6.1 使用 kubeadm 搭建集群环境
架构
上节课我们给大家讲解了 k8s 的基本概念与几个主要的组件,我们在了解了 k8s 的基本概念过后,实际上就可以去正式使用了,但是我们前面的课程都是在 katacoda 上面进行的演示,只提供给我们15分钟左右的使用时间,所以最好的方式还是我们自己来手动搭建一套 k8s 的环境,在搭建环境之前,我们再来看一张更丰富的k8s的架构图。 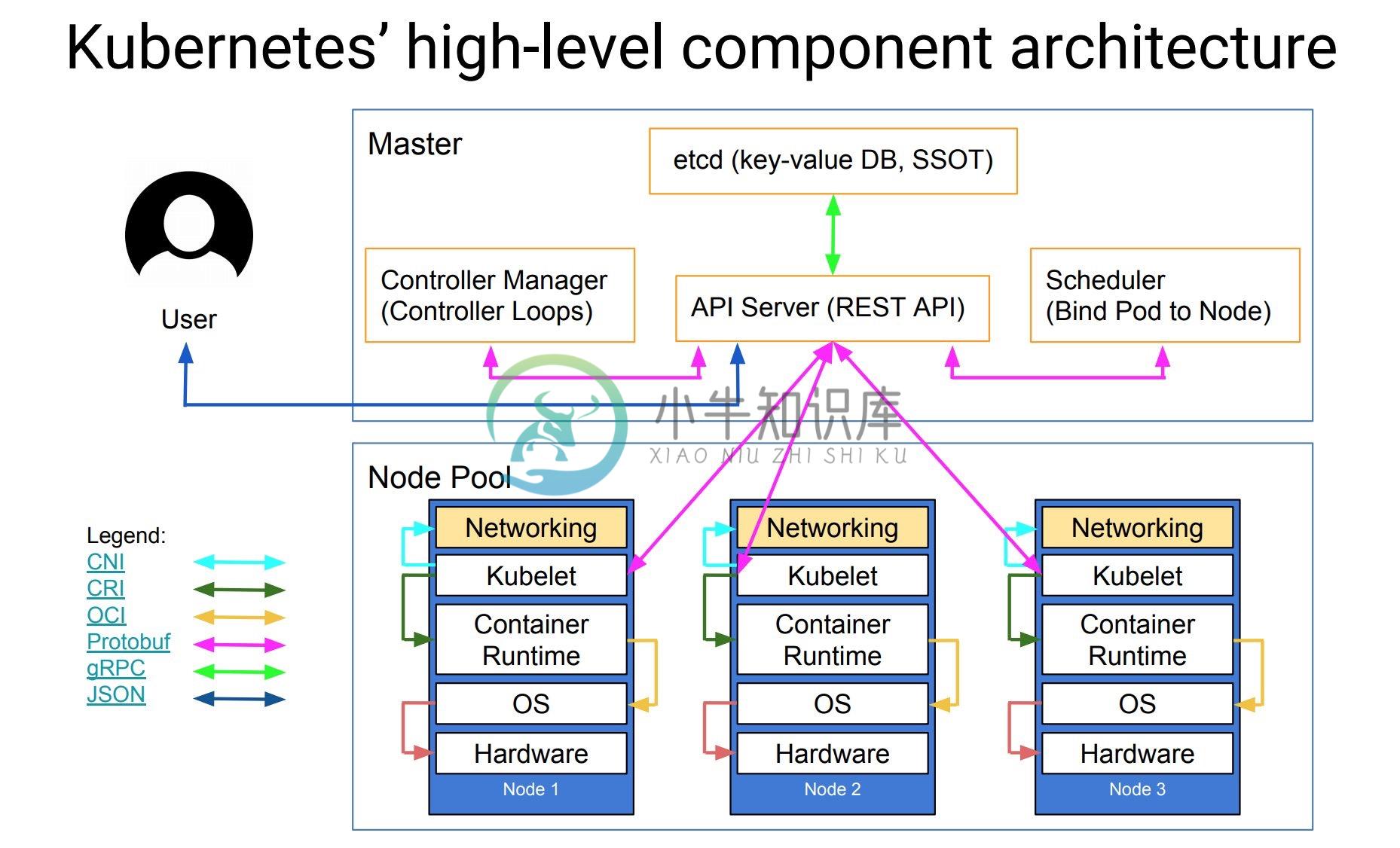
- 核心层:Kubernetes 最核心的功能,对外提供 API 构建高层的应用,对内提供插件式应用执行环境
- 应用层:部署(无状态应用、有状态应用、批处理任务、集群应用等)和路由(服务发现、DNS 解析等)
- 管理层:系统度量(如基础设施、容器和网络的度量),自动化(如自动扩展、动态 Provision 等)以及策略管理(RBAC、Quota、PSP、NetworkPolicy 等)
- 接口层:kubectl 命令行工具、客户端 SDK 以及集群联邦
- 生态系统:在接口层之上的庞大容器集群管理调度的生态系统,可以划分为两个范畴
- Kubernetes 外部:日志、监控、配置管理、CI、CD、Workflow等
- Kubernetes 内部:CRI、CNI、CVI、镜像仓库、Cloud Provider、集群自身的配置和管理等
在更进一步了解了 k8s 集群的架构后,我们就可以来正式的的安装我们的 k8s 集群环境了,我们这里使用的是kubeadm工具来进行集群的搭建。
kubeadm是Kubernetes官方提供的用于快速安装Kubernetes集群的工具,通过将集群的各个组件进行容器化安装管理,通过kubeadm的方式安装集群比二进制的方式安装要方便不少,但是目录kubeadm还处于 beta 状态,还不能用于生产环境,Using kubeadm to Create a Cluster文档中已经说明 kubeadm 将会很快能够用于生产环境了。对于现阶段想要用于生产环境的,建议还是参考我们前面的文章:手动搭建高可用的 kubernetes 集群或者视频教程。
环境
我们这里准备两台Centos7的主机用于安装,后续节点可以根究需要添加即可:
$ cat /etc/hosts
10.151.30.57 master
10.151.30.62 node01
禁用防火墙:
$ systemctl stop firewalld
$ systemctl disable firewalld
禁用SELINUX:
$ setenforce 0
$ cat /etc/selinux/config
SELINUX=disabled
创建/etc/sysctl.d/k8s.conf文件,添加如下内容:
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
net.ipv4.ip_forward = 1
执行如下命令使修改生效:
$ modprobe br_netfilter
$ sysctl -p /etc/sysctl.d/k8s.conf
镜像
如果你的节点上面有科学上网的工具,可以忽略这一步,我们需要提前将所需的gcr.io上面的镜像下载到节点上面,当然前提条件是你已经成功安装了`docker。master节点,执行下面的命令:
docker pull cnych/kube-apiserver-amd64:v1.10.0
docker pull cnych/kube-scheduler-amd64:v1.10.0
docker pull cnych/kube-controller-manager-amd64:v1.10.0
docker pull cnych/kube-proxy-amd64:v1.10.0
docker pull cnych/k8s-dns-kube-dns-amd64:1.14.8
docker pull cnych/k8s-dns-dnsmasq-nanny-amd64:1.14.8
docker pull cnych/k8s-dns-sidecar-amd64:1.14.8
docker pull cnych/etcd-amd64:3.1.12
docker pull cnych/flannel:v0.10.0-amd64
docker pull cnych/pause-amd64:3.1
docker tag cnych/kube-apiserver-amd64:v1.10.0 k8s.gcr.io/kube-apiserver-amd64:v1.10.0
docker tag cnych/kube-scheduler-amd64:v1.10.0 k8s.gcr.io/kube-scheduler-amd64:v1.10.0
docker tag cnych/kube-controller-manager-amd64:v1.10.0 k8s.gcr.io/kube-controller-manager-amd64:v1.10.0
