经看到了一些类似的示例(投递多列pandas),但这无法回答我的问题。 问题答案: 我不知道您所说的低效率是什么意思,但是如果您指的是打字,那么选择感兴趣的
-
我有一个数据框架: 和一本参考词典: 我的目标是将所有出现的< code > replacement _ dict[' X1 ']替换为' X1 ',然后将这些行合并在一起。例如,“x1”、“x2”、“x3”或“x4”的任何实例都将被替换为“X1”等。 我可以通过选择包含任何这些字符串的行并将其替换为“X1”来实现这一点: 给予: 现在,如果我选择所有包含“X1”的行并将它们合并,我将得到: 因此