
Python(库)Libraries
请求 - Python请求模块
Requests是一个Python模块,它是一个优雅而简单的Python HTTP库。 有了它,您可以发送各种HTTP请求。 使用此库,我们可以添加标题,表单数据,多部分文件和参数,并访问响应数据。
由于请求不是内置模块,因此我们需要先安装它。
您可以通过在终端中运行以下命令来安装它 -
pip install requests
安装模块后,可以通过在Python shell中键入以下命令来验证安装是否成功。
import requests
如果安装成功,您将看不到任何错误消息。
发出GET请求
作为一个例子,我们将使用“pokeapi”
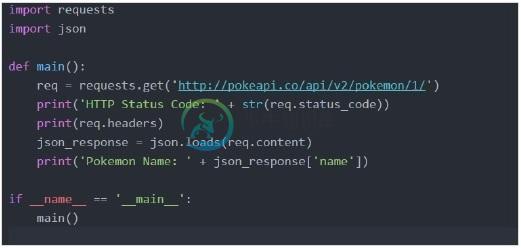
输出 -

发出POST请求
请求当前正在使用的所有HTTP谓词的库方法。 如果您想向API端点发出简单的POST请求,那么您可以这样做 -
req = requests.post(‘http://api/user’, data = None, json = None)
这将与我们之前的GET请求完全相同,但它有两个额外的关键字参数 -
数据可以填充在一个字典,一个文件或字节,将在我们的POST请求的HTTP正文中传递。
json,可以使用json对象填充,该对象也将在我们的HTTP请求的主体中传递。
熊猫:Python图书馆熊猫
Pandas是一个开源Python库,使用其强大的数据结构提供高性能数据操作和分析工具。 Pandas是数据科学中使用最广泛的Python库之一。 它主要用于数据调整,并有充分的理由:强大而灵活的功能组。
基于Numpy包,关键数据结构称为DataFrame。 这些数据框允许我们在观察行和变量列中存储和操作表格数据。
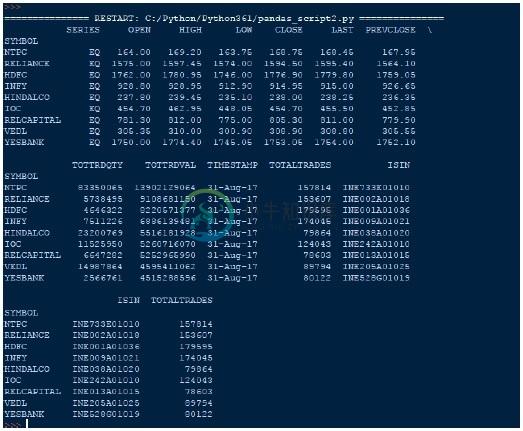
有几种方法可以创建DataFrame。 一种方法是使用字典。 例如 -
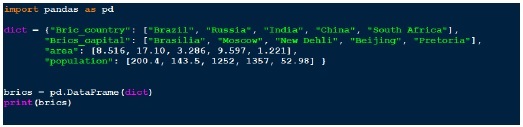
输出 (Output)
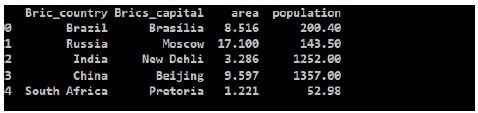
从输出中我们可以看到新的brics DataFrame,Pandas已经为每个国家分配了一个键作为数值0到4。
如果不是从0到4给出索引值,我们希望有不同的索引值,比如两个字母的国家代码,你也可以轻松地做到这一点 -
在上面的代码中添加以下一行,给出
brics.index = ['BR','RU','IN','CH','SA']
输出 (Output)

索引DataFrames
输出 (Output)
Pygame
Pygame是一个开源和跨平台的库,用于制作包括游戏在内的多媒体应用程序。 它包括计算机图形和声音库,旨在与Python编程语言一起使用。 你可以用Pygame开发很多很酷的游戏。
概述 Overview
Pygame由各种模块组成,每个模块都处理一组特定的任务。 例如,显示模块处理显示窗口和屏幕,绘图模块提供绘制形状的功能,键模块与键盘一起工作。 这些只是图书馆的一些模块。
Pygame图书馆的主页位于https://www.pygame.org/news
要制作Pygame应用程序,请按照以下步骤操作 -
导入Pygame库
import pygame
初始化Pygame库
pygame.init()
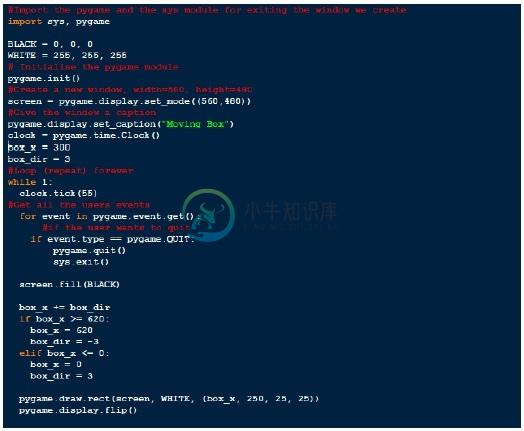
创建一个窗口。
screen = Pygame.display.set_mode((560,480))
Pygame.display.set_caption(‘First Pygame Game’)
Initialize game objects
在这一步中,我们加载图像,加载声音,进行对象定位,设置一些状态变量等。
Start the game loop.