docker tag cnych/kube-proxy-amd64:v1.10.0 k8s.gcr.io/kube-proxy-amd64:v1.10.0
docker tag cnych/k8s-dns-kube-dns-amd64:1.14.8 k8s.gcr.io/k8s-dns-kube-dns-amd64:1.14.8
docker tag cnych/k8s-dns-dnsmasq-nanny-amd64:1.14.8 k8s.gcr.io/k8s-dns-dnsmasq-nanny-amd64:1.14.8
docker tag cnych/k8s-dns-sidecar-amd64:1.14.8 k8s.gcr.io/k8s-dns-sidecar-amd64:1.14.8
docker tag cnych/etcd-amd64:3.1.12 k8s.gcr.io/etcd-amd64:3.1.12
docker tag cnych/flannel:v0.10.0-amd64 quay.io/coreos/flannel:v0.10.0-amd64
docker tag cnych/pause-amd64:3.1 k8s.gcr.io/pause-amd64:3.1
可以将上面的命令保存为一个 shell 脚本,然后直接执行即可。这些镜像是在 master 节点上需要使用到的镜像,一定要提前下载下来。其他Node,执行下面的命令:
docker pull cnych/kube-proxy-amd64:v1.10.0
docker pull cnych/flannel:v0.10.0-amd64
docker pull cnych/pause-amd64:3.1
docker pull cnych/kubernetes-dashboard-amd64:v1.8.3
docker pull cnych/heapster-influxdb-amd64:v1.3.3
docker pull cnych/heapster-grafana-amd64:v4.4.3
docker pull cnych/heapster-amd64:v1.4.2
docker pull cnych/k8s-dns-kube-dns-amd64:1.14.8
docker pull cnych/k8s-dns-dnsmasq-nanny-amd64:1.14.8
docker pull cnych/k8s-dns-sidecar-amd64:1.14.8
docker tag cnych/flannel:v0.10.0-amd64 quay.io/coreos/flannel:v0.10.0-amd64
docker tag cnych/pause-amd64:3.1 k8s.gcr.io/pause-amd64:3.1
docker tag cnych/kube-proxy-amd64:v1.10.0 k8s.gcr.io/kube-proxy-amd64:v1.10.0
docker tag cnych/k8s-dns-kube-dns-amd64:1.14.8 k8s.gcr.io/k8s-dns-kube-dns-amd64:1.14.8
docker tag cnych/k8s-dns-dnsmasq-nanny-amd64:1.14.8 k8s.gcr.io/k8s-dns-dnsmasq-nanny-amd64:1.14.8
docker tag cnych/k8s-dns-sidecar-amd64:1.14.8 k8s.gcr.io/k8s-dns-sidecar-amd64:1.14.8
docker tag cnych/kubernetes-dashboard-amd64:v1.8.3 k8s.gcr.io/kubernetes-dashboard-amd64:v1.8.3
docker tag cnych/heapster-influxdb-amd64:v1.3.3 k8s.gcr.io/heapster-influxdb-amd64:v1.3.3
docker tag cnych/heapster-grafana-amd64:v4.4.3 k8s.gcr.io/heapster-grafana-amd64:v4.4.3
docker tag cnych/heapster-amd64:v1.4.2 k8s.gcr.io/heapster-amd64:v1.4.2
上面的这些镜像是在 Node 节点中需要用到的镜像,在 join 节点之前也需要先下载到节点上面。
安装 kubeadm、kubelet、kubectl
在确保 docker 安装完成后,上面的相关环境配置也完成了,对应所需要的镜像(如果可以科学上网可以跳过这一步)也下载完成了,现在我们就可以来安装 kubeadm 了,我们这里是通过指定yum 源的方式来进行安装的:
cat <<EOF > /etc/yum.repos.d/kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=https://packages.cloud.google.com/yum/repos/kubernetes-el7-x86_64
