
包含超过20列的表的各列求和而不写出总和

所以我需要在我正在使用的表中获取20多个列的总和,我真的很想不必写出每一列的总和,但是我不确定这是可能的。有没有办法让它为表中的所有列动态写入?
select isnull(osname, 'Total'), COUNT(*), SUM(col1), SUM(col2), SUM(col3)...sum(col27)
from usage
group by osname
with rollup
问题答案:
首先,如果可以自动化,请这样做。输入20、100列绝对是乏味的。
我下面的解决方案使用表变量函数来获取编号列的列表。这可以再次重用。
其次,我使用此函数并应用您的逻辑来创建一些动态的T-SQL。WITH ROLLUP语法不符合ISO。在2008 R2中已将其替换。
http://technet.microsoft.com/zh-
CN/library/ms177673.aspx
让我们谈正事吧。我喜欢创建一个快速测试表以确保我的语法正确。甚至我也会犯错。
--
-- Setup test data
--
-- Just playing around
use tempdb;
go
-- Drop test table
if object_id ('usage') > 0
drop table usage
go
-- Create test table
create table usage
( osname varchar(16),
col1 int,
col2 int,
col3 int,
col4 int,
col5 int
);
go
-- Test data
insert into usage values
('UNIX', 1, 2, 3, 4, 5),
('UNIX', 2, 4, 6, 8, 10),
('WIN7', 1, 2, 3, 4, 5),
('WIN7', 2, 4, 6, 8, 10),
('WIN8', 5, 10, 15, 20, 25);
go
-- Show the data
select * from usage;
go
接下来,让我们创建一个内联表值函数。它们相对较快。
http://blog.waynesheffield.com/wayne/archive/2012/02/comparing-inline-and-
multistatement-table-valued-
functions/
--
-- Create helper function
--
-- Remove ITVF
if object_id('get_columns') > 0
drop function get_columns
go
-- Create ITVF
create function get_columns (@table_name sysname)
returns table
as
return
(
select top 100 column_id, name from sys.columns where object_id in
( select object_id from sys.tables t where t.name = @table_name )
order by column_id
)
go
-- Get the columns
select * from get_columns('usage');
go
现在,将它们放在一起解决您的问题。注意,您需要保留被遗漏的列名。我还改用了符合ISO的语法。
--
-- Solve the problem
--
-- Dynamic SQL
declare @var_tsql nvarchar(max) = 'SELECT ';
select
@var_tsql +=
case
when column_id <> 1 then 'SUM(' + name + ') as s_' + name + ', '
else 'ISNULL(' + name + ', ''Total'') as s_name, '
end
from get_columns('usage');
select @var_tsql += 'COUNT(*) as s_count FROM usage GROUP BY ROLLUP(osname); '
--print @var_tsql
EXEC sp_executesql @var_tsql;
print语句用于调试任何语法错误。剪切并粘贴到另一个窗口中以检查语法。您学得越多,动态SQL就越容易。
上面的动态TSQL可以正常工作。这是您的输出。
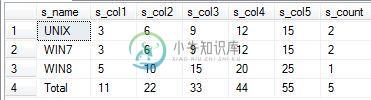
-
问题内容: 让 假设我要对列表中每个列表的索引元素求和,例如在矩阵列中添加数字以获得单个列表。我假设数据中的所有列表的长度均相等。 如何遍历列表列表而不会出现索引超出范围错误?也许lambda?谢谢! 问题答案: 您可以尝试以下方法: 这里使用的组合和解压的列表,然后根据自己的索引压缩的项目。然后,您可以使用列表推导来遍历相似索引的组,对其进行求和并返回其“原始”位置。 为了更清楚一点,下面是迭代
-
我发现了许多关于比较列表对象而不管其元素的顺序如何的问题和答案,但我的问题更复杂:我有两个bean,其中包含一个列表。我希望对这两个bean执行assertEquals,而不管内部列表中元素的顺序如何。有没有一个简单的方法可以做到这一点?
-
我有一个GeoPandas df: 看起来像: 如何将坐标列转换为LineString(无论元组列表中有多少个点)?例如。: 编辑:我试过(见Prateek的回答): 以及: 两者都返回以下错误: 属性错误回溯(上次调用)~/opt/anaconda3/lib/python3.8/site-packages/shapely/speedups//u speedups.pyx in shapely.s
-
问题内容: 这是很常见的,我遍历一个Python列表,让双方的内容 和 他们的索引。我通常会执行以下操作: 我发现这种语法有点难看,尤其是函数内部的部分。还有其他更优雅/ Python风格的方法吗? 问题答案: 使用内置函数:http : //docs.python.org/library/functions.html#enumerate
-
我有一个列表的数据集,其中包含其他列表,我想找到前1000个单词 我试过这个,但不起作用: 从集合导入计数器counts_top1000=[逐字,Counter(mainlist).MOST_COMMAN(1000)] 请注意,我的数据集是“mainlist”。 如果你有更多的想法,我将不胜感激。
-
这个问题是由打字错误或无法再复制的问题引起的。虽然这里可能有类似的问题,但这一问题的解决方式不太可能帮助未来的读者。 总结: 对于我的商务课程,我们必须开发产品和/或服务。我正试图为其他团队开发一个解决方案,帮助他们管理库存。我已经有一个用Python开发的程序了,但是,C使开发GUI变得更容易(谢谢你,Visual Studio)。我在列表方面有困难。 以前检查过的资源: 在C中创建列表列表#