它只是一个循环,我们不断处理事件,检查输入,移动对象,并绘制它们。 循环的每次迭代称为帧。
我们将以上所有逻辑放在一个程序下面,
Pygame_script.py
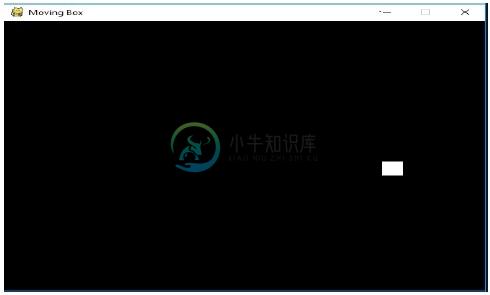
输出 (Output)
美丽的汤:网上刮美丽的汤
Web抓取背后的一般思想是获取网站上存在的数据,并将其转换为可用于分析的某种格式。
它是一个用于从HTML或XML文件中提取数据的Python库。 使用您最喜欢的解析器,它提供了导航,搜索和修改解析树的惯用方法。
由于BeautifulSoup不是内置库,我们需要在尝试使用它之前安装它。 要安装BeautifulSoup,请运行以下命令
$ apt-get install Python-bs4 # For Linux and Python2
$ apt-get install Python3-bs4 # for Linux based system and Python3.
$ easy_install beautifulsoup4 # For windows machine,
Or
$ pip instal beatifulsoup4 # For window machine
安装完成后,我们准备运行一些示例并详细探讨Beautifulsoup,
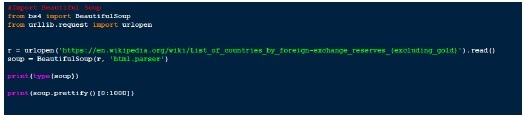
输出 (Output)
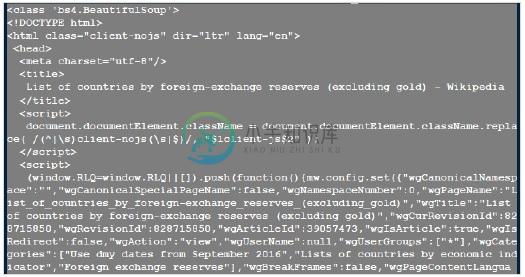
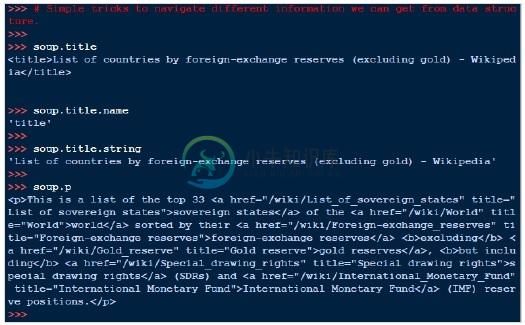
以下是一些导航该数据结构的简单方法 -
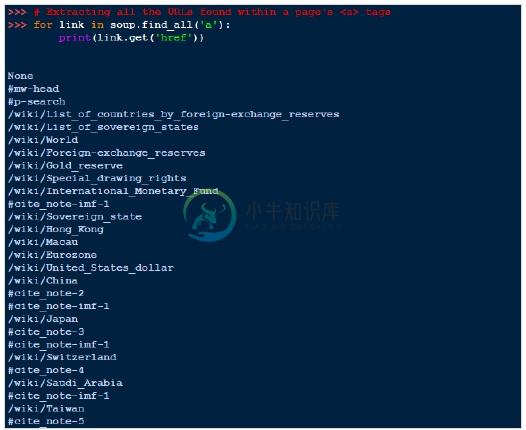
一个常见的任务是提取页面的标签中找到的所有网址 -
另一个常见任务是从页面中提取所有文本 -