enabled=1
gpgcheck=1
repo_gpgcheck=1
gpgkey=https://packages.cloud.google.com/yum/doc/yum-key.gpg
https://packages.cloud.google.com/yum/doc/rpm-package-key.gpg
EOF
当然了,上面的yum源也是需要科学上网的,如果不能科学上网的话,我们可以使用阿里云的源进行安装:
cat <<EOF > /etc/yum.repos.d/kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=http://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64
enabled=1
gpgcheck=0
repo_gpgcheck=0
gpgkey=http://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg
http://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg
EOF
注意:由于阿里云的源将依赖进行了更改,如果你需要安装 1.10.0 版本的集群的话,需要使用下面的命令分别安装:
$ yum makecache fast
$ yum install -y kubelet-1.10.0-0
$ yum install -y kubectl-1.10.0-0
$ yum install -y kubeadm-1.10.0-0
正常情况我们可以都能顺利安装完成上面的文件。
配置 kubelet
安装完成后,我们还需要对kubelet进行配置,因为用yum源的方式安装的kubelet生成的配置文件将参数--cgroup-driver改成了systemd,而 docker 的cgroup-driver是cgroupfs,这二者必须一致才行,我们可以通过docker info命令查看:
$ docker info |grep Cgroup
Cgroup Driver: cgroupfs
修改文件 kubelet 的配置文件/etc/systemd/system/kubelet.service.d/10-kubeadm.conf,将其中的KUBELET_CGROUP_ARGS参数更改成cgroupfs:
Environment="KUBELET_CGROUP_ARGS=--cgroup-driver=cgroupfs"
另外还有一个问题是关于交换分区的,之前我们在手动搭建高可用的 kubernetes 集群一文中已经提到过,Kubernetes 从1.8开始要求关闭系统的 Swap ,如果不关闭,默认配置的 kubelet 将无法启动,我们可以通过 kubelet 的启动参数--fail-swap-on=false更改这个限制,所以我们需要在上面的配置文件中增加一项配置(在ExecStart之前):
Environment="KUBELET_EXTRA_ARGS=--fail-swap-on=false"
当然最好的还是将 swap 给关掉,这样能提高 kubelet 的性能。修改完成后,重新加载我们的配置文件即可:
$ systemctl daemon-reload
集群安装初始化
到这里我们的准备工作就完成了,接下来我们就可以在master节点上用kubeadm命令来初始化我们的集群了:
$ kubeadm init --kubernetes-version=v1.10.0 --pod-network-cidr=10.244.0.0/16 --apiserver-advertise-address=10.151.30.57
命令非常简单,就是kubeadm init,后面的参数是需要安装的集群版本,因为我们这里选择flannel作为 Pod 的网络插件,所以需要指定–pod-network-cidr=10.244.0.0/16,然后是 apiserver 的通信地址,这里就是我们 master 节点的 IP 地址。执行上面的命令,如果出现running with swap on is not supported. Please disable swap之类的错误,则我们还需要增加一个参数–ignore-preflight-errors=Swap来忽略 swap 的错误提示信息:
$ kubeadm init \
--kubernetes-version=v1.10.0 \
--pod-network-cidr=10.244.0.0/16 \
--apiserver-advertise-address=10.151.30.57 \
--ignore-preflight-errors=Swap
[init] Using Kubernetes version: v1.10.0
[init] Using Authorization modes: [Node RBAC]
[preflight] Running pre-flight checks.
