
副本一致性
目前线程模型
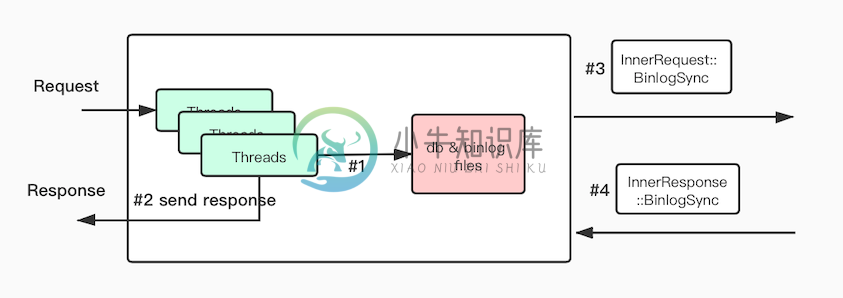
非一致性场景
1,客户端请求加锁写入db和binlog文件
2,将结果返回客户端
3,通过发送BinlogSync请求向从库同步
4,从库返回BinlogSyncAck报告同步状况
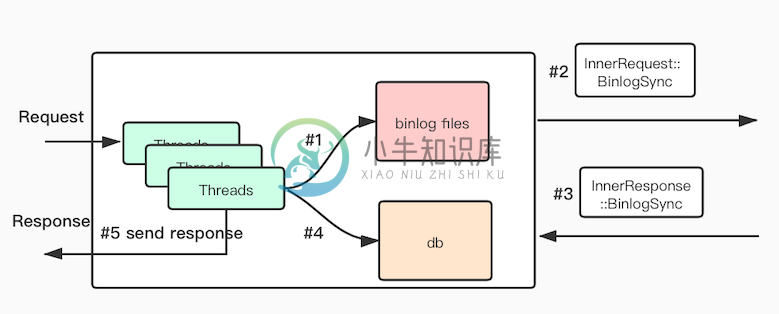
一致性场景
1,客户端请求先写入binlog文件
2,通过发送BinlogSync请求向从库同步
3,从库返回BinlogSyncAck报告同步状况
4,将相应的请求写入db
5,将结果返回客户端
Binlog Header变动
/*
* *****************Type First Binlog Item Format******************
* |<Type>|<CreateTime>|<Term Id>|<Logic Id>|<File Num>|<Offset>|<Content Length>|<Content>|
* | 2 | 4 | 4 | 8 | 4 | 8 | 4 | ... |
* |----------------------------------------- 34 Bytes ------------------------------------|
*/
其中 TermId, 和Logic id是沿用Raft论文中term 和log index 的概念。具体的详见论文。
其中 File Num 和offset 是本条binlog在文件中的偏移量。
Pika的Binlog存在的意义是为了保证主从能够增量同步,而Raft Log存在的意义是为了保证Leader 和Follower 的数据够一致。某种意义上说这两个"Log"的概念是一样的,所以在实现上,将binlog 和 Raft Log 复用成一条log,目前的binlog header 中 Term Id 和 Logic Id 属于 Raft Log(简称日志)的信息,而File Num 和Offset 属于Binlog 的信息。
一致性协议的三阶段
日志恢复和复制基本按照Raft论文当中所做操作,这里不做过多解释。实现上,这里分为三个阶段。分别是日志的复制,日志的恢复,日志的协商。
熟悉Raft协议的读者可能会发现,这里的三个阶段跟Raft日志复制不是完全一样。在Pika的实现当中,基于pika现有的代码结构,我们把Leader 和Follower同步点位回退的逻辑单独提取出来,形成了Pika Trsysync的状态。任何日志的复制出错,pika会终止当前的日志复制(BinlogSync)状态,转而将状态机转化成Trysync的状态,进而Leader 和Follower 会进入日志的协商逻辑。协商成功之后会转入日志复制的逻辑。
日志复制
日志的逻辑结构如下,上面部分是Leader可能的log点位,下部分是Follower可能的log点位。

1,日志的复制的逻辑可以参考Raft协议的逻辑,这里举例说说明客户端从请求到返回,日志经过了怎样的流程。
Leader Status:
Committed Index : 10
Applied Index:8
Last Index: 15
Follower Status:
Committed Index : 7
Applied Index:5
LastIndex: 12
2,当Leader 发送13-15的日志到Follower的时候,Follower的状态会做如下更新:
Follower Status:
Committed Index : 10
Applied Index:5
LastIndex: 15