[WARNING FileExisting-crictl]: crictl not found in system pathSuggestion: go get github.com/kubernetes-incubator/cri-tools/cmd/crictl
[preflight] Starting the kubelet service
[certificates] Generated ca certificate and key.
[certificates] Generated apiserver certificate and key.
[certificates] apiserver serving cert is signed for DNS names [ydzs-master1 kubernetes kubernetes.default kubernetes.default.svc kubernetes.default.svc.cluster.local] and IPs [10.96.0.1 10.151.30.57]
[certificates] Generated apiserver-kubelet-client certificate and key.
[certificates] Generated etcd/ca certificate and key.
[certificates] Generated etcd/server certificate and key.
[certificates] etcd/server serving cert is signed for DNS names [localhost] and IPs [127.0.0.1]
[certificates] Generated etcd/peer certificate and key.
[certificates] etcd/peer serving cert is signed for DNS names [ydzs-master1] and IPs [10.151.30.57]
[certificates] Generated etcd/healthcheck-client certificate and key.
[certificates] Generated apiserver-etcd-client certificate and key.
[certificates] Generated sa key and public key.
[certificates] Generated front-proxy-ca certificate and key.
[certificates] Generated front-proxy-client certificate and key.
[certificates] Valid certificates and keys now exist in "/etc/kubernetes/pki"
[kubeconfig] Wrote KubeConfig file to disk: "/etc/kubernetes/admin.conf"
[kubeconfig] Wrote KubeConfig file to disk: "/etc/kubernetes/kubelet.conf"
[kubeconfig] Wrote KubeConfig file to disk: "/etc/kubernetes/controller-manager.conf"
[kubeconfig] Wrote KubeConfig file to disk: "/etc/kubernetes/scheduler.conf"
[controlplane] Wrote Static Pod manifest for component kube-apiserver to "/etc/kubernetes/manifests/kube-apiserver.yaml"
[controlplane] Wrote Static Pod manifest for component kube-controller-manager to "/etc/kubernetes/manifests/kube-controller-manager.yaml"
[controlplane] Wrote Static Pod manifest for component kube-scheduler to "/etc/kubernetes/manifests/kube-scheduler.yaml"
[etcd] Wrote Static Pod manifest for a local etcd instance to "/etc/kubernetes/manifests/etcd.yaml"
[init] Waiting for the kubelet to boot up the control plane as Static Pods from directory "/etc/kubernetes/manifests".
[init] This might take a minute or longer if the control plane images have to be pulled.
[apiclient] All control plane components are healthy after 22.007661 seconds
[uploadconfig] Storing the configuration used in ConfigMap "kubeadm-config" in the "kube-system" Namespace
[markmaster] Will mark node ydzs-master1 as master by adding a label and a taint
[markmaster] Master ydzs-master1 tainted and labelled with key/value: node-role.kubernetes.io/master=""
[bootstraptoken] Using token: 8xomlq.0cdf2pbvjs2gjho3
[bootstraptoken] Configured RBAC rules to allow Node Bootstrap tokens to post CSRs in order for nodes to get long term certificate credentials
[bootstraptoken] Configured RBAC rules to allow the csrapprover controller automatically approve CSRs from a Node Bootstrap Token
[bootstraptoken] Configured RBAC rules to allow certificate rotation for all node client certificates in the cluster
[bootstraptoken] Creating the "cluster-info" ConfigMap in the "kube-public" namespace
[addons] Applied essential addon: kube-dns
[addons] Applied essential addon: kube-proxy
Your Kubernetes master has initialized successfully!
To start using your cluster, you need to run the following as a regular user:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
You should now deploy a pod network to the cluster.
Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at:
https://kubernetes.io/docs/concepts/cluster-administration/addons/
You can now join any number of machines by running the following on each node
as root:
kubeadm join 10.151.30.57:6443 --token 8xomlq.0cdf2pbvjs2gjho3 --discovery-token-ca-cert-hash sha256:92802317cb393682c1d1356c15e8b4ec8af2b8e5143ffd04d8be4eafb5fae368
要注意将上面的加入集群的命令保存下面,如果忘记保存上面的 token 和 sha256 值的话也不用担心,我们可以使用下面的命令来查找:
$ kubeadm token list
kubeadm token list
TOKEN TTL EXPIRES USAGES DESCRIPTION EXTRA GROUPS
i5gbaw.os1iow5tdo17rwdu 23h 2018-05-18T01:32:55+08:00 authentication,signing The default bootstrap token generated by 'kubeadm init'. system:bootstrappers:kubeadm:default-node-token
要查看 CA 证书的 sha256 的值的话,我们可以使用openssl来读取证书获取 sha256 的值:
$ openssl x509 -pubkey -in /etc/kubernetes/pki/ca.crt | openssl rsa -pubin -outform der 2>/dev/null | openssl dgst -sha256 -hex | sed 's/^.* //'