这时候日志6-10都是可以被应用到状态机的。但是对于日志11-15来说只能等到下一次收到Leader Committed Index 大于15的时候这些日志才能够被更新,这时候如果客户端没有继续写入,Follower的Committed index可以依靠ping消息(携带了Leader 的committed index)进行更新。
3,当Leader 接收到Follower的ack信息的时候,Leader 状态会做如下更新:
Leader Status:
Committed Index : 15
Applied Index: 8
Last Index: 15
此时日志9-15都是可以被应用到状态机,这里是写db,当日志9写入db之后,就会返回客户端,相应的Applied Index 更新为9。这时候日志9就可以返回客户端。
对于从来说,整体的日志复制的逻辑还是按照Raft论文当中进行的。唯一不同的是论文中日志回退的一部分逻辑放到了日志协商阶段进行。
日志恢复:
重启pika的时候,根据持久话的一致性信息(applied index 等)回复出之前的一致性状态。
日志协商:
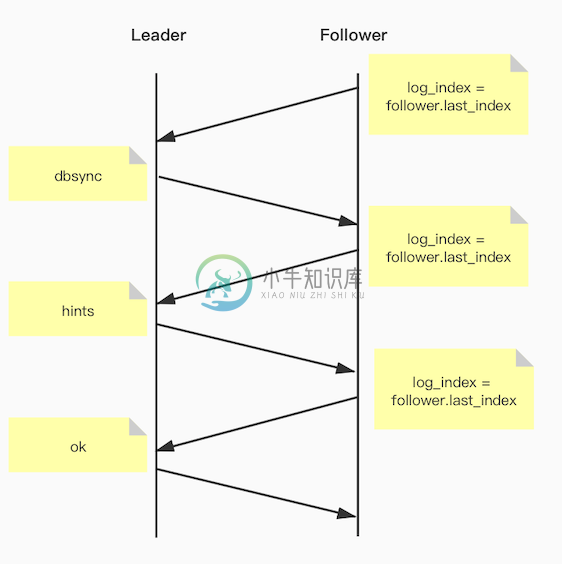
这个阶段Follower节点主动发起Trysync流程,携带Last Index,向Leader发送协商同步点位请求。协商过程如下:
Follower携带last_index发动到Leader, Leader 通过Follower的last_index位置判断是否自己能够找到last_index对应的自己的相应的log,如果找到log并且两个log一致,Leader返回okay协商结束。如果没有找到,或者log不一致,Leader向Follower发送hints,hints是Leader本地的最新的日志。Follower通过hints,回退本地日志,更新自己的last_index,重新向主协商。最终Leader Follower达成一致,结束TrySync流程,进行日志复制流程。
Leader 日志协商的伪代码如下:
Status LeaderNegotiate() {
reject = true
if (follower.last_index > last_index) {
send[last_index - 100, last_index]
} else if (follower.last_index < first_index) {
need dbsync
}
if (follower.last_index not found) {
need dbsync
}
if (follower.last_index found but term not equal) {
send[found_index - 100, found_index]
}
reject = false
return ok;
}
Follower日志协商的伪代码日下:
Status FollowerNegotiate() {
if last_index > hints[hints.size() - 1] {
TruncateTo(hints[hints.size() - 1]);
}
for (reverse loop hints) {
if (hint.index exist && hint.term == term) {
TruncateTo(hint.index)
send trysync with log_index = hint.index
return ok;
}
}
// cant find any match
TruncateTo(hints[0])
send trysync with log_index = last_index
}
以上介绍了关于日志的具体三个阶段。整体的逻辑遵从与Raft论文的设计,在实现细节上根据Pika目前的代码结构进行了一些列的调整。
关于选主和成员变换
目前选主需要管理员手动介入,详见副本一致性使用文档 。
成员变换的功能目前暂不支持。