e9ca4d9550e698105f1d8fae7ecfd297dd9331ca7d50b5493fa0491b2b4df40c
另外还需要注意的是当前版本的 kubeadm 支持的docker版本最大是 17.03,所以要注意下。 上面的信息记录了 kubeadm 初始化整个集群的过程,生成相关的各种证书、kubeconfig 文件、bootstraptoken 等等,后边是使用kubeadm join往集群中添加节点时用到的命令,下面的命令是配置如何使用kubectl访问集群的方式:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
最后给出了将节点加入集群的命令:
kubeadm join 10.151.30.57:6443 --token 8xomlq.0cdf2pbvjs2gjho3 --discovery-token-ca-cert-hash sha256:92802317cb393682c1d1356c15e8b4ec8af2b8e5143ffd04d8be4eafb5fae368
我们根据上面的提示配置好 kubectl 后,就可以使用 kubectl 来查看集群的信息了:
$ kubectl get cs
NAME STATUS MESSAGE ERROR
scheduler Healthy ok
controller-manager Healthy ok
etcd-0 Healthy {"health": "true"}
$ kubectl get csr
NAME AGE REQUESTOR CONDITION
node-csr-8qygb8Hjxj-byhbRHawropk81LHNPqZCTePeWoZs3-g 1h system:bootstrap:8xomlq Approved,Issued
$ kubectl get nodes
NAME STATUS ROLES AGE VERSION
ydzs-master1 Ready master 3h v1.10.0
如果你的集群安装过程中遇到了其他问题,我们可以使用下面的命令来进行重置:
$ kubeadm reset
$ ifconfig cni0 down && ip link delete cni0
$ ifconfig flannel.1 down && ip link delete flannel.1
$ rm -rf /var/lib/cni/
安装 Pod Network
接下来我们来安装flannel网络插件,很简单,和安装普通的 POD 没什么两样:
$ wget https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml
$ kubectl apply -f kube-flannel.yml
clusterrole.rbac.authorization.k8s.io "flannel" created
clusterrolebinding.rbac.authorization.k8s.io "flannel" created
serviceaccount "flannel" created
configmap "kube-flannel-cfg" created
daemonset.extensions "kube-flannel-ds" created
另外需要注意的是如果你的节点有多个网卡的话,需要在 kube-flannel.yml 中使用--iface参数指定集群主机内网网卡的名称,否则可能会出现 dns 无法解析。flanneld 启动参数加上--iface=<iface-name>
args:
- --ip-masq
- --kube-subnet-mgr
- --iface=eth0
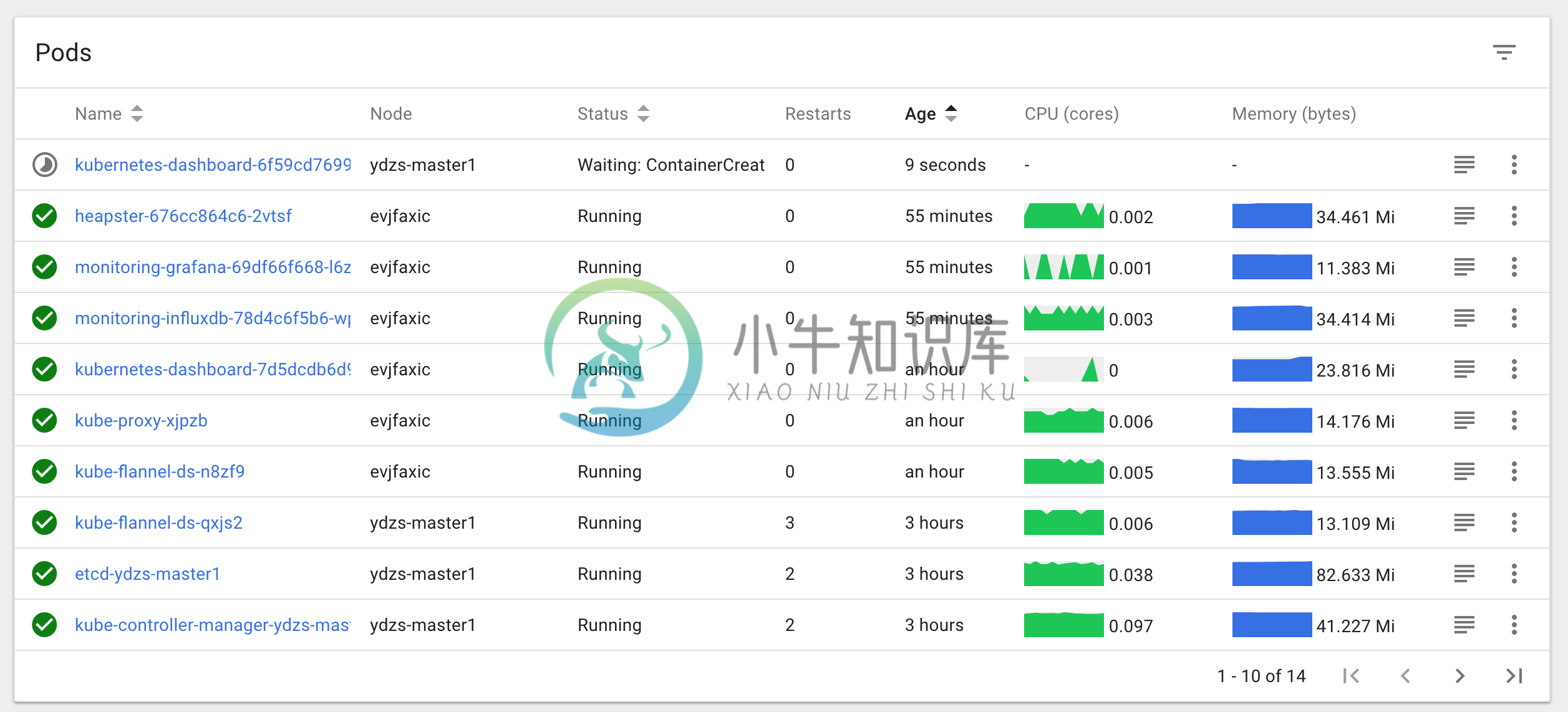
安装完成后使用 kubectl get pods 命令可以查看到我们集群中的组件运行状态,如果都是Running 状态的话,那么恭喜你,你的 master 节点安装成功了。
$ kubectl get pods --all-namespaces
NAMESPACE NAME READY STATUS RESTARTS AGE
kube-system etcd-ydzs-master1 1/1 Running 0 10m
kube-system kube-apiserver-ydzs-master1 1/1 Running 0 10m
kube-system kube-controller-manager-ydzs-master1 1/1 Running 0 10m
kube-system kube-dns-86f4d74b45-f5595 3/3 Running 0 10m
kube-system kube-flannel-ds-qxjs2 1/1 Running 0 1m
kube-system kube-proxy-vf5fg 1/1 Running 0 10m
kube-system kube-scheduler-ydzs-master1 1/1 Running 0 10m
添加节点
同样的上面的环境配置、docker 安装、kubeadmin、kubelet、kubectl 这些都在Node(10.151.30.62)节点安装配置好过后,我们就可以直接在 Node 节点上执行kubeadm join命令了(上面初始化的时候有),同样加上参数--ignore-preflight-errors=Swap:
$ kubeadm join 10.151.30.57:6443 --token 8xomlq.0cdf2pbvjs2gjho3 --discovery-token-ca-cert-hash sha256:92802317cb393682c1d1356c15e8b4ec8af2b8e5143ffd04d8be4eafb5fae368 --ignore-preflight-errors=Swap
[preflight] Running pre-flight checks.
[WARNING Swap]: running with swap on is not supported. Please disable swap
[WARNING FileExisting-crictl]: crictl not found in system path
Suggestion: go get github.com/kubernetes-incubator/cri-tools/cmd/crictl
[discovery] Trying to connect to API Server "10.151.30.57:6443"
[discovery] Created cluster-info discovery client, requesting info from "https://10.151.30.57:6443"
[discovery] Requesting info from "https://10.151.30.57:6443" again to validate TLS against the pinned public key
[discovery] Cluster info signature and contents are valid and TLS certificate validates against pinned roots, will use API Server "10.151.30.57:6443"
[discovery] Successfully established connection with API Server "10.151.30.57:6443"
This node has joined the cluster:
* Certificate signing request was sent to master and a response
was received.
* The Kubelet was informed of the new secure connection details.
Run 'kubectl get nodes' on the master to see this node join the cluster.
如果出现下面的错误信息:[discovery] Failed to request cluster info, will try again: [Get https://10.151.30.27:6443/api/v1/namespaces/kube-public/configmaps/cluster-info: x509: certificate has expired or is not yet valid],应该是 master 和 node 之间时间不同步造成的,执行 ntp 时间同步后,重新 init、join 即可。
如果 join 的时候出现下面的错误信息:[ERROR CRI]: unable to check if the container runtime at "/var/run/dockershim.sock" is running: fork/exec /usr/bin/crictl -r /var/run/dockershim.sock info: no such file or directory,这个是因为 cri-tools 版本造成的错误,可以卸载掉即可:yum remove cri-tools。
我们可以看到该节点已经加入到集群中去了,然后我们把 master 节点的~/.kube/config文件拷贝到当前节点对应的位置即可使用 kubectl 命令行工具了。
$ kubectl get nodes
NAME STATUS ROLES AGE VERSION
evjfaxic Ready <none> 1h v1.10.0
ydzs-master1 Ready master 3h v1.10.0
到这里就算我们的集群部署成功了,接下来就可以根据我们的需要安装一些附加的插件,比如 Dashboard、Heapster、Ingress-Controller 等等,这些插件的安装方法就和我们之前手动安装集群的方式方法一样了,这里就不在重复了,有问题可以在github上留言讨论。